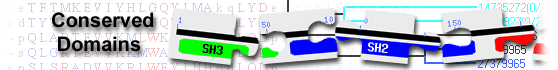


homer protein homolog 2 isoform X5 [Homo sapiens]
Protein Classification

Homer/Vesl family EVH1 domain-containing protein( domain architecture ID 10100433)
Homer/Vesl family EVH1 (WH1, RanBP1-WASP) domain-containing protein is a synaptic scaffolding protein, required for long-term potentiation, a form of synaptic plasticity thought to underlie memory formation
List of domain hits
| Name | Accession | Description | Interval | E-value | |||||
| EVH1_Homer_Vesl | cd01206 | Homer/Vesl family proteins EVH1 domain; Homer/Vesl proteins are synaptic scaffolding proteins, ... |
13-121 | 2.21e-77 | |||||
Homer/Vesl family proteins EVH1 domain; Homer/Vesl proteins are synaptic scaffolding proteins, required for long-term potentiation, a form of synaptic plasticity thought to underlie memory formation. They contains an N-terminal EVH1 domain and bind to both neurotransmitter receptors, such as the metabotropic group 1 glutamate receptor (mGluR) and to other scaffolding proteins via PPXXF motifs, in order to target them to the synaptic junction. These mGluRs possess a long C-terminal intracellular tail that may be important for subcellular localization of the receptor. The C-terminus is also the site of binding by the immediate early gene (IEG), Homer 1a. In contrast to Homer 1a, other Homer members additionally encode a C-terminal coiled-coil (CC) domain and form multivalent complexes that bind group 1 mGluRs. Homer 1a competes with constitutively expressed CC-Homers to modify the association of group 1 mGluRs with CC-Homer complexes. Since Homer proteins are strikingly enriched at the postsynaptic density (PSD), these observations suggest a role for the Homer family in regulating synaptic metabotropic receptor function. PSD-Zip45 (also named Homer 1c/Vesl-1L) has an EVH1 domain with a longer alpha-helix and its linking part included in the conserved region of Homer 1 (CRH1) interacts with the EVH1 domain of the neighbour CRH1 molecule in the crystal, suggesting that the EVH1 domain recognizes the PPXXF motif found in the binding partners, and the SPLTP sequence (P-motif) in the linking region of the CRH1. The two types of binding are partly overlapped in the EVH1 domain, implying a mechanism to regulate multimerization of Homer 1 family proteins. Homer 2 and Homer 3 are negative regulators of T cell activation. They bind the nuclear factor of activated T cells (NFAT) and compete with calcineurin binding. NFAT plays a critical role in calcium-dependent signaling in other cell types, including muscle and neurons. Homer-NFAT binding is also antagonized by active serine-threonine kinase AKT, enhancing TCR signaling via calcineurin-dependent dephosphorylation of NFAT resulting in changes in cytokine expression and an increase in effector-memory T cell populations in Homer-deficient mice. The EVH1 domains are part of the PH domain superamily. There are 5 EVH1 subfamilies: Enables/VASP, Homer/Vesl, WASP, Dcp1, and Spred. Ligands are known for three of the EVH1 subfamilies, all of which bind proline-rich sequences: the Enabled/VASP family binds to FPPPP peptides, the Homer/Vesl family binds PPxxF peptides, and the WASP family binds LPPPEP peptides. EVH1 has a PH-like fold, despite having minimal sequence similarity to PH or PTB domains. : Pssm-ID: 269917 Cd Length: 109 Bit Score: 233.01 E-value: 2.21e-77
|
|||||||||
| SMC_prok_B super family | cl37069 | chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
103-332 | 2.21e-08 | |||||
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins] The actual alignment was detected with superfamily member TIGR02168: Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 55.83 E-value: 2.21e-08
|
|||||||||
| Name | Accession | Description | Interval | E-value | |||||
| EVH1_Homer_Vesl | cd01206 | Homer/Vesl family proteins EVH1 domain; Homer/Vesl proteins are synaptic scaffolding proteins, ... |
13-121 | 2.21e-77 | |||||
