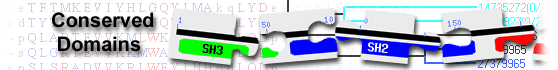isoprenoid biosynthesis enzyme family protein; bifunctional terpene synthase/polyprenyl synthetase family protein( domain architecture ID 10797185)
isoprenoid biosynthesis enzyme family protein; bifunctional terpene synthase/polyprenyl synthetase family protein contains a C-terminal prenyltransferase that catalyzes the formation of linear, all-trans, isoprenoids such as farnesyl diphosphate (FPP) and geranylgeranyl diphosphate (GGPP), and an N-terminal terpene synthase/cyclase that converts these isoprenoids into numerous cyclic forms of monoterpenes, diterpenes, and sesquiterpenes
farnesyl-diphosphate farnesyltransferase; This model describes farnesyl-diphosphate ...
38-370
0e+00
farnesyl-diphosphate farnesyltransferase; This model describes farnesyl-diphosphate farnesyltransferase, also known as squalene synthase, as found in eukaryotes. This family is related to phytoene synthases. Tentatively identified archaeal homologs (excluded from this model) lack the C-terminal predicted transmembrane region universally conserved among members of this family.
:
Pssm-ID: 188157 Cd Length: 337 Bit Score: 627.16 E-value: 0e+00
farnesyl-diphosphate farnesyltransferase; This model describes farnesyl-diphosphate ...
38-370
0e+00
farnesyl-diphosphate farnesyltransferase; This model describes farnesyl-diphosphate farnesyltransferase, also known as squalene synthase, as found in eukaryotes. This family is related to phytoene synthases. Tentatively identified archaeal homologs (excluded from this model) lack the C-terminal predicted transmembrane region universally conserved among members of this family.
Pssm-ID: 188157 Cd Length: 337 Bit Score: 627.16 E-value: 0e+00
Trans-Isoprenyl Diphosphate Synthases, head-to-head; These trans-Isoprenyl Diphosphate ...
41-321
3.91e-86
Trans-Isoprenyl Diphosphate Synthases, head-to-head; These trans-Isoprenyl Diphosphate Synthases (Trans_IPPS) catalyze a head-to-head (HH) (1'-1) condensation reaction. This CD includes squalene and phytoene synthases which catalyze the 1'-1 condensation of two 15-carbon (farnesyl) and 20-carbon (geranylgeranyl) isoprenyl diphosphates, respectively. The catalytic site consists of a large central cavity formed by mostly antiparallel alpha helices with two aspartate-rich regions (DXXXD) located on opposite walls. These residues mediate binding of prenyl phosphates. A two-step reaction has been proposed for squalene synthase (farnesyl-diphosphate farnesyltransferase) in which, two molecules of FPP react to form a stable cyclopropylcarbinyl diphosphate intermediate, and then the intermediate undergoes heterolysis, isomerization, and reduction with NADPH to form squalene, a precursor of cholestrol. The carotenoid biosynthesis enzyme, phytoene synthase (CrtB), catalyzes the condensation reaction of two molecules of geranylgeranyl diphosphate to produce phytoene, a precursor of beta-carotene. These enzymes produce the triterpene and tetraterpene precursors for many diverse sterol and carotenoid end products and are widely distributed among eukareya, bacteria, and archaea.
Pssm-ID: 173831 [Multi-domain] Cd Length: 265 Bit Score: 263.33 E-value: 3.91e-86
farnesyl-diphosphate farnesyltransferase; This model describes farnesyl-diphosphate ...
38-370
0e+00
farnesyl-diphosphate farnesyltransferase; This model describes farnesyl-diphosphate farnesyltransferase, also known as squalene synthase, as found in eukaryotes. This family is related to phytoene synthases. Tentatively identified archaeal homologs (excluded from this model) lack the C-terminal predicted transmembrane region universally conserved among members of this family.
Pssm-ID: 188157 Cd Length: 337 Bit Score: 627.16 E-value: 0e+00
Trans-Isoprenyl Diphosphate Synthases, head-to-head; These trans-Isoprenyl Diphosphate ...
41-321
3.91e-86
Trans-Isoprenyl Diphosphate Synthases, head-to-head; These trans-Isoprenyl Diphosphate Synthases (Trans_IPPS) catalyze a head-to-head (HH) (1'-1) condensation reaction. This CD includes squalene and phytoene synthases which catalyze the 1'-1 condensation of two 15-carbon (farnesyl) and 20-carbon (geranylgeranyl) isoprenyl diphosphates, respectively. The catalytic site consists of a large central cavity formed by mostly antiparallel alpha helices with two aspartate-rich regions (DXXXD) located on opposite walls. These residues mediate binding of prenyl phosphates. A two-step reaction has been proposed for squalene synthase (farnesyl-diphosphate farnesyltransferase) in which, two molecules of FPP react to form a stable cyclopropylcarbinyl diphosphate intermediate, and then the intermediate undergoes heterolysis, isomerization, and reduction with NADPH to form squalene, a precursor of cholestrol. The carotenoid biosynthesis enzyme, phytoene synthase (CrtB), catalyzes the condensation reaction of two molecules of geranylgeranyl diphosphate to produce phytoene, a precursor of beta-carotene. These enzymes produce the triterpene and tetraterpene precursors for many diverse sterol and carotenoid end products and are widely distributed among eukareya, bacteria, and archaea.
