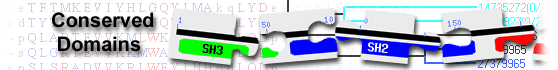alanine dehydrogenase catalyzes the NAD(+)-dependent oxidative deamination of L-alanine to pyruvate, and the reverse reaction, the reductive amination of pyruvate; alanine dehydrogenase catalyzes the reversible oxidative deamination of L-alanine to pyruvate
Alanine dehydrogenase (includes sporulation protein SpoVN) [Amino acid transport and ...
1-371
0e+00
Alanine dehydrogenase (includes sporulation protein SpoVN) [Amino acid transport and metabolism]; Alanine dehydrogenase (includes sporulation protein SpoVN) is part of the Pathway/BioSystem: Urea cycle
:
Pssm-ID: 440450 [Multi-domain] Cd Length: 372 Bit Score: 657.85 E-value: 0e+00
Alanine dehydrogenase (includes sporulation protein SpoVN) [Amino acid transport and ...
1-371
0e+00
Alanine dehydrogenase (includes sporulation protein SpoVN) [Amino acid transport and metabolism]; Alanine dehydrogenase (includes sporulation protein SpoVN) is part of the Pathway/BioSystem: Urea cycle
Pssm-ID: 440450 [Multi-domain] Cd Length: 372 Bit Score: 657.85 E-value: 0e+00
Alanine dehydrogenase NAD-binding and catalytic domains; Alanine dehydrogenase (L-AlaDH) ...
1-359
0e+00
Alanine dehydrogenase NAD-binding and catalytic domains; Alanine dehydrogenase (L-AlaDH) catalyzes the NAD-dependent conversion of pyruvate to L-alanine via reductive amination. Like formate dehydrogenase and related enzymes, L-AlaDH is comprised of 2 domains connected by a long alpha helical stretch, each resembling a Rossmann fold NAD-binding domain. The NAD-binding domain is inserted within the linear sequence of the more divergent catalytic domain. Ligand binding and active site residues are found in the cleft between the subdomains. L-AlaDH is typically hexameric and is critical in carbon and nitrogen metabolism in micro-organisms.
Pssm-ID: 240630 [Multi-domain] Cd Length: 359 Bit Score: 600.55 E-value: 0e+00
alanine dehydrogenase; The family of known L-alanine dehydrogenases (EC 1.4.1.1) includes ...
1-370
3.12e-151
alanine dehydrogenase; The family of known L-alanine dehydrogenases (EC 1.4.1.1) includes representatives from the Proteobacteria, Firmicutes, Cyanobacteria, and Actinobacteria, all with about 50 % identity or better. An outlier to this group in both sequence and gap pattern is the homolog from Helicobacter pylori, an epsilon division Proteobacteria, which must be considered a putative alanine dehydrogenase. In Mycobacterium smegmatis and M. tuberculosis, the enzyme doubles as a glycine dehydrogenase (1.4.1.10), running in the reverse direction (glyoxylate amination to glycine, with conversion of NADH to NAD+). Related proteins include saccharopine dehydrogenase and the N-terminal half of the NAD(P) transhydrogenase alpha subunit. All of these related proteins bind NAD and/or NADP. [Energy metabolism, Amino acids and amines]
Pssm-ID: 129609 [Multi-domain] Cd Length: 370 Bit Score: 431.26 E-value: 3.12e-151
Alanine dehydrogenase (includes sporulation protein SpoVN) [Amino acid transport and ...
1-371
0e+00
Alanine dehydrogenase (includes sporulation protein SpoVN) [Amino acid transport and metabolism]; Alanine dehydrogenase (includes sporulation protein SpoVN) is part of the Pathway/BioSystem: Urea cycle
Pssm-ID: 440450 [Multi-domain] Cd Length: 372 Bit Score: 657.85 E-value: 0e+00
Alanine dehydrogenase NAD-binding and catalytic domains; Alanine dehydrogenase (L-AlaDH) ...