Homer/Vesl family proteins EVH1 domain; Homer/Vesl proteins are synaptic scaffolding proteins, required for long-term potentiation, a form of synaptic plasticity thought to underlie memory formation. They contains an N-terminal EVH1 domain and bind to both neurotransmitter receptors, such as the metabotropic group 1 glutamate receptor (mGluR) and to other scaffolding proteins via PPXXF motifs, in order to target them to the synaptic junction. These mGluRs possess a long C-terminal intracellular tail that may be important for subcellular localization of the receptor. The C-terminus is also the site of binding by the immediate early gene (IEG), Homer 1a. In contrast to Homer 1a, other Homer members additionally encode a C-terminal coiled-coil (CC) domain and form multivalent complexes that bind group 1 mGluRs. Homer 1a competes with constitutively expressed CC-Homers to modify the association of group 1 mGluRs with CC-Homer complexes. Since Homer proteins are strikingly enriched at the postsynaptic density (PSD), these observations suggest a role for the Homer family in regulating synaptic metabotropic receptor function. PSD-Zip45 (also named Homer 1c/Vesl-1L) has an EVH1 domain with a longer alpha-helix and its linking part included in the conserved region of Homer 1 (CRH1) interacts with the EVH1 domain of the neighbour CRH1 molecule in the crystal, suggesting that the EVH1 domain recognizes the PPXXF motif found in the binding partners, and the SPLTP sequence (P-motif) in the linking region of the CRH1. The two types of binding are partly overlapped in the EVH1 domain, implying a mechanism to regulate multimerization of Homer 1 family proteins. Homer 2 and Homer 3 are negative regulators of T cell activation. They bind the nuclear factor of activated T cells (NFAT) and compete with calcineurin binding. NFAT plays a critical role in calcium-dependent signaling in other cell types, including muscle and neurons. Homer-NFAT binding is also antagonized by active serine-threonine kinase AKT, enhancing TCR signaling via calcineurin-dependent dephosphorylation of NFAT resulting in changes in cytokine expression and an increase in effector-memory T cell populations in Homer-deficient mice. The EVH1 domains are part of the PH domain superamily. There are 5 EVH1 subfamilies: Enables/VASP, Homer/Vesl, WASP, Dcp1, and Spred. Ligands are known for three of the EVH1 subfamilies, all of which bind proline-rich sequences: the Enabled/VASP family binds to FPPPP peptides, the Homer/Vesl family binds PPxxF peptides, and the WASP family binds LPPPEP peptides. EVH1 has a PH-like fold, despite having minimal sequence similarity to PH or PTB domains. Pssm-ID: 269917 Cd Length: 109 Bit Score: 233.01 E-value: 2.21e-77
|
|||||||||
| WH1 | pfam00568 | WH1 domain; WASp Homology domain 1 (WH1) domain. WASP is the protein that is defective in ... |
14-117 | 5.86e-40 | |||||
WH1 domain; WASp Homology domain 1 (WH1) domain. WASP is the protein that is defective in Wiskott-Aldrich syndrome (WAS). The majority of point mutations occur within the amino- terminal WH1 domain. The metabotropic glutamate receptors mGluR1alpha and mGluR5 bind a protein called homer, which is a WH1 domain homolog. A subset of WH1 domains has been termed a "EVH1" domain and appear to bind a polyproline motif. Pssm-ID: 395450 Cd Length: 111 Bit Score: 136.81 E-value: 5.86e-40
|
|||||||||
| WH1 | smart00461 | WASP homology region 1; Region of the Wiskott-Aldrich syndrome protein (WASp) that contains ... |
11-115 | 1.04e-27 | |||||
WASP homology region 1; Region of the Wiskott-Aldrich syndrome protein (WASp) that contains point mutations in the majority of patients with WAS. Unknown function. Ena-like WH1 domains bind polyproline-containing peptides, and that Homer contains a WH1 domain. Pssm-ID: 214674 Cd Length: 106 Bit Score: 104.36 E-value: 1.04e-27
|
|||||||||
| SMC_prok_B | TIGR02168 | chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
103-332 | 2.21e-08 | |||||
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins] Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 55.83 E-value: 2.21e-08
|
|||||||||
| Smc | COG1196 | Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
161-339 | 8.11e-07 | |||||
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 51.09 E-value: 8.11e-07
|
|||||||||
| PRK02224 | PRK02224 | DNA double-strand break repair Rad50 ATPase; |
111-313 | 3.11e-05 | |||||
DNA double-strand break repair Rad50 ATPase; Pssm-ID: 179385 [Multi-domain] Cd Length: 880 Bit Score: 45.80 E-value: 3.11e-05
|
|||||||||
| Cast | pfam10174 | RIM-binding protein of the cytomatrix active zone; This is a family of proteins that form part ... |
161-313 | 7.34e-05 | |||||
RIM-binding protein of the cytomatrix active zone; This is a family of proteins that form part of the CAZ (cytomatrix at the active zone) complex which is involved in determining the site of synaptic vesicle fusion. The C-terminus is a PDZ-binding motif that binds directly to RIM (a small G protein Rab-3A effector). The family also contains four coiled-coil domains. Pssm-ID: 431111 [Multi-domain] Cd Length: 766 Bit Score: 44.81 E-value: 7.34e-05
