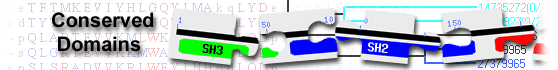


trinucleotide repeat-containing gene 6C protein isoform 6 [Homo sapiens]
Protein Classification

TNRC6-PABC_bdg and RRM_TNRC6C domain-containing protein( domain architecture ID 11186855)
protein containing domains Ago_hook, M_domain, TNRC6-PABC_bdg, and RRM_TNRC6C
List of domain hits
| Name | Accession | Description | Interval | E-value | ||||||
| TNRC6-PABC_bdg | pfam16608 | TNRC6-PABC binding domain; TNRC6-PABC_bdg is a natively unstructured region on the higher ... |
1263-1556 | 2.80e-107 | ||||||
TNRC6-PABC binding domain; TNRC6-PABC_bdg is a natively unstructured region on the higher eukaryote TNRC6 subset of GW182 proteins that carries the binding motif for the interaction with Polyadenylate-binding protein 1, PABC. TNRC6 are trinucleotide repeat-containing gene 6 proteins required for miRNA-mediated gene silencing that are localized to the P bodies (processing bodies). P bodies are cytoplasmic mRNP aggregates that are involved in general mRNA translation repression and decay, including nonsense-mediated decay. Thus GW182 proteins are essential for microRNA-mediated translational repression and deadenylation in animal cells being a major component of miRISCs. The interaction motif that binds to PABC is ShNWPPEFHPGVPWKGLQ. This region lies between a Q-rich region and the RRM, or RNA-recognition motif, pfam13893. : Pssm-ID: 465195 Cd Length: 290 Bit Score: 343.89 E-value: 2.80e-107
|
||||||||||
| RRM_TNRC6C | cd12713 | RNA recognition motif (RRM) found in vertebrate trinucleotide repeat-containing gene 6C ... |
1552-1639 | 3.58e-56 | ||||||
RNA recognition motif (RRM) found in vertebrate trinucleotide repeat-containing gene 6C protein (TNRC6C); This subgroup corresponds to the RRM of TNRC6C, one of three GW182 paralogs in mammalian genomes. It is enriched in P-bodies and important for efficient miRNA-mediated repression. TNRC6C is composed of an N-terminal glycine/tryptophan (G/W)-rich region containing an Ago hook responsible for Ago protein-binding; a ubiquitin-associated (UBA) domain and a glutamine (Q)-rich region in the middle region; a middle G/W-rich region, a RNA recognition motif (RRM), also termed RBD (RNA binding domain) or RNP (ribonucleoprotein domain), and a C-terminal G/W-rich region, at the C-terminus. A bipartite C-terminal region including the middle and C-terminal G/W-rich regions is referred as silencing domain that triggers silencing of bound transcripts by inhibiting protein expression and promoting mRNA decay via deadenylation. The C-terminal half containing the RRM domain functions as a key effector domain mediating protein synthesis repression by TNRC6C. : Pssm-ID: 410112 [Multi-domain] Cd Length: 88 Bit Score: 189.53 E-value: 3.58e-56
|
||||||||||
| M_domain | pfam12938 | M domain of GW182; |
1026-1254 | 1.34e-46 | ||||||
M domain of GW182; : Pssm-ID: 432890 [Multi-domain] Cd Length: 243 Bit Score: 168.18 E-value: 1.34e-46
|
||||||||||
| Ago_hook | pfam10427 | Argonaute hook; This region has been called the argonaute hook. It has been shown to bind to ... |
825-935 | 4.33e-17 | ||||||
Argonaute hook; This region has been called the argonaute hook. It has been shown to bind to the Piwi domain pfam02171 of Argnonaute proteins. : Pssm-ID: 463088 [Multi-domain] Cd Length: 148 Bit Score: 80.09 E-value: 4.33e-17
|
||||||||||
| UBA_TNR6C | cd14283 | UBA domain found in trinucleotide repeat-containing gene 6C protein (TNRC6C) and similar ... |
938-975 | 4.99e-17 | ||||||
UBA domain found in trinucleotide repeat-containing gene 6C protein (TNRC6C) and similar proteins; TNRC6C is one of three GW182 paralogs in mammalian genomes. It is enriched in P-bodies and important for efficient miRNA-mediated repression. TNRC6C is composed of an N-terminal glycine/tryptophan (G/W)-rich region containing an Ago hook responsible for Ago protein-binding; a ubiquitin-associated (UBA) domain and a glutamine (Q)-rich region in the middle region; a middle G/W-rich region, a RNA recognition motif (RRM), also called RBD (RNA binding domain) or RNP (ribonucleoprotein domain), and a C-terminal G/W-rich region, at the C-terminus. A bipartite C-terminal region including the middle and C-terminal G/W-rich regions is referred as silencing domain that triggers silencing of bound transcripts by inhibiting protein expression and promoting mRNA decay via deadenylation. The C-terminal half containing the RRM domain functions as a key effector domain mediating protein synthesis repression by TNRC6C. : Pssm-ID: 270469 Cd Length: 38 Bit Score: 76.01 E-value: 4.99e-17
|
||||||||||
| ser_rich_anae_1 super family | cl41472 | serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 ... |
250-420 | 1.89e-06 | ||||||
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 amino acids), which a highly serine-rich central region that averages over 300 aa in length. Species encoding members of this family of proteins tend to be anaerobic bacteria, including Gram-positive bacteria of the human gut microbiome and Chloroflexi from marine sediments. The actual alignment was detected with superfamily member NF033849: Pssm-ID: 468206 [Multi-domain] Cd Length: 1122 Bit Score: 53.09 E-value: 1.89e-06
|
||||||||||
| COG4625 super family | cl34793 | Uncharacterized conserved protein, contains a C-terminal beta-barrel porin domain [Function ... |
2-379 | 3.46e-04 | ||||||
Uncharacterized conserved protein, contains a C-terminal beta-barrel porin domain [Function unknown]; The actual alignment was detected with superfamily member COG4625: Pssm-ID: 443664 [Multi-domain] Cd Length: 900 Bit Score: 45.54 E-value: 3.46e-04
|
||||||||||
| Name | Accession | Description | Interval | E-value | ||||||
| TNRC6-PABC_bdg | pfam16608 | TNRC6-PABC binding domain; TNRC6-PABC_bdg is a natively unstructured region on the higher ... |
1263-1556 | 2.80e-107 | ||||||
TNRC6-PABC binding domain; TNRC6-PABC_bdg is a natively unstructured region on the higher eukaryote TNRC6 subset of GW182 proteins that carries the binding motif for the interaction with Polyadenylate-binding protein 1, PABC. TNRC6 are trinucleotide repeat-containing gene 6 proteins required for miRNA-mediated gene silencing that are localized to the P bodies (processing bodies). P bodies are cytoplasmic mRNP aggregates that are involved in general mRNA translation repression and decay, including nonsense-mediated decay. Thus GW182 proteins are essential for microRNA-mediated translational repression and deadenylation in animal cells being a major component of miRISCs. The interaction motif that binds to PABC is ShNWPPEFHPGVPWKGLQ. This region lies between a Q-rich region and the RRM, or RNA-recognition motif, pfam13893. Pssm-ID: 465195 Cd Length: 290 Bit Score: 343.89 E-value: 2.80e-107
