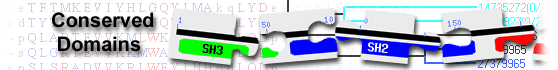ectonucleotide pyrophosphatase/phosphodiesterase (ENPPs) hydrolyzes 5'-phosphodiester bonds in nucleotides and their derivatives, resulting in the release of 5'-nucleotide monophosphates
Ectonucleotide pyrophosphatase/phosphodiesterase, also called autotaxin; Ecto-nucleotide ...
28-382
5.96e-108
Ectonucleotide pyrophosphatase/phosphodiesterase, also called autotaxin; Ecto-nucleotide pyrophosphatases/phosphodiesterases (ENPPs) hydrolyze 5'-phosphodiester bonds in nucleotides and their derivatives, resulting in the release of 5'-nucleotide monophosphates. ENPPs have multiple physiological roles, including nucleotide recycling, modulation of purinergic receptor signaling, regulation of extracellular pyrophosphate levels, stimulation of cell motility, and possible roles in regulation of insulin receptor (IR) signaling and activity of ecto-kinases. The eukaryotic ENPP family contains at least five members that have different tissue distribution and physiological roles.
:
Pssm-ID: 293742 [Multi-domain] Cd Length: 267 Bit Score: 321.07 E-value: 5.96e-108
Ectonucleotide pyrophosphatase/phosphodiesterase, also called autotaxin; Ecto-nucleotide ...
28-382
5.96e-108
Ectonucleotide pyrophosphatase/phosphodiesterase, also called autotaxin; Ecto-nucleotide pyrophosphatases/phosphodiesterases (ENPPs) hydrolyze 5'-phosphodiester bonds in nucleotides and their derivatives, resulting in the release of 5'-nucleotide monophosphates. ENPPs have multiple physiological roles, including nucleotide recycling, modulation of purinergic receptor signaling, regulation of extracellular pyrophosphate levels, stimulation of cell motility, and possible roles in regulation of insulin receptor (IR) signaling and activity of ecto-kinases. The eukaryotic ENPP family contains at least five members that have different tissue distribution and physiological roles.
Pssm-ID: 293742 [Multi-domain] Cd Length: 267 Bit Score: 321.07 E-value: 5.96e-108
Type I phosphodiesterase / nucleotide pyrophosphatase; This family consists of ...
30-342
6.64e-107
Type I phosphodiesterase / nucleotide pyrophosphatase; This family consists of phosphodiesterases, including human plasma-cell membrane glycoprotein PC-1 / alkaline phosphodiesterase i / nucleotide pyrophosphatase (nppase). These enzymes catalyze the cleavage of phosphodiester and phosphosulfate bonds in NAD, deoxynucleotides and nucleotide sugars. Also in this family is ATX an autotaxin, tumour cell motility-stimulating protein which exhibits type I phosphodiesterases activity. The alignment encompasses the active site. Also present with in this family is 60-kDa Ca2+-ATPase form F. odoratum.
Pssm-ID: 396300 [Multi-domain] Cd Length: 343 Bit Score: 321.29 E-value: 6.64e-107
Ectonucleotide pyrophosphatase/phosphodiesterase, also called autotaxin; Ecto-nucleotide ...
28-382
5.96e-108
Ectonucleotide pyrophosphatase/phosphodiesterase, also called autotaxin; Ecto-nucleotide pyrophosphatases/phosphodiesterases (ENPPs) hydrolyze 5'-phosphodiester bonds in nucleotides and their derivatives, resulting in the release of 5'-nucleotide monophosphates. ENPPs have multiple physiological roles, including nucleotide recycling, modulation of purinergic receptor signaling, regulation of extracellular pyrophosphate levels, stimulation of cell motility, and possible roles in regulation of insulin receptor (IR) signaling and activity of ecto-kinases. The eukaryotic ENPP family contains at least five members that have different tissue distribution and physiological roles.
Pssm-ID: 293742 [Multi-domain] Cd Length: 267 Bit Score: 321.07 E-value: 5.96e-108
Type I phosphodiesterase / nucleotide pyrophosphatase; This family consists of ...