|
|||||||||
| INSC_LBD | cd21966 | LGN-binding domain (LBD) of protein Inscuteable (INSC) and similar proteins; Inscuteable (INSC) ... |
179-339 | 6.03e-03 | |||||
LGN-binding domain (LBD) of protein Inscuteable (INSC) and similar proteins; Inscuteable (INSC) functions as an adapter protein linking the Par polarity complex (composed of Par3, Par6 and protein kinase C iota) to the Gpsm1/Gpsm2 complex, and is involved in cell polarity and spindle orientation during mitosis. Par3 interacts with INSC which binds directly to Pins (partner of Insc, homolog of vertebrate LGN/Gpsm2 and AGS3/Gpsm1). Pins then associates with the heterotrimeric G proteins and NuMA, which interacts directly with the cell spindle to control the orientation of the spindle and the division plane of mitotic cells. INSC may regulate cell proliferation and differentiation in the developing nervous system, may play a role in the asymmetric division of fibroblasts, and may also participate in the process of stratification of the squamous epithelium. This model corresponds to the Leu-Gly-Asn Repeat-Enriched Protein (LGN)-binding domain (LBD) of INSC. It interacts with the tetratricopeptide repeat (TPR) motifs of LGN, also called G-protein-signaling modulator 2 (Gpsm2). Pssm-ID: 439320 [Multi-domain] Cd Length: 300 Bit Score: 38.01 E-value: 6.03e-03
|
|||||||||
| Name | Accession | Description | Interval | E-value | |||||
| EVH1_Homer_Vesl | cd01206 | Homer/Vesl family proteins EVH1 domain; Homer/Vesl proteins are synaptic scaffolding proteins, ... |
13-121 | 2.21e-77 | |||||
Homer/Vesl family proteins EVH1 domain; Homer/Vesl proteins are synaptic scaffolding proteins, required for long-term potentiation, a form of synaptic plasticity thought to underlie memory formation. They contains an N-terminal EVH1 domain and bind to both neurotransmitter receptors, such as the metabotropic group 1 glutamate receptor (mGluR) and to other scaffolding proteins via PPXXF motifs, in order to target them to the synaptic junction. These mGluRs possess a long C-terminal intracellular tail that may be important for subcellular localization of the receptor. The C-terminus is also the site of binding by the immediate early gene (IEG), Homer 1a. In contrast to Homer 1a, other Homer members additionally encode a C-terminal coiled-coil (CC) domain and form multivalent complexes that bind group 1 mGluRs. Homer 1a competes with constitutively expressed CC-Homers to modify the association of group 1 mGluRs with CC-Homer complexes. Since Homer proteins are strikingly enriched at the postsynaptic density (PSD), these observations suggest a role for the Homer family in regulating synaptic metabotropic receptor function. PSD-Zip45 (also named Homer 1c/Vesl-1L) has an EVH1 domain with a longer alpha-helix and its linking part included in the conserved region of Homer 1 (CRH1) interacts with the EVH1 domain of the neighbour CRH1 molecule in the crystal, suggesting that the EVH1 domain recognizes the PPXXF motif found in the binding partners, and the SPLTP sequence (P-motif) in the linking region of the CRH1. The two types of binding are partly overlapped in the EVH1 domain, implying a mechanism to regulate multimerization of Homer 1 family proteins. Homer 2 and Homer 3 are negative regulators of T cell activation. They bind the nuclear factor of activated T cells (NFAT) and compete with calcineurin binding. NFAT plays a critical role in calcium-dependent signaling in other cell types, including muscle and neurons. Homer-NFAT binding is also antagonized by active serine-threonine kinase AKT, enhancing TCR signaling via calcineurin-dependent dephosphorylation of NFAT resulting in changes in cytokine expression and an increase in effector-memory T cell populations in Homer-deficient mice. The EVH1 domains are part of the PH domain superamily. There are 5 EVH1 subfamilies: Enables/VASP, Homer/Vesl, WASP, Dcp1, and Spred. Ligands are known for three of the EVH1 subfamilies, all of which bind proline-rich sequences: the Enabled/VASP family binds to FPPPP peptides, the Homer/Vesl family binds PPxxF peptides, and the WASP family binds LPPPEP peptides. EVH1 has a PH-like fold, despite having minimal sequence similarity to PH or PTB domains. Pssm-ID: 269917 Cd Length: 109 Bit Score: 233.01 E-value: 2.21e-77
|
|||||||||
| EVH1_family | cd00837 | EVH1 (Drosophila Enabled (Ena)/Vasodilator-stimulated phosphoprotein (VASP) homology 1) domain; ... |
15-117 | 3.61e-42 | |||||