1-359
0e+00
Alanine dehydrogenase NAD-binding and catalytic domains; Alanine dehydrogenase (L-AlaDH) catalyzes the NAD-dependent conversion of pyruvate to L-alanine via reductive amination. Like formate dehydrogenase and related enzymes, L-AlaDH is comprised of 2 domains connected by a long alpha helical stretch, each resembling a Rossmann fold NAD-binding domain. The NAD-binding domain is inserted within the linear sequence of the more divergent catalytic domain. Ligand binding and active site residues are found in the cleft between the subdomains. L-AlaDH is typically hexameric and is critical in carbon and nitrogen metabolism in micro-organisms.
Pssm-ID: 240630 [Multi-domain] Cd Length: 359 Bit Score: 600.55 E-value: 0e+00
alanine dehydrogenase; The family of known L-alanine dehydrogenases (EC 1.4.1.1) includes ...
1-370
3.12e-151
alanine dehydrogenase; The family of known L-alanine dehydrogenases (EC 1.4.1.1) includes representatives from the Proteobacteria, Firmicutes, Cyanobacteria, and Actinobacteria, all with about 50 % identity or better. An outlier to this group in both sequence and gap pattern is the homolog from Helicobacter pylori, an epsilon division Proteobacteria, which must be considered a putative alanine dehydrogenase. In Mycobacterium smegmatis and M. tuberculosis, the enzyme doubles as a glycine dehydrogenase (1.4.1.10), running in the reverse direction (glyoxylate amination to glycine, with conversion of NADH to NAD+). Related proteins include saccharopine dehydrogenase and the N-terminal half of the NAD(P) transhydrogenase alpha subunit. All of these related proteins bind NAD and/or NADP. [Energy metabolism, Amino acids and amines]
Pssm-ID: 129609 [Multi-domain] Cd Length: 370 Bit Score: 431.26 E-value: 3.12e-151
Alanine dehydrogenase and related dehydrogenases; Alanine dehydrogenase/Transhydrogenase, such ...
3-325
7.83e-97
Alanine dehydrogenase and related dehydrogenases; Alanine dehydrogenase/Transhydrogenase, such as the hexameric L-alanine dehydrogenase of Phormidium lapideum, contain 2 Rossmann fold-like domains linked by an alpha helical region. Related proteins include Saccharopine Dehydrogenase (SDH), bifunctional lysine ketoglutarate reductase /saccharopine dehydrogenase enzyme, N(5)-(carboxyethyl)ornithine synthase, and Rubrum transdehydrogenase. Alanine dehydrogenase (L-AlaDH) catalyzes the NAD-dependent conversion of pyrucate to L-alanine via reductive amination. Transhydrogenases found in bacterial and inner mitochondrial membranes link NAD(P)(H)-dependent redox reactions to proton translocation. The energy of the proton electrochemical gradient (delta-p), generated by the respiratory electron transport chain, is consumed by transhydrogenase in NAD(P)+ reduction. Transhydrogenase is likely involved in the regulation of the citric acid cycle. Rubrum transhydrogenase has 3 components, dI, dII, and dIII. dII spans the membrane while dI and dIII protrude on the cytoplasmic/matirx side. DI contains 2 domains with Rossmann folds, linked by a long alpha helix, and contains a NAD binding site. Two dI polypeptides (represented in this sub-family) spontaneously form a heterotrimer with one dIII in the absence of dII. In the heterotrimer, both dI chains may bind NAD, but only one is well-ordered. dIII also binds a well-ordered NADP, but in a different orientation than classical Rossmann domains.
Pssm-ID: 240621 [Multi-domain] Cd Length: 317 Bit Score: 290.85 E-value: 7.83e-97
Rubrum transdehydrogenase NAD-binding and catalytic domains; Transhydrogenases found in ...
1-310
2.83e-47
Rubrum transdehydrogenase NAD-binding and catalytic domains; Transhydrogenases found in bacterial and inner mitochondrial membranes link NAD(P)(H)-dependent redox reactions to proton translocation. The energy of the proton electrochemical gradient (delta-p), generated by the respiratory electron transport chain, is consumed by transhydrogenase in NAD(P)+ reduction. Transhydrogenase is likely involved in the regulation of the citric acid cycle. Rubrum transhydrogenase has 3 components, dI, dII, and dIII. dII spans the membrane while dI and dIII protrude on the cytoplasmic/matrix side. DI contains 2 domains in Rossmann-like folds, linked by a long alpha helix, and contains a NAD binding site. Two dI polypeptides (represented in this sub-family) spontaneously form a heterotrimer with dIII in the absence of dII. In the heterotrimer, both dI chains may bind NAD, but only one is well-ordered. dIII also binds a well-ordered NADP, but in a different orientation than a classical Rossmann domain.