|
||||||||||
| RRM_TNRC6C | cd12713 | RNA recognition motif (RRM) found in vertebrate trinucleotide repeat-containing gene 6C ... |
1552-1639 | 3.58e-56 | ||||||
RNA recognition motif (RRM) found in vertebrate trinucleotide repeat-containing gene 6C protein (TNRC6C); This subgroup corresponds to the RRM of TNRC6C, one of three GW182 paralogs in mammalian genomes. It is enriched in P-bodies and important for efficient miRNA-mediated repression. TNRC6C is composed of an N-terminal glycine/tryptophan (G/W)-rich region containing an Ago hook responsible for Ago protein-binding; a ubiquitin-associated (UBA) domain and a glutamine (Q)-rich region in the middle region; a middle G/W-rich region, a RNA recognition motif (RRM), also termed RBD (RNA binding domain) or RNP (ribonucleoprotein domain), and a C-terminal G/W-rich region, at the C-terminus. A bipartite C-terminal region including the middle and C-terminal G/W-rich regions is referred as silencing domain that triggers silencing of bound transcripts by inhibiting protein expression and promoting mRNA decay via deadenylation. The C-terminal half containing the RRM domain functions as a key effector domain mediating protein synthesis repression by TNRC6C. Pssm-ID: 410112 [Multi-domain] Cd Length: 88 Bit Score: 189.53 E-value: 3.58e-56
|
||||||||||
| M_domain | pfam12938 | M domain of GW182; |
1026-1254 | 1.34e-46 | ||||||
M domain of GW182; Pssm-ID: 432890 [Multi-domain] Cd Length: 243 Bit Score: 168.18 E-value: 1.34e-46
|
||||||||||
| Ago_hook | pfam10427 | Argonaute hook; This region has been called the argonaute hook. It has been shown to bind to ... |
825-935 | 4.33e-17 | ||||||
Argonaute hook; This region has been called the argonaute hook. It has been shown to bind to the Piwi domain pfam02171 of Argnonaute proteins. Pssm-ID: 463088 [Multi-domain] Cd Length: 148 Bit Score: 80.09 E-value: 4.33e-17
|
||||||||||
| UBA_TNR6C | cd14283 | UBA domain found in trinucleotide repeat-containing gene 6C protein (TNRC6C) and similar ... |
938-975 | 4.99e-17 | ||||||
UBA domain found in trinucleotide repeat-containing gene 6C protein (TNRC6C) and similar proteins; TNRC6C is one of three GW182 paralogs in mammalian genomes. It is enriched in P-bodies and important for efficient miRNA-mediated repression. TNRC6C is composed of an N-terminal glycine/tryptophan (G/W)-rich region containing an Ago hook responsible for Ago protein-binding; a ubiquitin-associated (UBA) domain and a glutamine (Q)-rich region in the middle region; a middle G/W-rich region, a RNA recognition motif (RRM), also called RBD (RNA binding domain) or RNP (ribonucleoprotein domain), and a C-terminal G/W-rich region, at the C-terminus. A bipartite C-terminal region including the middle and C-terminal G/W-rich regions is referred as silencing domain that triggers silencing of bound transcripts by inhibiting protein expression and promoting mRNA decay via deadenylation. The C-terminal half containing the RRM domain functions as a key effector domain mediating protein synthesis repression by TNRC6C. Pssm-ID: 270469 Cd Length: 38 Bit Score: 76.01 E-value: 4.99e-17
|
||||||||||
| ser_rich_anae_1 | NF033849 | serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 ... |
250-420 | 1.89e-06 | ||||||
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 amino acids), which a highly serine-rich central region that averages over 300 aa in length. Species encoding members of this family of proteins tend to be anaerobic bacteria, including Gram-positive bacteria of the human gut microbiome and Chloroflexi from marine sediments. Pssm-ID: 468206 [Multi-domain] Cd Length: 1122 Bit Score: 53.09 E-value: 1.89e-06
|
||||||||||
| UBA | smart00165 | Ubiquitin associated domain; Present in Rad23, SNF1-like kinases. The newly-found UBA in p62 ... |
941-973 | 5.79e-05 | ||||||
Ubiquitin associated domain; Present in Rad23, SNF1-like kinases. The newly-found UBA in p62 is known to bind ubiquitin. Pssm-ID: 197551 [Multi-domain] Cd Length: 37 Bit Score: 41.70 E-value: 5.79e-05
|
||||||||||
| UBA | pfam00627 | UBA/TS-N domain; This small domain is composed of three alpha helices. This family includes ... |
941-969 | 2.61e-04 | ||||||
UBA/TS-N domain; This small domain is composed of three alpha helices. This family includes the previously defined UBA and TS-N domains. The UBA-domain (ubiquitin associated domain) is a novel sequence motif found in several proteins having connections to ubiquitin and the ubiquitination pathway. The structure of the UBA domain consists of a compact three helix bundle. This domain is found at the N terminus of EF-TS hence the name TS-N. The structure of EF-TS is known and this domain is implicated in its interaction with EF-TU. The domain has been found in non EF-TS proteins such as alpha-NAC and MJ0280. Pssm-ID: 395502 [Multi-domain] Cd Length: 37 Bit Score: 39.73 E-value: 2.61e-04
|
||||||||||
| COG4625 | COG4625 | Uncharacterized conserved protein, contains a C-terminal beta-barrel porin domain [Function ... |
2-379 | 3.46e-04 | ||||||
Uncharacterized conserved protein, contains a C-terminal beta-barrel porin domain [Function unknown]; Pssm-ID: 443664 [Multi-domain] Cd Length: 900 Bit Score: 45.54 E-value: 3.46e-04
|
||||||||||
| RRM_1 | pfam00076 | RNA recognition motif. (a.k.a. RRM, RBD, or RNP domain); The RRM motif is probably diagnostic ... |
1560-1624 | 7.54e-03 | ||||||
RNA recognition motif. (a.k.a. RRM, RBD, or RNP domain); The RRM motif is probably diagnostic of an RNA binding protein. RRMs are found in a variety of RNA binding proteins, including various hnRNP proteins, proteins implicated in regulation of alternative splicing, and protein components of snRNPs. The motif also appears in a few single stranded DNA binding proteins. The RRM structure consists of four strands and two helices arranged in an alpha/beta sandwich, with a third helix present during RNA binding in some cases The C-terminal beta strand (4th strand) and final helix are hard to align and have been omitted in the SEED alignment The LA proteins have an N terminal rrm which is included in the seed. There is a second region towards the C terminus that has some features characteriztic of a rrm but does not appear to have the important structural core of a rrm. The LA proteins are one of the main autoantigens in Systemic lupus erythematosus (SLE), an autoimmune disease. Pssm-ID: 425453 [Multi-domain] Cd Length: 70 Bit Score: 36.83 E-value: 7.54e-03