EVH1 (Drosophila Enabled (Ena)/Vasodilator-stimulated phosphoprotein (VASP) homology 1) domain; The EVH1 domains are part of the PH domain superfamily. EVH1 subfamilies include Enables/VASP, Homer/Vesl, WASP, and Spred. Ligands are known for three of the EVH1 subfamilies, all of which bind proline-rich sequences: the Enabled/VASP family binds to FPPPP peptides, the Homer/Vesl family binds PPxxF peptides, and the WASP family binds LPPPEP peptides. EVH1 has a PH-like fold, despite having minimal sequence similarity to PH or PTB domains. Pssm-ID: 269909 Cd Length: 103 Bit Score: 142.22 E-value: 3.61e-42
|
|||||||||
| WH1 | pfam00568 | WH1 domain; WASp Homology domain 1 (WH1) domain. WASP is the protein that is defective in ... |
14-117 | 5.86e-40 | |||||
WH1 domain; WASp Homology domain 1 (WH1) domain. WASP is the protein that is defective in Wiskott-Aldrich syndrome (WAS). The majority of point mutations occur within the amino- terminal WH1 domain. The metabotropic glutamate receptors mGluR1alpha and mGluR5 bind a protein called homer, which is a WH1 domain homolog. A subset of WH1 domains has been termed a "EVH1" domain and appear to bind a polyproline motif. Pssm-ID: 395450 Cd Length: 111 Bit Score: 136.81 E-value: 5.86e-40
|
|||||||||
| WH1 | smart00461 | WASP homology region 1; Region of the Wiskott-Aldrich syndrome protein (WASp) that contains ... |
11-115 | 1.04e-27 | |||||
WASP homology region 1; Region of the Wiskott-Aldrich syndrome protein (WASp) that contains point mutations in the majority of patients with WAS. Unknown function. Ena-like WH1 domains bind polyproline-containing peptides, and that Homer contains a WH1 domain. Pssm-ID: 214674 Cd Length: 106 Bit Score: 104.36 E-value: 1.04e-27
|
|||||||||
| EVH1_Ena_VASP-like | cd01207 | Enabled/VASP family EVH1 domain; Ena/VASP family includes proteins such as: ... |
15-110 | 2.76e-12 | |||||
Enabled/VASP family EVH1 domain; Ena/VASP family includes proteins such as: Vasodilator-stimulated phosphoprotein (VASP), enabled gene product from Drosophila (Ena), mammalian enabled (Mena) and Ena/VASP-Like protein (EVL) localize to focal adhesions and to sites of actin filament dynamics. These proteins share a common modular organization with a highly conserved N- and C-terminal domains, termed Ena/VASP homology domains 1 and 2 (EVH1 and EVH2), that are separated by a central proline-rich domain. The EVH1 domain binds to other proteins at proline rich sequences. The majority of Ena-VASP type EVH1 domains recognize FPPPP motifs such as in the focal adhesion proteins zyxin and vinculin, and the ActA surface protein of Listeria monocytogenes, however the LIM3 domain of Tes lacks the FPPPP motif but still binds the EVH1 domain of Mena. It has a PH-like fold, despite having minimal sequence similarity to PH or PTB domains. EVH2 mediates oligomerization within the family. The proline-rich region binds SH3 and WW domains as well as profilin, a protein that regulates actin filament dynamics. The EVH1 domains are part of the PH domain superamily. There are 5 EVH1 subfamilies: Enables/VASP, Homer/Vesl, WASP, Dcp1, and Spred. Ligands are known for three of the EVH1 subfamilies, all of which bind proline-rich sequences: the Enabled/VASP family binds to FPPPP peptides, the Homer/Vesl family binds PPxxF peptides, and the WASP family binds LPPPEP peptides. EVH1 has a PH-like fold, despite having minimal sequence similarity to PH or PTB domains. Pssm-ID: 269918 Cd Length: 108 Bit Score: 62.71 E-value: 2.76e-12
|
|||||||||
| SMC_prok_B | TIGR02168 | chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
103-332 | 2.21e-08 | |||||
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins] Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 55.83 E-value: 2.21e-08
|
|||||||||
| SMC_prok_B | TIGR02168 | chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
162-326 | 6.42e-08 | |||||
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins] Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 54.29 E-value: 6.42e-08
|
|||||||||
| SMC_prok_A | TIGR02169 | chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
110-325 | 2.00e-07 | |||||
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins] Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 52.76 E-value: 2.00e-07
|
|||||||||
| SMC_prok_B | TIGR02168 | chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
161-352 | 4.37e-07 | |||||
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins] Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 51.98 E-value: 4.37e-07
|
|||||||||