Pssm-ID: 240629 [Multi-domain] Cd Length: 363 Bit Score: 164.12 E-value: 2.83e-47
Formate/glycerate dehydrogenases, D-specific 2-hydroxy acid dehydrogenases and related ...
3-324
1.49e-44
Formate/glycerate dehydrogenases, D-specific 2-hydroxy acid dehydrogenases and related dehydrogenases; The formate/glycerate dehydrogenase like family contains a diverse group of enzymes such as formate dehydrogenase (FDH), glycerate dehydrogenase (GDH), D-lactate dehydrogenase, L-alanine dehydrogenase, and S-Adenosylhomocysteine hydrolase, that share a common 2-domain structure. Despite often low sequence identity, these proteins typically have a characteristic arrangement of 2 similar domains of the alpha/beta Rossmann fold NAD+ binding form. The NAD(P) binding domain is inserted within the linear sequence of the mostly N-terminal catalytic domain. Structurally, these domains are connected by extended alpha helices and create a cleft in which NAD(P) is bound, primarily to the C-terminal portion of the 2nd (internal) domain. While many members of this family are dimeric, alanine DH is hexameric and phosphoglycerate DH is tetrameric. 2-hydroxyacid dehydrogenases are enzymes that catalyze the conversion of a wide variety of D-2-hydroxy acids to their corresponding keto acids. The general mechanism is (R)-lactate + acceptor to pyruvate + reduced acceptor. Formate dehydrogenase (FDH) catalyzes the NAD+-dependent oxidation of formate ion to carbon dioxide with the concomitant reduction of NAD+ to NADH. FDHs of this family contain no metal ions or prosthetic groups. Catalysis occurs though direct transfer of a hydride ion to NAD+ without the stages of acid-base catalysis typically found in related dehydrogenases.
Pssm-ID: 240631 [Multi-domain] Cd Length: 310 Bit Score: 155.85 E-value: 1.49e-44
N(5)-(carboxyethyl)ornithine synthase; N(5)-(carboxyethyl)ornithine synthase (ceo_syn) catalyzes the NADP-dependent conversion of N5-(L-1-carboxyethyl)-L-ornithine to L-ornithine + pyruvate. Ornithine plays a key role in the urea cycle, which in mammals is used in arginine biosynthesis, and is a precursor in polyamine synthesis. ceo_syn is related to the NAD-dependent L-alanine dehydrogenases. Like formate dehydrogenase and related enzymes, ceo_syn is comprised of 2 domains connected by a long alpha helical stretch, each resembling a Rossmann fold NAD-binding domain. The NAD-binding domain is inserted within the linear sequence of the more divergent catalytic domain. These ceo_syn proteins have a partially conserved NAD-binding motif and active site residues that are characteristic of related enzymes such as Saccharopine Dehydrogenase.
Pssm-ID: 240658 [Multi-domain] Cd Length: 295 Bit Score: 137.36 E-value: 1.03e-37
Saccharopine Dehydrogenase like proteins; Saccharopine Dehydrogenase (SDH) and related ...
3-322
4.76e-08
Saccharopine Dehydrogenase like proteins; Saccharopine Dehydrogenase (SDH) and related proteins, including bifunctional lysine ketoglutarate reductase/SDH enzymes and N(5)-(carboxyethyl)ornithine synthases. SDH catalyzes the final step in the reversible NAD-dependent oxidative deamination of saccharopine to alpha-ketoglutarate and lysine, in the alpha-aminoadipate pathway of L-lysine biosynthesis. SDH is structurally related to formate dehydrogenase and similar enzymes, having a 2-domain structure in which a Rossmann-fold NAD(P)-binding domain is inserted within the linear sequence of a catalytic domain of related structure. Bifunctional lysine ketoglutarate reductase/SDH protein is a pair of enzymes linked on a single polypeptide chain that catalyze the initial, consecutive steps of lysine degradation. These proteins are related to the 2-domain saccharopine dehydrogenases.