|
||||||||||
| Name | Accession | Description | Interval | E-value | ||||||
| TNRC6-PABC_bdg | pfam16608 | TNRC6-PABC binding domain; TNRC6-PABC_bdg is a natively unstructured region on the higher ... |
1263-1556 | 2.80e-107 | ||||||
TNRC6-PABC binding domain; TNRC6-PABC_bdg is a natively unstructured region on the higher eukaryote TNRC6 subset of GW182 proteins that carries the binding motif for the interaction with Polyadenylate-binding protein 1, PABC. TNRC6 are trinucleotide repeat-containing gene 6 proteins required for miRNA-mediated gene silencing that are localized to the P bodies (processing bodies). P bodies are cytoplasmic mRNP aggregates that are involved in general mRNA translation repression and decay, including nonsense-mediated decay. Thus GW182 proteins are essential for microRNA-mediated translational repression and deadenylation in animal cells being a major component of miRISCs. The interaction motif that binds to PABC is ShNWPPEFHPGVPWKGLQ. This region lies between a Q-rich region and the RRM, or RNA-recognition motif, pfam13893. Pssm-ID: 465195 Cd Length: 290 Bit Score: 343.89 E-value: 2.80e-107
|
||||||||||
| RRM_TNRC6C | cd12713 | RNA recognition motif (RRM) found in vertebrate trinucleotide repeat-containing gene 6C ... |
1552-1639 | 3.58e-56 | ||||||
RNA recognition motif (RRM) found in vertebrate trinucleotide repeat-containing gene 6C protein (TNRC6C); This subgroup corresponds to the RRM of TNRC6C, one of three GW182 paralogs in mammalian genomes. It is enriched in P-bodies and important for efficient miRNA-mediated repression. TNRC6C is composed of an N-terminal glycine/tryptophan (G/W)-rich region containing an Ago hook responsible for Ago protein-binding; a ubiquitin-associated (UBA) domain and a glutamine (Q)-rich region in the middle region; a middle G/W-rich region, a RNA recognition motif (RRM), also termed RBD (RNA binding domain) or RNP (ribonucleoprotein domain), and a C-terminal G/W-rich region, at the C-terminus. A bipartite C-terminal region including the middle and C-terminal G/W-rich regions is referred as silencing domain that triggers silencing of bound transcripts by inhibiting protein expression and promoting mRNA decay via deadenylation. The C-terminal half containing the RRM domain functions as a key effector domain mediating protein synthesis repression by TNRC6C. Pssm-ID: 410112 [Multi-domain] Cd Length: 88 Bit Score: 189.53 E-value: 3.58e-56
|
||||||||||
| RRM_TNRC6A | cd12711 | RNA recognition motif (RRM) found in vertebrate GW182 autoantigen; This subgroup corresponds ... |
1552-1643 | 2.97e-49 | ||||||
RNA recognition motif (RRM) found in vertebrate GW182 autoantigen; This subgroup corresponds to the RRM of the GW182 autoantigen, also termed trinucleotide repeat-containing gene 6A protein (TNRC6A), or CAG repeat protein 26, or EMSY interactor protein, or protein GW1, or glycine-tryptophan protein of 182 kDa, a phosphorylated cytoplasmic autoantigen involved in stabilizing and/or regulating translation and/or storing several different mRNAs. GW182 is characterized by multiple glycine/tryptophan (G/W) repeats and is a critical component of GW bodies (GWBs, also called mammalian processing bodies, or P bodies). The mRNAs associated with GW182 are presumed to reside within GWBs. GW182 has been shown to bind multiple Ago-miRNA complexes, and thus plays a key role in miRNA-mediated translational repression and mRNA degradation. In the absence of Ago2, GW182 may induce translational silencing effect. GW182 is composed of an N-terminal G/W-rich region containing an Ago hook responsible for Ago protein-binding; a ubiquitin-associated (UBA) domain and a glutamine (Q)-rich region in the middle region; a middle G/W-rich region, a RNA recognition motif (RRM), also termed RBD (RNA binding domain) or RNP (ribonucleoprotein domain), and a C-terminal G/W-rich region, at the C-terminus. A bipartite C-terminal region including the middle and C-terminal G/W-rich regions is referred to as silencing domain that triggers silencing of bound transcripts by inhibiting protein expression and promoting mRNA decay via deadenylation. Pssm-ID: 410110 Cd Length: 92 Bit Score: 169.88 E-value: 2.97e-49
|
||||||||||
| RRM_TNRC6B | cd12712 | RNA recognition motif (RRM) found in vertebrate trinucleotide repeat-containing gene 6B ... |
1557-1639 | 5.40e-49 | ||||||
RNA recognition motif (RRM) found in vertebrate trinucleotide repeat-containing gene 6B protein (TNRC6B); This subgroup corresponds to the RRM of TNRC6B, one of three GW182 paralogs in mammalian genomes. It is involved in miRNA-mediated mRNA degradation. TNRC6B is composed of an N-terminal glycine/tryptophan (G/W)-rich region; a ubiquitin-associated (UBA) domain and a glutamine (Q)-rich region in the middle region; a middle G/W-rich region, a RNA recognition motif (RRM), also termed RBD (RNA binding domain) or RNP (ribonucleoprotein domain), and a C-terminal G/W-rich region, at the C-terminus. TNRC6B directly interacts with Argonaute (Ago) proteins through its N-terminal glycine/tryptophan (G/W)-rich region that is called Ago protein-binding domain. TNRC6B is enriched in P-bodies and its Q-rich domain is responsible for P-body localization. A bipartite C-terminal region including the middle and C-terminal G/W-rich regions is referred as silencing domain that triggers silencing of bound transcripts by inhibiting protein expression and promoting mRNA decay via deadenylation. The C-terminal half of TNRC6B comprising an RRM domain exerts a strong translation inhibition potential, which does not require either association with Agos or localization to P-bodies. Pssm-ID: 410111 Cd Length: 83 Bit Score: 168.70 E-value: 5.40e-49
|
||||||||||
| RRM_GW182_like | cd12435 | RNA recognition motif (RRM) found in the GW182 family proteins; This subfamily corresponds to ... |
1557-1627 | 3.92e-47 | ||||||