| SMC_prok_A | TIGR02169 | chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
104-333 | 7.53e-07 | |||||
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins] Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 51.22 E-value: 7.53e-07
|
|||||||||
| SMC_prok_A | TIGR02169 | chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
185-350 | 7.86e-07 | |||||
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins] Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 50.84 E-value: 7.86e-07
|
|||||||||
| Smc | COG1196 | Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
161-339 | 8.11e-07 | |||||
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 51.09 E-value: 8.11e-07
|
|||||||||
| COG2433 | COG2433 | Possible nuclease of RNase H fold, RuvC/YqgF family [General function prediction only]; |
218-322 | 2.02e-06 | |||||
Possible nuclease of RNase H fold, RuvC/YqgF family [General function prediction only]; Pssm-ID: 441980 [Multi-domain] Cd Length: 644 Bit Score: 49.47 E-value: 2.02e-06
|
|||||||||
| COG4913 | COG4913 | Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown]; |
184-344 | 4.08e-06 | |||||
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown]; Pssm-ID: 443941 [Multi-domain] Cd Length: 1089 Bit Score: 48.76 E-value: 4.08e-06
|
|||||||||
| Smc | COG1196 | Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
161-313 | 4.78e-06 | |||||
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 48.39 E-value: 4.78e-06
|
|||||||||
| COG4913 | COG4913 | Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown]; |
98-353 | 5.08e-06 | |||||
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown]; Pssm-ID: 443941 [Multi-domain] Cd Length: 1089 Bit Score: 48.37 E-value: 5.08e-06
|
|||||||||
| YhaN | COG4717 | Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; |
166-324 | 5.44e-06 | |||||
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; Pssm-ID: 443752 [Multi-domain] Cd Length: 641 Bit Score: 48.23 E-value: 5.44e-06
|
|||||||||
| DR0291 | COG1579 | Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General ... |
222-339 | 9.00e-06 | |||||
Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General function prediction only]; Pssm-ID: 441187 [Multi-domain] Cd Length: 236 Bit Score: 46.46 E-value: 9.00e-06
|
|||||||||
| SMC_prok_A | TIGR02169 | chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
218-348 | 1.84e-05 | |||||
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins] Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 46.60 E-value: 1.84e-05
|
|||||||||
| PRK02224 | PRK02224 | DNA double-strand break repair Rad50 ATPase; |
111-313 | 3.11e-05 | |||||
DNA double-strand break repair Rad50 ATPase; Pssm-ID: 179385 [Multi-domain] Cd Length: 880 Bit Score: 45.80 E-value: 3.11e-05
|
|||||||||
| COG4026 | COG4026 | Uncharacterized conserved protein, contains TOPRIM domain, potential nuclease [General ... |
224-350 | 3.15e-05 | |||||
Uncharacterized conserved protein, contains TOPRIM domain, potential nuclease [General function prediction only]; Pssm-ID: 443204 [Multi-domain] Cd Length: 287 Bit Score: 45.10 E-value: 3.15e-05
|
|||||||||
| YhaN | COG4717 | Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; |
159-298 | 4.44e-05 | |||||
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; Pssm-ID: 443752 [Multi-domain] Cd Length: 641 Bit Score: 45.14 E-value: 4.44e-05
|
|||||||||
| SMC_prok_B | TIGR02168 | chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
110-333 | 4.57e-05 | |||||
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins] Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 45.43 E-value: 4.57e-05
|
|||||||||
| COG2433 | COG2433 | Possible nuclease of RNase H fold, RuvC/YqgF family [General function prediction only]; |
183-274 | 5.00e-05 | |||||
Possible nuclease of RNase H fold, RuvC/YqgF family [General function prediction only]; Pssm-ID: 441980 [Multi-domain] Cd Length: 644 Bit Score: 45.23 E-value: 5.00e-05
|
|||||||||
| COG4913 | COG4913 | Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown]; |
185-346 | 5.11e-05 | |||||
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown]; Pssm-ID: 443941 [Multi-domain] Cd Length: 1089 Bit Score: 45.29 E-value: 5.11e-05
|
|||||||||
| SMC_prok_B | TIGR02168 | chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
218-349 | 7.25e-05 | |||||
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins] Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 44.66 E-value: 7.25e-05
|
|||||||||
| Cast | pfam10174 | RIM-binding protein of the cytomatrix active zone; This is a family of proteins that form part ... |