Pssm-ID: 240623 [Multi-domain] Cd Length: 319 Bit Score: 54.16 E-value: 4.76e-08
bifunctional lysine ketoglutarate reductase /saccharopine dehydrogenase enzyme; Bifunctional lysine ketoglutarate reductase /saccharopine dehydrogenase protein is a pair of enzymes linked on a single polypeptide chain that catalyze the initial, consecutive steps of lysine degradation. These proteins are related to the 2-domain saccharopine dehydrogenases. Along with formate dehydrogenase and similar enzymes, SDH consists paired domains resembling Rossmann folds in which the NAD-binding domain is inserted within the linear sequence of the catalytic domain. In this bifunctional enzyme, the LKR domain is N-terminal of the SDH domain. These proteins have a close match to the active site motif of SDHs, and an NAD-binding site motif that is a partial match to that found in SDH and other FDH-related proteins.
Pssm-ID: 240665 [Multi-domain] Cd Length: 433 Bit Score: 48.32 E-value: 4.61e-06
Database: CDSEARCH/cdd Low complexity filter: no Composition Based Adjustment: yes E-value threshold: 0.01
References:
Wang J et al. (2023), "The conserved domain database in 2023", Nucleic Acids Res.51(D)384-8.
Lu S et al. (2020), "The conserved domain database in 2020", Nucleic Acids Res.48(D)265-8.
Marchler-Bauer A et al. (2017), "CDD/SPARCLE: functional classification of proteins via subfamily domain architectures.", Nucleic Acids Res.45(D)200-3.
of the residues that compose this conserved feature have been mapped to the query sequence.
Click on the triangle to view details about the feature, including a multiple sequence alignment
of your query sequence and the protein sequences used to curate the domain model,
where hash marks (#) above the aligned sequences show the location of the conserved feature residues.
The thumbnail image, if present, provides an approximate view of the feature's location in 3 dimensions.
Click on the triangle for interactive 3D structure viewing options.
Functional characterization of the conserved domain architecture found on the query.
Click here to see more details.
This image shows a graphical summary of conserved domains identified on the query sequence.
The Show Concise/Full Display button at the top of the page can be used to select the desired level of detail: only top scoring hits
(labeled illustration) or all hits
(labeled illustration).
Domains are color coded according to superfamilies
to which they have been assigned. Hits with scores that pass a domain-specific threshold
(specific hits) are drawn in bright colors.
Others (non-specific hits) and
superfamily placeholders are drawn in pastel colors.
if a domain or superfamily has been annotated with functional sites (conserved features),
they are mapped to the query sequence and indicated through sets of triangles
with the same color and shade of the domain or superfamily that provides the annotation. Mouse over the colored bars or triangles to see descriptions of the domains and features.
click on the bars or triangles to view your query sequence embedded in a multiple sequence alignment of the proteins used to develop the corresponding domain model.
The table lists conserved domains identified on the query sequence. Click on the plus sign (+) on the left to display full descriptions, alignments, and scores.
Click on the domain model's accession number to view the multiple sequence alignment of the proteins used to develop the corresponding domain model.
To view your query sequence embedded in that multiple sequence alignment, click on the colored bars in the Graphical Summary portion of the search results page,
or click on the triangles, if present, that represent functional sites (conserved features)
mapped to the query sequence.
Concise Display shows only the best scoring domain model, in each hit category listed below except non-specific hits, for each region on the query sequence.
(labeled illustration) Standard Display shows only the best scoring domain model from each source, in each hit category listed below for each region on the query sequence.
(labeled illustration) Full Display shows all domain models, in each hit category below, that meet or exceed the RPS-BLAST threshold for statistical significance.
(labeled illustration) Four types of hits can be shown, as available,
for each region on the query sequence:
specific hits meet or exceed a domain-specific e-value threshold
(illustrated example)
and represent a very high confidence that the query sequence belongs to the same protein family as the sequences use to create the domain model
non-specific hits
meet or exceed the RPS-BLAST threshold for statistical significance (default E-value cutoff of 0.01, or an E-value selected by user via the
advanced search options)
the domain superfamily to which the specific and non-specific hits belong
multi-domain models that were computationally detected and are likely to contain multiple single domains
Retrieve proteins that contain one or more of the domains present in the query sequence, using the Conserved Domain Architecture Retrieval Tool
(CDART).
Modify your query to search against a different database and/or use advanced search options