Pssm-ID: 173831 [Multi-domain] Cd Length: 265 Bit Score: 263.33 E-value: 3.91e-86
Trans-Isoprenyl Diphosphate Synthases; Trans-Isoprenyl Diphosphate Synthases (Trans_IPPS) of ...
64-263
4.66e-25
Trans-Isoprenyl Diphosphate Synthases; Trans-Isoprenyl Diphosphate Synthases (Trans_IPPS) of class 1 isoprenoid biosynthesis enzymes which either synthesis geranyl/farnesyl diphosphates (GPP/FPP) or longer chained products from isoprene precursors, isopentenyl diphosphate (IPP) and dimethylallyl diphosphate (DMAPP), or use geranyl (C10)-, farnesyl (C15)-, or geranylgeranyl (C20)-diphosphate as substrate. These enzymes produce a myriad of precursors for such end products as steroids, cholesterol, sesquiterpenes, heme, carotenoids, retinoids, diterpenes, ubiquinone, and archaeal ether linked lipids; and are widely distributed among archaea, bacteria, and eukareya. The enzymes in this family share the same 'isoprenoid synthase fold' and include the head-to-tail (HT) IPPS which catalyze the successive 1'-4 condensation of the 5-carbon IPP to the growing isoprene chain to form linear, all-trans, C10-, C15-, C20- C25-, C30-, C35-, C40-, C45-, or C50-isoprenoid diphosphates. The head-to-head (HH) IPPS catalyze the successive 1'-1 condensation of 2 farnesyl or 2 geranylgeranyl isoprenoid diphosphates. Isoprenoid chain elongation reactions proceed via electrophilic alkylations in which a new carbon-carbon single bond is generated through interaction between a highly reactive electron-deficient allylic carbocation and an electron-rich carbon-carbon double bond. The catalytic site consists of a large central cavity formed by mostly antiparallel alpha helices with two aspartate-rich regions located on opposite walls. These residues mediate binding of prenyl phosphates via bridging Mg2+ ions, inducing proposed conformational changes that close the active site to solvent, stabilizing reactive carbocation intermediates. Mechanistically and structurally distinct, cis-IPPS are not included in this CD.
Pssm-ID: 173836 Cd Length: 236 Bit Score: 102.42 E-value: 4.66e-25
Isoprenoid Biosynthesis enzymes, Class 1; Superfamily of trans-isoprenyl diphosphate synthases ...
53-298
2.85e-23
Isoprenoid Biosynthesis enzymes, Class 1; Superfamily of trans-isoprenyl diphosphate synthases (IPPS) and class I terpene cyclases which either synthesis geranyl/farnesyl diphosphates (GPP/FPP) or longer chained products from isoprene precursors, isopentenyl diphosphate (IPP) and dimethylallyl diphosphate (DMAPP), or use geranyl (C10)-, farnesyl (C15)-, or geranylgeranyl (C20)-diphosphate as substrate. These enzymes produce a myriad of precursors for such end products as steroids, cholesterol, sesquiterpenes, heme, carotenoids, retinoids, and diterpenes; and are widely distributed among archaea, bacteria, and eukaryota.The enzymes in this superfamily share the same 'isoprenoid synthase fold' and include several subgroups. The head-to-tail (HT) IPPS catalyze the successive 1'-4 condensation of the 5-carbon IPP to the growing isoprene chain to form linear, all-trans, C10-, C15-, C20- C25-, C30-, C35-, C40-, C45-, or C50-isoprenoid diphosphates. Cyclic monoterpenes, diterpenes, and sesquiterpenes, are formed from their respective linear isoprenoid diphosphates by class I terpene cyclases. The head-to-head (HH) IPPS catalyze the successive 1'-1 condensation of 2 farnesyl or 2 geranylgeranyl isoprenoid diphosphates. Cyclization of these 30- and 40-carbon linear forms are catalyzed by class II cyclases. Both the isoprenoid chain elongation reactions and the class I terpene cyclization reactions proceed via electrophilic alkylations in which a new carbon-carbon single bond is generated through interaction between a highly reactive electron-deficient allylic carbocation and an electron-rich carbon-carbon double bond. The catalytic site consists of a large central cavity formed by mostly antiparallel alpha helices with two aspartate-rich regions located on opposite walls. These residues mediate binding of prenyl phosphates via bridging Mg2+ ions, inducing proposed conformational changes that close the active site to solvent, stabilizing reactive carbocation intermediates. Generally, the enzymes in this family exhibit an all-trans reaction pathway, an exception, is the cis-trans terpene cyclase, trichodiene synthase. Mechanistically and structurally distinct, class II terpene cyclases and cis-IPPS are not included in this CD.