161-313 | 7.34e-05 | |||||
RIM-binding protein of the cytomatrix active zone; This is a family of proteins that form part of the CAZ (cytomatrix at the active zone) complex which is involved in determining the site of synaptic vesicle fusion. The C-terminus is a PDZ-binding motif that binds directly to RIM (a small G protein Rab-3A effector). The family also contains four coiled-coil domains. Pssm-ID: 431111 [Multi-domain] Cd Length: 766 Bit Score: 44.81 E-value: 7.34e-05
|
|||||||||
| ClpA | COG0542 | ATP-dependent Clp protease, ATP-binding subunit ClpA [Posttranslational modification, protein ... |
222-313 | 8.44e-05 | |||||
ATP-dependent Clp protease, ATP-binding subunit ClpA [Posttranslational modification, protein turnover, chaperones]; Pssm-ID: 440308 [Multi-domain] Cd Length: 836 Bit Score: 44.30 E-value: 8.44e-05
|
|||||||||
| YhaN | COG4717 | Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; |
212-339 | 8.95e-05 | |||||
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; Pssm-ID: 443752 [Multi-domain] Cd Length: 641 Bit Score: 44.37 E-value: 8.95e-05
|
|||||||||
| PRK02224 | PRK02224 | DNA double-strand break repair Rad50 ATPase; |
161-348 | 1.06e-04 | |||||
DNA double-strand break repair Rad50 ATPase; Pssm-ID: 179385 [Multi-domain] Cd Length: 880 Bit Score: 44.26 E-value: 1.06e-04
|
|||||||||
| SMC_prok_A | TIGR02169 | chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
240-339 | 1.17e-04 | |||||
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins] Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 44.29 E-value: 1.17e-04
|
|||||||||
| PRK03918 | PRK03918 | DNA double-strand break repair ATPase Rad50; |
216-322 | 2.00e-04 | |||||
DNA double-strand break repair ATPase Rad50; Pssm-ID: 235175 [Multi-domain] Cd Length: 880 Bit Score: 43.13 E-value: 2.00e-04
|
|||||||||
| PRK03918 | PRK03918 | DNA double-strand break repair ATPase Rad50; |
183-349 | 2.23e-04 | |||||
DNA double-strand break repair ATPase Rad50; Pssm-ID: 235175 [Multi-domain] Cd Length: 880 Bit Score: 43.13 E-value: 2.23e-04
|
|||||||||
| PLN02939 | PLN02939 | transferase, transferring glycosyl groups |
163-325 | 2.36e-04 | |||||
transferase, transferring glycosyl groups Pssm-ID: 215507 [Multi-domain] Cd Length: 977 Bit Score: 42.97 E-value: 2.36e-04
|
|||||||||
| PRK03918 | PRK03918 | DNA double-strand break repair ATPase Rad50; |
210-322 | 2.77e-04 | |||||
DNA double-strand break repair ATPase Rad50; Pssm-ID: 235175 [Multi-domain] Cd Length: 880 Bit Score: 42.74 E-value: 2.77e-04
|
|||||||||
| PRK03918 | PRK03918 | DNA double-strand break repair ATPase Rad50; |
180-313 | 2.77e-04 | |||||
DNA double-strand break repair ATPase Rad50; Pssm-ID: 235175 [Multi-domain] Cd Length: 880 Bit Score: 42.74 E-value: 2.77e-04
|
|||||||||
| Smc | COG1196 | Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
114-313 | 2.78e-04 | |||||
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 43.00 E-value: 2.78e-04
|
|||||||||
| DUF3584 | pfam12128 | Protein of unknown function (DUF3584); This protein is found in bacteria and eukaryotes. ... |
190-344 | 3.36e-04 | |||||
Protein of unknown function (DUF3584); This protein is found in bacteria and eukaryotes. Proteins in this family are typically between 943 to 1234 amino acids in length. This family contains a P-loop motif suggesting it is a nucleotide binding protein. It may be involved in replication. Pssm-ID: 432349 [Multi-domain] Cd Length: 1191 Bit Score: 42.52 E-value: 3.36e-04
|
|||||||||
| PRK12704 | PRK12704 | phosphodiesterase; Provisional |
228-332 | 3.37e-04 | |||||
phosphodiesterase; Provisional Pssm-ID: 237177 [Multi-domain] Cd Length: 520 Bit Score: 42.46 E-value: 3.37e-04
|
|||||||||
| CCDC158 | pfam15921 | Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. ... |
132-339 | 3.46e-04 | |||||
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. The function is not known. Pssm-ID: 464943 [Multi-domain] Cd Length: 1112 Bit Score: 42.80 E-value: 3.46e-04
|
|||||||||
| YhaN | COG4717 | Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; |
111-307 | 3.48e-04 | |||||
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; Pssm-ID: 443752 [Multi-domain] Cd Length: 641 Bit Score: 42.45 E-value: 3.48e-04
|
|||||||||
| PRK03918 | PRK03918 | DNA double-strand break repair ATPase Rad50; |
200-349 | 5.76e-04 | |||||
DNA double-strand break repair ATPase Rad50; Pssm-ID: 235175 [Multi-domain] Cd Length: 880 Bit Score: 41.97 E-value: 5.76e-04
|
|||||||||
| EnvC | COG4942 | Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, ... |