30-342
6.64e-107
Type I phosphodiesterase / nucleotide pyrophosphatase; This family consists of phosphodiesterases, including human plasma-cell membrane glycoprotein PC-1 / alkaline phosphodiesterase i / nucleotide pyrophosphatase (nppase). These enzymes catalyze the cleavage of phosphodiester and phosphosulfate bonds in NAD, deoxynucleotides and nucleotide sugars. Also in this family is ATX an autotaxin, tumour cell motility-stimulating protein which exhibits type I phosphodiesterases activity. The alignment encompasses the active site. Also present with in this family is 60-kDa Ca2+-ATPase form F. odoratum.
Pssm-ID: 396300 [Multi-domain] Cd Length: 343 Bit Score: 321.29 E-value: 6.64e-107
alkaline phosphatases and sulfatases; This family includes alkaline phosphatases and ...
30-275
3.52e-17
alkaline phosphatases and sulfatases; This family includes alkaline phosphatases and sulfatases. Alkaline phosphatases are non-specific phosphomonoesterases that catalyze the hydrolysis reaction via a phosphoseryl intermediate to produce inorganic phosphate and the corresponding alcohol, optimally at high pH. Alkaline phosphatase exists as a dimer, each monomer binding 2 zinc atoms and one magnesium atom, which are essential for enzymatic activity. Sulfatases catalyze the hydrolysis of sulfate esters from wide range of substrates, including steroids, carbohydrates and proteins. Sulfate esters may be formed from various alcohols and amines. The biological roles of sulfatase includes the cycling of sulfur in the environment, in the degradation of sulfated glycosaminoglycans and glycolipids in the lysosome, and in remodeling sulfated glycosaminoglycans in the extracellular space. Both alkaline phosphatase and sulfatase are essential for human metabolism. Deficiency of individual enzyme cause genetic diseases.
Pssm-ID: 293732 [Multi-domain] Cd Length: 237 Bit Score: 80.54 E-value: 3.52e-17
SPAP is a subclass of alkaline phosphatase (AP); Alkaline phosphatases are non-specific ...
30-142
4.59e-05
SPAP is a subclass of alkaline phosphatase (AP); Alkaline phosphatases are non-specific phosphomonoesterases that catalyze the hydrolysis reaction via a phosphoseryl intermediate to produce inorganic phosphate and the corresponding alcohol, optimally at high pH. Alkaline phosphatase exists as a dimer, each monomer binding 2 zinc atoms and one magnesium atom, which are essential for enzymatic activity. Although SPAP is a subclass of alkaline phosphatase, SPAP has many differences from other APs: 1) the catalytic residue is a threonine instead of serine, 2) there is no binding pocket for the third metal ion, and 3) the arginine residue forming bidentate hydrogen bonding is deleted in SPAP. A lysine and an asparagine residue, recruited together for the first time into the active site, bind the substrate phosphoryl group in a manner not observed before in any other AP.
Pssm-ID: 293740 [Multi-domain] Cd Length: 457 Bit Score: 45.60 E-value: 4.59e-05
GPI ethanolamine phosphate transferase 2; PIG-G; Ethanolamine phosphate transferase is involved in glycosylphosphatidylinositol-anchor biosynthesis. It catalyzes the transfer of ethanolamine phosphate to the first alpha-1,4-linked mannose of the glycosylphosphatidylinositol precursor of GPI-anchor. It may act as suppressor of replication stress and chromosome missegregation.
Pssm-ID: 293748 [Multi-domain] Cd Length: 274 Bit Score: 44.86 E-value: 4.88e-05
N-sulfoglucosamine sulfohydrolase (SGSH; sulfamidase); N-sulfoglucosamine sulfohydrolase (SGSH) belongs to the sulfatase family and catalyses the cleavage of N-linked sulfate groups from the GAGs heparin sulfate and heparin. The active site is characterized by the amino-acid sequence motif C(X)PSR that is highly conserved among most sulfatases. The cysteine residue is post-translationally converted to a formylglycine (FGly) residue, which is crucial for the catalytic process. Loss of function of SGSH results a disease called mucopolysaccharidosis type IIIA (Sanfilippo A syndrome), a fatal childhood-onset neurodegenerative disease with mild facial, visceral and skeletal abnormalities.