Pssm-ID: 173830 [Multi-domain] Cd Length: 243 Bit Score: 97.57 E-value: 2.85e-23
squalene synthase HpnD; The genes of this family are often found in the same genetic locus ...
164-239
1.69e-09
squalene synthase HpnD; The genes of this family are often found in the same genetic locus with squalene-hopene cyclase genes, and are never associated with genes for the metabolism of phytoene. In the organisms Zymomonas mobilis and Bradyrhizobium japonicum these genes have been characterized as squalene synthases (farnesyl-pyrophosphate ligases). Often, these genes appear in tandem with the HpnC gene which appears to have resulted from an ancient gene duplication event. Presumably these proteins form a heteromeric complex, but this has not yet been experimentally demonstrated.
Pssm-ID: 163278 Cd Length: 266 Bit Score: 58.06 E-value: 1.69e-09
Database: CDSEARCH/cdd Low complexity filter: no Composition Based Adjustment: yes E-value threshold: 0.01
References:
Wang J et al. (2023), "The conserved domain database in 2023", Nucleic Acids Res.51(D)384-8.
Lu S et al. (2020), "The conserved domain database in 2020", Nucleic Acids Res.48(D)265-8.
Marchler-Bauer A et al. (2017), "CDD/SPARCLE: functional classification of proteins via subfamily domain architectures.", Nucleic Acids Res.45(D)200-3.
of the residues that compose this conserved feature have been mapped to the query sequence.
Click on the triangle to view details about the feature, including a multiple sequence alignment
of your query sequence and the protein sequences used to curate the domain model,
where hash marks (#) above the aligned sequences show the location of the conserved feature residues.
The thumbnail image, if present, provides an approximate view of the feature's location in 3 dimensions.
Click on the triangle for interactive 3D structure viewing options.
Functional characterization of the conserved domain architecture found on the query.
Click here to see more details.
This image shows a graphical summary of conserved domains identified on the query sequence.
The Show Concise/Full Display button at the top of the page can be used to select the desired level of detail: only top scoring hits
(labeled illustration) or all hits
(labeled illustration).
Domains are color coded according to superfamilies
to which they have been assigned. Hits with scores that pass a domain-specific threshold
(specific hits) are drawn in bright colors.
Others (non-specific hits) and
superfamily placeholders are drawn in pastel colors.
if a domain or superfamily has been annotated with functional sites (conserved features),
they are mapped to the query sequence and indicated through sets of triangles
with the same color and shade of the domain or superfamily that provides the annotation. Mouse over the colored bars or triangles to see descriptions of the domains and features.
click on the bars or triangles to view your query sequence embedded in a multiple sequence alignment of the proteins used to develop the corresponding domain model.
The table lists conserved domains identified on the query sequence. Click on the plus sign (+) on the left to display full descriptions, alignments, and scores.
Click on the domain model's accession number to view the multiple sequence alignment of the proteins used to develop the corresponding domain model.
To view your query sequence embedded in that multiple sequence alignment, click on the colored bars in the Graphical Summary portion of the search results page,
or click on the triangles, if present, that represent functional sites (conserved features)
mapped to the query sequence.
Concise Display shows only the best scoring domain model, in each hit category listed below except non-specific hits, for each region on the query sequence.
(labeled illustration) Standard Display shows only the best scoring domain model from each source, in each hit category listed below for each region on the query sequence.
(labeled illustration) Full Display shows all domain models, in each hit category below, that meet or exceed the RPS-BLAST threshold for statistical significance.
(labeled illustration) Four types of hits can be shown, as available,
for each region on the query sequence:
specific hits meet or exceed a domain-specific e-value threshold
(illustrated example)
and represent a very high confidence that the query sequence belongs to the same protein family as the sequences use to create the domain model
non-specific hits
meet or exceed the RPS-BLAST threshold for statistical significance (default E-value cutoff of 0.01, or an E-value selected by user via the
advanced search options)
the domain superfamily to which the specific and non-specific hits belong
multi-domain models that were computationally detected and are likely to contain multiple single domains
Retrieve proteins that contain one or more of the domains present in the query sequence, using the Conserved Domain Architecture Retrieval Tool
(CDART).
Modify your query to search against a different database and/or use advanced search options