171-349 | 1.05e-03 | |||||
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, cell division, chromosome partitioning]; Pssm-ID: 443969 [Multi-domain] Cd Length: 377 Bit Score: 40.52 E-value: 1.05e-03
|
|||||||||
| sbcc | TIGR00618 | exonuclease SbcC; All proteins in this family for which functions are known are part of an ... |
176-322 | 1.17e-03 | |||||
exonuclease SbcC; All proteins in this family for which functions are known are part of an exonuclease complex with sbcD homologs. This complex is involved in the initiation of recombination to regulate the levels of palindromic sequences in DNA. This family is based on the phylogenomic analysis of JA Eisen (1999, Ph.D. Thesis, Stanford University). [DNA metabolism, DNA replication, recombination, and repair] Pssm-ID: 129705 [Multi-domain] Cd Length: 1042 Bit Score: 41.11 E-value: 1.17e-03
|
|||||||||
| COG4372 | COG4372 | Uncharacterized protein, contains DUF3084 domain [Function unknown]; |
148-313 | 1.49e-03 | |||||
Uncharacterized protein, contains DUF3084 domain [Function unknown]; Pssm-ID: 443500 [Multi-domain] Cd Length: 370 Bit Score: 40.27 E-value: 1.49e-03
|
|||||||||
| PTZ00121 | PTZ00121 | MAEBL; Provisional |
111-335 | 1.59e-03 | |||||
MAEBL; Provisional Pssm-ID: 173412 [Multi-domain] Cd Length: 2084 Bit Score: 40.51 E-value: 1.59e-03
|
|||||||||
| SMC_prok_B | TIGR02168 | chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
103-331 | 1.62e-03 | |||||
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins] Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 40.43 E-value: 1.62e-03
|
|||||||||
| EnvC | COG4942 | Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, ... |
98-317 | 1.69e-03 | |||||
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, cell division, chromosome partitioning]; Pssm-ID: 443969 [Multi-domain] Cd Length: 377 Bit Score: 40.13 E-value: 1.69e-03
|
|||||||||
| SCP-1 | pfam05483 | Synaptonemal complex protein 1 (SCP-1); Synaptonemal complex protein 1 (SCP-1) is the major ... |
115-327 | 1.69e-03 | |||||
Synaptonemal complex protein 1 (SCP-1); Synaptonemal complex protein 1 (SCP-1) is the major component of the transverse filaments of the synaptonemal complex. Synaptonemal complexes are structures that are formed between homologous chromosomes during meiotic prophase. Pssm-ID: 114219 [Multi-domain] Cd Length: 787 Bit Score: 40.48 E-value: 1.69e-03
|
|||||||||
| PRK03918 | PRK03918 | DNA double-strand break repair ATPase Rad50; |
223-315 | 1.93e-03 | |||||
DNA double-strand break repair ATPase Rad50; Pssm-ID: 235175 [Multi-domain] Cd Length: 880 Bit Score: 40.05 E-value: 1.93e-03
|
|||||||||
| GumC | COG3206 | Exopolysaccharide export protein/domain GumC/Wzc1 [Cell wall/membrane/envelope biogenesis]; |
248-332 | 1.95e-03 | |||||
Exopolysaccharide export protein/domain GumC/Wzc1 [Cell wall/membrane/envelope biogenesis]; Pssm-ID: 442439 [Multi-domain] Cd Length: 687 Bit Score: 40.00 E-value: 1.95e-03
|
|||||||||
| CALCOCO1 | pfam07888 | Calcium binding and coiled-coil domain (CALCOCO1) like; Proteins found in this family are ... |
162-343 | 2.30e-03 | |||||
Calcium binding and coiled-coil domain (CALCOCO1) like; Proteins found in this family are similar to the coiled-coil transcriptional coactivator protein coexpressed by Mus musculus (CoCoA/CALCOCO1). This protein binds to a highly conserved N-terminal domain of p160 coactivators, such as GRIP1, and thus enhances transcriptional activation by a number of nuclear receptors. CALCOCO1 has a central coiled-coil region with three leucine zipper motifs, which is required for its interaction with GRIP1 and may regulate the autonomous transcriptional activation activity of the C-terminal region. Pssm-ID: 462303 [Multi-domain] Cd Length: 488 Bit Score: 39.88 E-value: 2.30e-03
|
|||||||||
| Mplasa_alph_rch | TIGR04523 | helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of ... |
98-313 | 2.35e-03 | |||||
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of Mycoplasma species. Members average 750 amino acids in length, including signal peptide. Sequences are predicted (Jpred 3) to be almost entirely alpha-helical. These sequences show strong periodicity (consistent with long alpha helical structures) and low complexity rich in D,E,N,Q, and K. Genes encoding these proteins are often found in tandem. The function is unknown. Pssm-ID: 275316 [Multi-domain] Cd Length: 745 Bit Score: 40.00 E-value: 2.35e-03
|
|||||||||
| PRK01156 | PRK01156 | chromosome segregation protein; Provisional |
222-352 | 3.93e-03 | |||||