RNA recognition motif (RRM) found in the GW182 family proteins; This subfamily corresponds to the RRM of the GW182 family which includes three paralogs of TNRC6 (GW182-related) proteins comprising GW182/TNGW1, TNRC6B (containing three isoforms) and TNRC6C in mammal, a single Drosophila ortholog (dGW182, also called Gawky) and two Caenorhabditis elegans orthologs AIN-1 and AIN-2, which contain multiple miRNA-binding sites and have important functions in miRNA-mediated translational repression, as well as mRNA degradation in Metazoa. The GW182 family proteins directly interact with Argonaute (Ago) proteins, and thus function as downstream effectors in the miRNA pathway, responsible for inhibition of translation and acceleration of mRNA decay. Members in this family are characterized by an abnormally high content of glycine/tryptophan (G/W) repeats, one or more glutamine (Q)-rich motifs, and a C-terminal RNA recognition motif (RRM), also termed RBD (RNA binding domain) or RNP (ribonucleoprotein domain). The only exception is the worm protein that does not contain a recognizable RRM domain. The GW182 family proteins are recruited to miRNA targets through an interaction between their N-terminal domain and an Argonaute protein. Then they promote translational repression and/or degradation of miRNA targets through their C-terminal silencing domain. Pssm-ID: 409869 [Multi-domain] Cd Length: 71 Bit Score: 162.99 E-value: 3.92e-47
|
||||||||||
| M_domain | pfam12938 | M domain of GW182; |
1026-1254 | 1.34e-46 | ||||||
M domain of GW182; Pssm-ID: 432890 [Multi-domain] Cd Length: 243 Bit Score: 168.18 E-value: 1.34e-46
|
||||||||||
| Ago_hook | pfam10427 | Argonaute hook; This region has been called the argonaute hook. It has been shown to bind to ... |
825-935 | 4.33e-17 | ||||||
Argonaute hook; This region has been called the argonaute hook. It has been shown to bind to the Piwi domain pfam02171 of Argnonaute proteins. Pssm-ID: 463088 [Multi-domain] Cd Length: 148 Bit Score: 80.09 E-value: 4.33e-17
|
||||||||||
| UBA_TNR6C | cd14283 | UBA domain found in trinucleotide repeat-containing gene 6C protein (TNRC6C) and similar ... |
938-975 | 4.99e-17 | ||||||
UBA domain found in trinucleotide repeat-containing gene 6C protein (TNRC6C) and similar proteins; TNRC6C is one of three GW182 paralogs in mammalian genomes. It is enriched in P-bodies and important for efficient miRNA-mediated repression. TNRC6C is composed of an N-terminal glycine/tryptophan (G/W)-rich region containing an Ago hook responsible for Ago protein-binding; a ubiquitin-associated (UBA) domain and a glutamine (Q)-rich region in the middle region; a middle G/W-rich region, a RNA recognition motif (RRM), also called RBD (RNA binding domain) or RNP (ribonucleoprotein domain), and a C-terminal G/W-rich region, at the C-terminus. A bipartite C-terminal region including the middle and C-terminal G/W-rich regions is referred as silencing domain that triggers silencing of bound transcripts by inhibiting protein expression and promoting mRNA decay via deadenylation. The C-terminal half containing the RRM domain functions as a key effector domain mediating protein synthesis repression by TNRC6C. Pssm-ID: 270469 Cd Length: 38 Bit Score: 76.01 E-value: 4.99e-17
|
||||||||||
| UBA1_KPC2 | cd14303 | UBA1 domain found in Kip1 ubiquitination-promoting complex protein 2 (KPC2) and similar ... |
941-974 | 1.98e-07 | ||||||
UBA1 domain found in Kip1 ubiquitination-promoting complex protein 2 (KPC2) and similar proteins; KPC2, also called ubiquitin-associated domain-containing protein 1 (UBAC1), or glialblastoma cell differentiation-related protein 1, is one of two subunits of Kip1 ubiquitination-promoting complex (KPC), a novel E3 ubiquitin-protein ligase that also contains KPC1 subunit and regulates the ubiquitin-dependent degradation of the cyclin-dependent kinase (CDK) inhibitor p27 at G1 phase. KPC2 contains a ubiquitin-like (UBL) domain and two ubiquitin-associated (UBA) domains. This model corresponds to the UBA1 domain. Pssm-ID: 270488 [Multi-domain] Cd Length: 41 Bit Score: 48.93 E-value: 1.98e-07
|
||||||||||
| UBA | cd14270 | UBA domain found in proteins involved in ubiquitin-mediated proteolysis; The ... |
941-970 | 1.12e-06 | ||||||
UBA domain found in proteins involved in ubiquitin-mediated proteolysis; The ubiquitin-associated (UBA) domains are commonly occurring sequence motifs found in proteins involved in ubiquitin-mediated proteolysis. They contribute to ubiquitin (Ub) binding or ubiquitin-like (UbL) domain binding. However, some kinds of UBA domains can only the bind UbL domain, but not the Ub domain. UBA domains are normally comprised of compact three-helix bundles which contain a conserved GF/Y-loop. They can bind polyubiquitin with high affinity. They also bind monoubiquitin and other proteins. Most UBA domain-containing proteins have one UBA domain, but some harbor two or three UBA domains. Pssm-ID: 270456 [Multi-domain] Cd Length: 30 Bit Score: 46.19 E-value: 1.12e-06
|
||||||||||
| UBA2_spUBP14_like | cd14297 | UBA2 domain found in Schizosaccharomyces pombe ubiquitin carboxyl-terminal hydrolase 14 ... |
940-974 | 1.15e-06 | ||||||
UBA2 domain found in Schizosaccharomyces pombe ubiquitin carboxyl-terminal hydrolase 14 (spUBP14) and similar proteins; spUBP14, also called deubiquitinating enzyme 14, UBA domain-containing protein 2, ubiquitin thioesterase 14, or ubiquitin-specific-processing protease 14, functions as a deubiquitinating enzyme that is involved in protein degradation in fission yeast. Members in this family contain two tandem ubiquitin-association (UBA) domains. This model corresponds to the UBA2 domain. Pssm-ID: 270483 [Multi-domain] Cd Length: 39 Bit Score: 46.70 E-value: 1.15e-06
|
||||||||||
| ser_rich_anae_1 | NF033849 | serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 ... |
250-420 | 1.89e-06 | ||||||
serine-rich protein; This serine-rich protein belongs to a family with large size (over 1000 amino acids), which a highly serine-rich central region that averages over 300 aa in length. Species encoding members of this family of proteins tend to be anaerobic bacteria, including Gram-positive bacteria of the human gut microbiome and Chloroflexi from marine sediments. Pssm-ID: 468206 [Multi-domain] Cd Length: 1122 Bit Score: 53.09 E-value: 1.89e-06
|
||||||||||