Pssm-ID: 293751 [Multi-domain] Cd Length: 373 Bit Score: 40.95 E-value: 1.45e-03
GPI ethanolamine phosphate transferase 3, PIG-O; Ethanolamine phosphate transferase is involved in glycosylphosphatidylinositol-anchor biosynthesis. It catalyzes the transfer of ethanolamine phosphate to the first alpha-1,4-linked mannose of the glycosylphosphatidylinositol precursor of GPI-anchor. It may act as suppressor of replication stress and chromosome missegregation.
Pssm-ID: 293747 Cd Length: 289 Bit Score: 38.31 E-value: 8.14e-03
Database: CDSEARCH/cdd Low complexity filter: no Composition Based Adjustment: yes E-value threshold: 0.01
References:
Wang J et al. (2023), "The conserved domain database in 2023", Nucleic Acids Res.51(D)384-8.
Lu S et al. (2020), "The conserved domain database in 2020", Nucleic Acids Res.48(D)265-8.
Marchler-Bauer A et al. (2017), "CDD/SPARCLE: functional classification of proteins via subfamily domain architectures.", Nucleic Acids Res.45(D)200-3.
of the residues that compose this conserved feature have been mapped to the query sequence.
Click on the triangle to view details about the feature, including a multiple sequence alignment
of your query sequence and the protein sequences used to curate the domain model,
where hash marks (#) above the aligned sequences show the location of the conserved feature residues.
The thumbnail image, if present, provides an approximate view of the feature's location in 3 dimensions.
Click on the triangle for interactive 3D structure viewing options.
Functional characterization of the conserved domain architecture found on the query.
Click here to see more details.
This image shows a graphical summary of conserved domains identified on the query sequence.
The Show Concise/Full Display button at the top of the page can be used to select the desired level of detail: only top scoring hits
(labeled illustration) or all hits
(labeled illustration).
Domains are color coded according to superfamilies
to which they have been assigned. Hits with scores that pass a domain-specific threshold
(specific hits) are drawn in bright colors.
Others (non-specific hits) and
superfamily placeholders are drawn in pastel colors.
if a domain or superfamily has been annotated with functional sites (conserved features),
they are mapped to the query sequence and indicated through sets of triangles
with the same color and shade of the domain or superfamily that provides the annotation. Mouse over the colored bars or triangles to see descriptions of the domains and features.
click on the bars or triangles to view your query sequence embedded in a multiple sequence alignment of the proteins used to develop the corresponding domain model.
The table lists conserved domains identified on the query sequence. Click on the plus sign (+) on the left to display full descriptions, alignments, and scores.
Click on the domain model's accession number to view the multiple sequence alignment of the proteins used to develop the corresponding domain model.
To view your query sequence embedded in that multiple sequence alignment, click on the colored bars in the Graphical Summary portion of the search results page,
or click on the triangles, if present, that represent functional sites (conserved features)
mapped to the query sequence.
Concise Display shows only the best scoring domain model, in each hit category listed below except non-specific hits, for each region on the query sequence.
(labeled illustration) Standard Display shows only the best scoring domain model from each source, in each hit category listed below for each region on the query sequence.
(labeled illustration) Full Display shows all domain models, in each hit category below, that meet or exceed the RPS-BLAST threshold for statistical significance.
(labeled illustration) Four types of hits can be shown, as available,
for each region on the query sequence:
specific hits meet or exceed a domain-specific e-value threshold
(illustrated example)
and represent a very high confidence that the query sequence belongs to the same protein family as the sequences use to create the domain model
non-specific hits
meet or exceed the RPS-BLAST threshold for statistical significance (default E-value cutoff of 0.01, or an E-value selected by user via the
advanced search options)
the domain superfamily to which the specific and non-specific hits belong
multi-domain models that were computationally detected and are likely to contain multiple single domains
Retrieve proteins that contain one or more of the domains present in the query sequence, using the Conserved Domain Architecture Retrieval Tool
(CDART).
Modify your query to search against a different database and/or use advanced search options