chromosome segregation protein; Provisional Pssm-ID: 100796 [Multi-domain] Cd Length: 895 Bit Score: 39.11 E-value: 3.93e-03
|
|||||||||
| PRK03918 | PRK03918 | DNA double-strand break repair ATPase Rad50; |
180-332 | 4.38e-03 | |||||
DNA double-strand break repair ATPase Rad50; Pssm-ID: 235175 [Multi-domain] Cd Length: 880 Bit Score: 38.89 E-value: 4.38e-03
|
|||||||||
| PRK02224 | PRK02224 | DNA double-strand break repair Rad50 ATPase; |
223-348 | 4.61e-03 | |||||
DNA double-strand break repair Rad50 ATPase; Pssm-ID: 179385 [Multi-domain] Cd Length: 880 Bit Score: 38.87 E-value: 4.61e-03
|
|||||||||
| PRK01156 | PRK01156 | chromosome segregation protein; Provisional |
219-350 | 4.72e-03 | |||||
chromosome segregation protein; Provisional Pssm-ID: 100796 [Multi-domain] Cd Length: 895 Bit Score: 39.11 E-value: 4.72e-03
|
|||||||||
| UPF0242 | pfam06785 | Uncharacterized protein family (UPF0242) N-terminus; This region includes an N-terminal ... |
218-311 | 4.74e-03 | |||||
Uncharacterized protein family (UPF0242) N-terminus; This region includes an N-terminal transmembrane region and a C-terminal coiled-coil. Pssm-ID: 429117 [Multi-domain] Cd Length: 194 Bit Score: 37.88 E-value: 4.74e-03
|
|||||||||
| COG4913 | COG4913 | Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown]; |
161-278 | 5.67e-03 | |||||
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown]; Pssm-ID: 443941 [Multi-domain] Cd Length: 1089 Bit Score: 38.74 E-value: 5.67e-03
|
|||||||||
| DR0291 | COG1579 | Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General ... |
184-348 | 5.67e-03 | |||||
Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General function prediction only]; Pssm-ID: 441187 [Multi-domain] Cd Length: 236 Bit Score: 37.98 E-value: 5.67e-03
|
|||||||||
| INSC_LBD | cd21966 | LGN-binding domain (LBD) of protein Inscuteable (INSC) and similar proteins; Inscuteable (INSC) ... |
179-339 | 6.03e-03 | |||||
LGN-binding domain (LBD) of protein Inscuteable (INSC) and similar proteins; Inscuteable (INSC) functions as an adapter protein linking the Par polarity complex (composed of Par3, Par6 and protein kinase C iota) to the Gpsm1/Gpsm2 complex, and is involved in cell polarity and spindle orientation during mitosis. Par3 interacts with INSC which binds directly to Pins (partner of Insc, homolog of vertebrate LGN/Gpsm2 and AGS3/Gpsm1). Pins then associates with the heterotrimeric G proteins and NuMA, which interacts directly with the cell spindle to control the orientation of the spindle and the division plane of mitotic cells. INSC may regulate cell proliferation and differentiation in the developing nervous system, may play a role in the asymmetric division of fibroblasts, and may also participate in the process of stratification of the squamous epithelium. This model corresponds to the Leu-Gly-Asn Repeat-Enriched Protein (LGN)-binding domain (LBD) of INSC. It interacts with the tetratricopeptide repeat (TPR) motifs of LGN, also called G-protein-signaling modulator 2 (Gpsm2). Pssm-ID: 439320 [Multi-domain] Cd Length: 300 Bit Score: 38.01 E-value: 6.03e-03
|
|||||||||
| PRK05431 | PRK05431 | seryl-tRNA synthetase; Provisional |
224-329 | 7.70e-03 | |||||
seryl-tRNA synthetase; Provisional Pssm-ID: 235461 [Multi-domain] Cd Length: 425 Bit Score: 38.13 E-value: 7.70e-03
|
|||||||||
| CASP_C | pfam08172 | CASP C terminal; This domain is the C-terminal region of the CASP family of proteins. It is a ... |
249-305 | 8.39e-03 | |||||
CASP C terminal; This domain is the C-terminal region of the CASP family of proteins. It is a Golgi membrane protein which is thought to have a role in vesicle transport. Pssm-ID: 462392 [Multi-domain] Cd Length: 247 Bit Score: 37.27 E-value: 8.39e-03
|
|||||||||
| PRK03918 | PRK03918 | DNA double-strand break repair ATPase Rad50; |
220-350 | 9.33e-03 | |||||
DNA double-strand break repair ATPase Rad50; Pssm-ID: 235175 [Multi-domain] Cd Length: 880 Bit Score: 38.12 E-value: 9.33e-03
|
|||||||||
| DUF3584 | pfam12128 | Protein of unknown function (DUF3584); This protein is found in bacteria and eukaryotes. ... |
176-313 | 9.60e-03 | |||||
Protein of unknown function (DUF3584); This protein is found in bacteria and eukaryotes. Proteins in this family are typically between 943 to 1234 amino acids in length. This family contains a P-loop motif suggesting it is a nucleotide binding protein. It may be involved in replication. Pssm-ID: 432349 [Multi-domain] Cd Length: 1191 Bit Score: 37.90 E-value: 9.60e-03
|
|||||||||
| Blast search parameters | ||||
|