| UBA2_UBP13 | cd14387 | UBA2 domain found in ubiquitin carboxyl-terminal hydrolase 13 (UBP13); UBP13, also called ... |
941-972 | 7.19e-06 | ||||||
UBA2 domain found in ubiquitin carboxyl-terminal hydrolase 13 (UBP13); UBP13, also called deubiquitinating enzyme 13, Isopeptidase T-3 (isoT3), ubiquitin thioesterase 13, or ubiquitin-specific-processing protease 13 is an ortholog of UBP5 implicated in catalyzing hydrolysis of various ubiquitin (Ub)-chains. It contains a zinc finger (ZnF) domain, a catalytic ubiquitin-specific processing protease (UBP) domain (catalytic C-box and H-box), and two ubiquitin-associated (UBA) domains. Due to the non-activating catalysis for K63-polyubiquitin chains, UBP13 may function differently from USP5 in cellular deubiquitination processes. Moreover, the zinc finger (ZnF) domain of USP13 cannot bind to Ub. Its tandem UBA domains can bind with different types of diUb but preferentially with K63-linked.USP13 can also regulate the protein level of CD3delta in cells via its UBA domains. This model corresponds to the UBA2 domain. Pssm-ID: 270570 Cd Length: 35 Bit Score: 44.29 E-value: 7.19e-06
|
||||||||||
| UBA_II_E2_pyUCE_like | cd14314 | UBA domain found in a putative ubiquitin conjugating enzyme from plasmodium Yoelii (pyUCE) and ... |
941-973 | 1.17e-05 | ||||||
UBA domain found in a putative ubiquitin conjugating enzyme from plasmodium Yoelii (pyUCE) and similar proteins; P. Yoelii ubiquitin-conjugating enzyme and other uncharacterized family members show high sequence similarity to the human Huntingtin interacting protein-2 (HIP2) which belongs to a class II E2 ubiquitin-conjugating enzyme family. These proteins may play roles in the ubiquitin-mediated protein degradation pathway. They all contain a C-terminal ubiquitin-associated (UBA) domain in addition to an N-terminal catalytic ubiquitin-conjugating enzyme E2 (UBCc) domain. Pssm-ID: 270499 Cd Length: 37 Bit Score: 43.85 E-value: 1.17e-05
|
||||||||||
| RRM_SF | cd00590 | RNA recognition motif (RRM) superfamily; RRM, also known as RBD (RNA binding domain) or RNP ... |
1560-1623 | 1.46e-05 | ||||||
RNA recognition motif (RRM) superfamily; RRM, also known as RBD (RNA binding domain) or RNP (ribonucleoprotein domain), is a highly abundant domain in eukaryotes found in proteins involved in post-transcriptional gene expression processes including mRNA and rRNA processing, RNA export, and RNA stability. This domain is 90 amino acids in length and consists of a four-stranded beta-sheet packed against two alpha-helices. RRM usually interacts with ssRNA, but is also known to interact with ssDNA as well as proteins. RRM binds a variable number of nucleotides, ranging from two to eight. The active site includes three aromatic side-chains located within the conserved RNP1 and RNP2 motifs of the domain. The RRM domain is found in a variety heterogeneous nuclear ribonucleoproteins (hnRNPs), proteins implicated in regulation of alternative splicing, and protein components of small nuclear ribonucleoproteins (snRNPs). Pssm-ID: 409669 [Multi-domain] Cd Length: 72 Bit Score: 44.58 E-value: 1.46e-05
|
||||||||||
| UBA_VP13D | cd14306 | UBA domain found in vacuolar protein sorting-associated protein 13D (VP13D) and similar ... |
941-974 | 2.46e-05 | ||||||
UBA domain found in vacuolar protein sorting-associated protein 13D (VP13D) and similar proteins; VP13D is a chorea-acanthocytosis (CHAC)-similar protein encoded by gene VPS13D. it contains two putative domains, ubiquitin-associated (UBA) domain and lectin domain of ricin B chain profile (ricin-B-lectin), suggesting it may interact with, and be involved in the trafficking of, proteins modified with ubiquitin and/or carbohydrate molecules. Further investigation is required. Pssm-ID: 270491 Cd Length: 36 Bit Score: 42.81 E-value: 2.46e-05
|
||||||||||
| UBA_scDdi1_like | cd14309 | UBA domain found in Saccharomyces cerevisiae DNA-damage response protein Ddi1 and similar ... |
941-973 | 4.56e-05 | ||||||
UBA domain found in Saccharomyces cerevisiae DNA-damage response protein Ddi1 and similar proteins; Ddi1, also called v-SNARE-master 1 (Vsm1), is a ubiquitin receptor involved in regulation of the cell cycle and late secretory pathway in Saccharomyces cerevisiae. It functions as a ubiquitin association domain (UBA)- ubiquitin-like-domain (UBL) shuttle protein that is required for the proteasome to enable ubiquitin-dependent degradation of its ligands. For instance, Ddi1 plays an essential role in the final stages of proteasomal degradation of Ho endonuclease and of its cognate FBP, Ufo1. Moreover, Ddi1 and its associated protein Rad23p play a cooperative role as negative regulators in yeast PHO pathway. Ddi1 contains an N-terminal UBL domain and a C-terminal UBA domain. It also harbors a central retroviral aspartyl-protease-like domain (RVP) which may be important in cell-cycle control. At this point, Ddi1 may function proteolytically during regulated protein turnover in the cell. This family also includes mammalian regulatory solute carrier protein family 1 member 1 (RSC1A1), also called transporter regulator RS1 (RS1) which mediates transcriptional and post-transcriptional regulation of Na(+)-D-glucose cotransporter SGLT1. Pssm-ID: 270494 Cd Length: 36 Bit Score: 42.13 E-value: 4.56e-05
|
||||||||||
| UBA_GAWKY | cd14284 | UBA domain found in Drosophila melanogaster protein Gawky (GW) and similar proteins; GW is the ... |
938-972 | 5.32e-05 | ||||||
UBA domain found in Drosophila melanogaster protein Gawky (GW) and similar proteins; GW is the D. melanogaster GW182 homolog (dGW182) which belongs to the GW182 protein family. The GW182 proteins directly interact with Argonaute (Ago) proteins, and thus function as downstream effectors in the miRNA pathway, responsible for inhibition of translation and acceleration of mRNA decay. They are characterized by an abnormally high content of glycine/tryptophan (G/W) repeats, one or more glutamine (Q)-rich motifs, and a C-terminal RNA recognition motif (RRM), also called RBD (RNA binding domain) or RNP (ribonucleoprotein domain). The GW182 proteins are recruited to miRNA targets through an interaction between their N-terminal domain and an Argonaute protein. Then they promote translational repression and/or degradation of miRNA targets through their C-terminal silencing domain. In addition to a G/W repeats region, a Q-rich region, and a RRM domain, GW also contains a ubiquitin-associated domain (UBA). Pssm-ID: 270470 [Multi-domain] Cd Length: 35 Bit Score: 41.62 E-value: 5.32e-05
|
||||||||||
| UBA | smart00165 | Ubiquitin associated domain; Present in Rad23, SNF1-like kinases. The newly-found UBA in p62 ... |
941-973 | 5.79e-05 | ||||||
Ubiquitin associated domain; Present in Rad23, SNF1-like kinases. The newly-found UBA in p62 is known to bind ubiquitin. Pssm-ID: 197551 [Multi-domain] Cd Length: 37 Bit Score: 41.70 E-value: 5.79e-05
|
||||||||||
| UBA_TDRD3 | cd14282 | UBA domain of Tudor domain-containing protein 3 (TDRD3) and similar proteins; TDRD3 is a ... |
939-973 | 1.33e-04 | ||||||
UBA domain of Tudor domain-containing protein 3 (TDRD3) and similar proteins; TDRD3 is a modular protein containing Tudor domain, a DUF/OB-fold motif and a ubiquitin-associated (UBA) domain. It shows both nucleic acid- and methyl-binding properties and can interact with methylated RNA-binding proteins, such as fragile X mental retardation protein (FMRP) and DEAD/H box-3 (also known as DDX3X/Y, DBX/Y, HLP2 and DDX14) which is implicated in human genetic diseases. At this point, TDRD3 may play a central role in RNA processing regulatory pathways involving arginine methylation. TDRD3 localizes predominantly to the cytoplasm stress granules (SGs). The Tudor domain is essential and sufficient for its recruitment to SGs. Pssm-ID: 270468 Cd Length: 39 Bit Score: 41.00 E-value: 1.33e-04
|
||||||||||
| UBA_UBAC2 | cd14305 | UBA domain found in ubiquitin-associated domain-containing protein 2 (UBAC2) and similar ... |
941-973 | 1.66e-04 | ||||||
UBA domain found in ubiquitin-associated domain-containing protein 2 (UBAC2) and similar proteins; UBAC2, also called phosphoglycerate dehydrogenase-like protein 1, is a ubiquitin-associated domain (UBA)-domain containing protein encoded by gene UBAC2 (or PHGDHL1), a risk gene for Behcet's disease (BD). It may play an important role in the development of BD through its transcriptional modulation. Members in this family contain an N-terminal rhomboid-like domain and a C-terminal UBA domain. Pssm-ID: 270490 Cd Length: 38 Bit Score: 40.41 E-value: 1.66e-04
|
||||||||||
| UBA1_atUBP14 | cd14295 | UBA1 domain found in Arabidopsis thaliana ubiquitin carboxyl-terminal hydrolase 14 (atUBP14) ... |
937-980 | 1.89e-04 | ||||||
UBA1 domain found in Arabidopsis thaliana ubiquitin carboxyl-terminal hydrolase 14 (atUBP14) and similar proteins; atUBP14, also called deubiquitinating enzyme 14, TITAN-6 protein, ubiquitin thioesterase 14, or ubiquitin-specific-processing protease 14, is related to the isopeptidase T class of deubiquitinating enzymes that recycle polyubiquitin chains following protein degradation. atUBP14 is essential for early plant development. It can disassemble multi-ubiquitin chains linked internally via epsilon-amino isopeptide bonds using Lys48 and can process some, but not all, translational fusions of ubiquitin linked via alpha-amino peptide bonds. atUBP14 contains two ubiquitin-association (UBA) domains. This model corresponds to the UBA1 domain. Pssm-ID: 270481 [Multi-domain] Cd Length: 45 Bit Score: 40.43 E-value: 1.89e-04
|
||||||||||
| UBA_II_E2_UBE2K_like | cd14313 | UBA domain found in vertebrate ubiquitin-conjugating enzyme E2 K (UBE2K), Drosophila ... |
939-973 | 2.14e-04 | ||||||
UBA domain found in vertebrate ubiquitin-conjugating enzyme E2 K (UBE2K), Drosophila melanogaster ubiquitin-conjugating enzyme E2-22 kDa (UbcD4) and similar proteins; UBE2K, also called Huntingtin-interacting protein 2 (HIP-2), ubiquitin carrier protein, ubiquitin-conjugating enzyme E2-25 kDa (E2-25K), or ubiquitin-protein ligase, is a multi-ubiquitinating enzyme with the ability to synthesize Lys48-linked polyubiquitin chains which is involved in the ubiquitin (Ub)-dependent proteolytic pathway. It interacts with the frameshift mutant of ubiquitin B and functions as a crucial factor regulating amyloid-beta neurotoxicity. It has also been characterized as Huntingtin-interacting protein that modulates the neurotoxicity of Amyloid-beta (Abeta), the principal protein involved in Alzheimer's disease pathogenesis. Moreover, E2-25K increases aggregate the formation of expanded polyglutamine proteins and polyglutamine-induced cell death in the pathology of polyglutamine diseases. UbcD4, also called ubiquitin carrier protein, or ubiquitin-protein ligase, is encoded by Drosophila E2 gene which is only expressed in pole cells in embryos. It is a putative E2 enzyme homologous to the Huntingtin interacting protein-2 (HIP2) of human. UbcD4 specifically interacts with the polyubiquitin-binding subunit of the proteasome. This family also includes a putative ubiquitin conjugating enzyme from plasmodium Yoelii (pyUCE). It shows a high level of sequence similarity with UBE2K and may also plays a role in the ubiquitin-mediated protein degradation pathway. All family members are class II E2 conjugating enzymes which contain a C-terminal ubiquitin-associated (UBA) domain in addition to an N-terminal catalytic ubiquitin-conjugating enzyme E2 (UBCc) domain. Pssm-ID: 270498 Cd Length: 36 Bit Score: 40.00 E-value: 2.14e-04
|
||||||||||
| UBA | pfam00627 | UBA/TS-N domain; This small domain is composed of three alpha helices. This family includes ... |
941-969 | 2.61e-04 | ||||||
UBA/TS-N domain; This small domain is composed of three alpha helices. This family includes the previously defined UBA and TS-N domains. The UBA-domain (ubiquitin associated domain) is a novel sequence motif found in several proteins having connections to ubiquitin and the ubiquitination pathway. The structure of the UBA domain consists of a compact three helix bundle. This domain is found at the N terminus of EF-TS hence the name TS-N. The structure of EF-TS is known and this domain is implicated in its interaction with EF-TU. The domain has been found in non EF-TS proteins such as alpha-NAC and MJ0280. Pssm-ID: 395502 [Multi-domain] Cd Length: 37 Bit Score: 39.73 E-value: 2.61e-04
|
||||||||||
| COG4625 | COG4625 | Uncharacterized conserved protein, contains a C-terminal beta-barrel porin domain [Function ... |
2-379 | 3.46e-04 | ||||||
Uncharacterized conserved protein, contains a C-terminal beta-barrel porin domain [Function unknown]; Pssm-ID: 443664 [Multi-domain] Cd Length: 900 Bit Score: 45.54 E-value: 3.46e-04
|
||||||||||
| UBA_Mud1_like | cd14308 | UBA domain found in Schizosaccharomyces pombe UBA domain-containing protein mud1 and similar ... |
940-973 | 9.15e-04 | ||||||
UBA domain found in Schizosaccharomyces pombe UBA domain-containing protein mud1 and similar proteins; Schizosaccharomyces pombe mud1 is an ortholog of the Saccharomyces cerevisiae DNA-damage response protein Ddi1. S. cerevisiae Ddi1, also called v-SNARE-master 1 (Vsm1), belongs to a family of proteins known as the ubiquitin receptors which can bind ubiquitinated substrates and the proteasome. It is involved in the degradation of the F-box protein Ufo1, involved in the G1/S transition. It also participates in Mec1-mediated degradation of Ho endonuclease. Both S. pombe mud1 and S. cerevisiae Ddi1 contain an N-terminal ubiquitin-like (UBL) domain, an aspartyl protease-like domain, and a C-terminal ubiquitin-associated (UBA) domain. S. pombe mud1 binds to K48-linked polyubiquitin (polyUb) through UBA domain. Pssm-ID: 270493 Cd Length: 36 Bit Score: 38.25 E-value: 9.15e-04
|
||||||||||
| UBA_atUPL1_2_like | cd14327 | UBA domain found in Arabidopsis thaliana E3 ubiquitin-protein ligase UPL1 (atUPL1), UPL2 ... |
939-973 | 9.84e-04 | ||||||
UBA domain found in Arabidopsis thaliana E3 ubiquitin-protein ligase UPL1 (atUPL1), UPL2 (atUPL2) and similar proteins; The family includes two highly similar 405-kDa HECT E3 ubiquitin-protein ligases (UPLs), UPL1 and UPL2, from Arabidopsis thaliana. The HECT E3 UPL family plays a prominent role in the ubiquitination of plant proteins. The biological functions of UPL1 and UPL2 remain unclear. Both of them contain a ubiquitin-associated (UBA) domain and a C-terminal HECT domain. UBA domain may be involved in ubiquitin metabolism. HECT domain is necessary and sufficient for their E3 catalytic activity, but requires ATP, E1 and an E2 of the Arabidopsis UBC8 family to ubiquitinate proteins. Pssm-ID: 270512 [Multi-domain] Cd Length: 38 Bit Score: 38.44 E-value: 9.84e-04
|
||||||||||
| UBA_UBXN1 | cd14302 | UBA domain found in UBX domain-containing protein 1 (UBXN1) and similar proteins; UBXN1, also ... |
941-974 | 1.22e-03 | ||||||
UBA domain found in UBX domain-containing protein 1 (UBXN1) and similar proteins; UBXN1, also called SAPK substrate protein 1 (SAKS1) or UBA/UBX 33.3 kDa protein, is a widely expressed protein containing an N-terminal ubiquitin-associated (UBA) domain, a coiled-coil region, and a C-terminal ubiquitin-like (UBX) domain. It binds polyubiquitin and valosin-containing protein (VCP), and has been identified as a substrate for stress-activated protein kinases (SAPKs). Moreover, UBXN1 specifically binds to Homer2b. It may also interact with ubiquitin (Ub) and may be involved in the Ub-proteasome proteolytic pathways. In addition, UBXN1 can associate with autoubiquitinated BRCA1 tumor suppressor and inhibit its enzymatic function through its UBA domain. Pssm-ID: 270487 [Multi-domain] Cd Length: 41 Bit Score: 38.04 E-value: 1.22e-03
|
||||||||||
| UBA1_scUBP14_like | cd14296 | UBA1 domain found in Saccharomyces cerevisiae ubiquitin carboxyl-terminal hydrolase 14 ... |
940-974 | 2.16e-03 | ||||||
UBA1 domain found in Saccharomyces cerevisiae ubiquitin carboxyl-terminal hydrolase 14 (scUBP14) and similar proteins; scUBP14, also called deubiquitinating enzyme 14, glucose-induced degradation protein 6, ubiquitin thioesterase 14, or ubiquitin-specific-processing protease 14, is the yeast ortholog of human Isopeptidase T (USP5), a deubiquitinating enzyme known to bind the 29-linked polyubiquitin chains. scUBP14 has been identified as a K29-linked polyubiquitin binding protein as well. It is involved in K29-linked polyubiquitin metabolism by binding to the 29-linked Ub4 resin and serving as an internal positive control in budding yeast. Members in this family contain two tandem ubiquitin-association (UBA) domains. This model corresponds to the UBA1 domain. Pssm-ID: 270482 [Multi-domain] Cd Length: 39 Bit Score: 37.23 E-value: 2.16e-03
|
||||||||||
| UBA_RUP1p | cd14307 | UBA domain found in yeast UBA domain-containing protein RUP1p and similar proteins; RUP1p is a ... |
941-975 | 4.03e-03 | ||||||
UBA domain found in yeast UBA domain-containing protein RUP1p and similar proteins; RUP1p is a ubiquitin-associated (UBA) domain-containing protein encoded by a nonessential yeast gene RUP1. It can mediate the association of Rsp5 and Ubp2. The N-terminal UBA domain is responsible for antagonizing Rsp5 function, as well as bridging the Rsp5-Ubp2 interaction. No other characterized functional domains or motifs are found in RUP1p. Pssm-ID: 270492 Cd Length: 38 Bit Score: 36.50 E-value: 4.03e-03
|
||||||||||
| RRM_RCAN_like | cd12434 | RNA recognition motif (RRM) found in regulators of calcineurin (RCANs) and similar proteins; ... |
1572-1628 | 4.42e-03 | ||||||
RNA recognition motif (RRM) found in regulators of calcineurin (RCANs) and similar proteins; This subfamily corresponds to the RRM of RCANs, a novel family of calcineurin regulators that are key factors contributing to Down syndrome in humans. They can stimulate and inhibit the Ca2+/calmodulin-dependent phosphatase calcineurin (also termed PP2B or PP3C) signaling in vivo through direct interactions with its catalytic subunit. Overexpressed RCANs may bind and inhibit calcineurin. In contrast, low levels of phosphorylated RCANs may stimulate the calcineurin signaling. RCANs are characterized by harboring a central short, unique serine-proline motif containing FLIISPPxSPP box, which is strongly conserved from yeast to human but is absent in bacteria. They consist of an N-terminal RNA recognition motif (RRM), also termed RBD (RNA binding domain) or RNP (ribonucleoprotein domain), a highly conserved SP repeat domain containing the phosphorylation site by GSK-3, a well-known PxIxIT motif responsible for docking many substrates to calcineurin, and an unrecognized C-terminal TxxP motif of unknown function. Pssm-ID: 409868 [Multi-domain] Cd Length: 75 Bit Score: 37.60 E-value: 4.42e-03
|
||||||||||
| UBA1_UBP5_like | cd14294 | UBA1 domain found in ubiquitin carboxyl-terminal hydrolase UBP5, UBP13 and similar proteins; ... |
940-980 | 5.48e-03 | ||||||
UBA1 domain found in ubiquitin carboxyl-terminal hydrolase UBP5, UBP13 and similar proteins; UBP5, also called deubiquitinating enzyme 5, Isopeptidase T (IsoT), ubiquitin thioesterase 5, or ubiquitin-specific-processing protease 5, is a deubiquitinating enzyme largely responsible for the disassembly of the majority of unanchored polyubiquitin in the cell. Zinc is required for its catalytic activity. UBP5 contains four ubiquitin (Ub)-binding sites including an N-terminal zinc finger (ZnF) domain, a catalytic ubiquitin-specific processing protease (UBP) domain (catalytic C-box and H-box), and two ubiquitin-associated (UBA) domains. ZnF domain binds the proximal ubiquitin. UBP domain forms the active site. UBA domains are involved in binding linear or K48-linked polyubiquitin. UBP13, also called deubiquitinating enzyme 13, Isopeptidase T-3 (isoT3), ubiquitin thioesterase 13, or ubiquitin-specific-processing protease 13, is an ortholog of UBP5. It has similar domain architecture, but functions differently from USP5 in cellular deubiquitination processes. It exhibits a weak deubiquitinating activity preferring to Lys63-linked polyubiquitin in a non-activation manner. Moreover, the zinc finger (ZnF) domain of USP13 cannot bind to Ub. Its tandem UBA domains can bind with different types of diUb but preferentially with K63-linked.USP13 can also regulate the protein level of CD3delta in cells via its UBA domains. This model corresponds to the UBA1 domain. Pssm-ID: 270480 [Multi-domain] Cd Length: 44 Bit Score: 36.52 E-value: 5.48e-03
|
||||||||||
| UBA_II_E2_UBC27_like | cd14312 | UBA domain found in plant ubiquitin-conjugating enzyme E2 27 and similar proteins; UBC27, also ... |
941-973 | 6.36e-03 | ||||||
UBA domain found in plant ubiquitin-conjugating enzyme E2 27 and similar proteins; UBC27, also called ubiquitin carrier protein 27, functions as a class II ubiquitin-conjugating (UBC) enzyme (E2). E2, together with E1 (ubiquitin-activating enzyme UBA) and E3 (ubiquitin ligase), is required in the multi-step reaction of ubiquitin conjugation. Unlike other Arabidopsis UBCs, in addition to an N-terminal ubiquitin-conjugating enzyme E2 catalytic domain (UBCc), UBC27 has an additional C-terminal ubiquitin-associated domain (UBA). Pssm-ID: 270497 Cd Length: 36 Bit Score: 35.78 E-value: 6.36e-03
|
||||||||||
| RRM2_RBM28_like | cd12414 | RNA recognition motif 2 (RRM2) found in RNA-binding protein 28 (RBM28) and similar proteins; ... |
1560-1628 | 7.25e-03 | ||||||
RNA recognition motif 2 (RRM2) found in RNA-binding protein 28 (RBM28) and similar proteins; This subfamily corresponds to the RRM2 of RBM28 and Nop4p. RBM28 is a specific nucleolar component of the spliceosomal small nuclear ribonucleoproteins (snRNPs), possibly coordinating their transition through the nucleolus. It specifically associates with U1, U2, U4, U5, and U6 small nuclear RNAs (snRNAs), and may play a role in the maturation of both small nuclear and ribosomal RNAs. RBM28 has four RNA recognition motifs (RRMs), also termed RBDs (RNA binding domains) or RNPs (ribonucleoprotein domains), and an extremely acidic region between RRM2 and RRM3. The family also includes nucleolar protein 4 (Nop4p or Nop77p) encoded by YPL043W from Saccharomyces cerevisiae. It is an essential nucleolar protein involved in processing and maturation of 27S pre-rRNA and biogenesis of 60S ribosomal subunits. Nop4p also contains four RRMs. Pssm-ID: 409848 [Multi-domain] Cd Length: 76 Bit Score: 37.15 E-value: 7.25e-03
|
||||||||||
| RRM_1 | pfam00076 | RNA recognition motif. (a.k.a. RRM, RBD, or RNP domain); The RRM motif is probably diagnostic ... |
1560-1624 | 7.54e-03 | ||||||
RNA recognition motif. (a.k.a. RRM, RBD, or RNP domain); The RRM motif is probably diagnostic of an RNA binding protein. RRMs are found in a variety of RNA binding proteins, including various hnRNP proteins, proteins implicated in regulation of alternative splicing, and protein components of snRNPs. The motif also appears in a few single stranded DNA binding proteins. The RRM structure consists of four strands and two helices arranged in an alpha/beta sandwich, with a third helix present during RNA binding in some cases The C-terminal beta strand (4th strand) and final helix are hard to align and have been omitted in the SEED alignment The LA proteins have an N terminal rrm which is included in the seed. There is a second region towards the C terminus that has some features characteriztic of a rrm but does not appear to have the important structural core of a rrm. The LA proteins are one of the main autoantigens in Systemic lupus erythematosus (SLE), an autoimmune disease. Pssm-ID: 425453 [Multi-domain] Cd Length: 70 Bit Score: 36.83 E-value: 7.54e-03
|
||||||||||
| UBA_II_E2_UBCD4 | cd14391 | UBA domain found in Drosophila melanogaster ubiquitin-conjugating enzyme E2-22 kDa (UbcD4) and ... |
941-973 | 7.89e-03 | ||||||
UBA domain found in Drosophila melanogaster ubiquitin-conjugating enzyme E2-22 kDa (UbcD4) and similar proteins; UbcD4, also called ubiquitin carrier protein or ubiquitin-protein ligase, is a class II E2 ubiquitin-conjugating enzyme encoded by Drosophila E2 gene which is only expressed in pole cells in embryos. It is a putative E2 enzyme homologous to the Huntingtin interacting protein-2 (HIP2) of human. UbcD4 specifically interacts with the polyubiquitin-binding subunit of the proteasome. It contains a C-terminal ubiquitin-associated (UBA) domain in addition to an N-terminal catalytic ubiquitin-conjugating enzyme E2 (UBCc) domain. Pssm-ID: 270574 Cd Length: 36 Bit Score: 35.74 E-value: 7.89e-03
|
||||||||||
| UBA2_KPC2 | cd14304 | UBA2 domain found in Kip1 ubiquitination-promoting complex protein 2 (KPC2) and similar ... |
939-973 | 9.98e-03 | ||||||
UBA2 domain found in Kip1 ubiquitination-promoting complex protein 2 (KPC2) and similar proteins; KPC2, also called ubiquitin-associated domain-containing protein 1 (UBAC1), or glialblastoma cell differentiation-related protein 1, is one of two subunits of Kip1 ubiquitination-promoting complex (KPC), a novel E3 ubiquitin-protein ligase that also contains KPC1 subunit and regulates the ubiquitin-dependent degradation of the cyclin-dependent kinase (CDK) inhibitor p27 at G1 phase. KPC2 contains a ubiquitin-like (UBL) domain and two ubiquitin-associated (UBA) domains. This model corresponds to the UBA2 domain. Pssm-ID: 270489 Cd Length: 39 Bit Score: 35.31 E-value: 9.98e-03
|
||||||||||
| Blast search parameters | ||||
|
