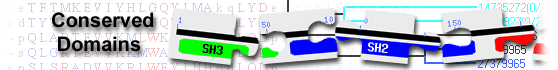


NEDD4-like E3 ubiquitin-protein ligase WWP1 [Homo sapiens]
Protein Classification

List of domain hits
| Name | Accession | Description | Interval | E-value | ||||||||||
| HUL4 super family | cl34867 | Ubiquitin-protein ligase [Posttranslational modification, protein turnover, chaperones]; |
307-922 | 5.27e-170 | ||||||||||
Ubiquitin-protein ligase [Posttranslational modification, protein turnover, chaperones]; The actual alignment was detected with superfamily member COG5021: Pssm-ID: 227354 [Multi-domain] Cd Length: 872 Bit Score: 517.01 E-value: 5.27e-170
|
||||||||||||||
| C2_E3_ubiquitin_ligase | cd04021 | C2 domain present in E3 ubiquitin ligase; E3 ubiquitin ligase is part of the ubiquitylation ... |
17-140 | 1.47e-54 | ||||||||||
C2 domain present in E3 ubiquitin ligase; E3 ubiquitin ligase is part of the ubiquitylation mechanism responsible for controlling surface expression of membrane proteins. The sequential action of several enzymes are involved: ubiquitin-activating enzyme E1, ubiquitin-conjugating enzyme E2, and ubiquitin-protein ligase E3 which is responsible for substrate recognition and promoting the transfer of ubiquitin to the target protein. E3 ubiquitin ligase is composed of an N-terminal C2 domain, 4 WW domains, and a HECTc domain. C2 domains fold into an 8-standed beta-sandwich that can adopt 2 structural arrangements: Type I and Type II, distinguished by a circular permutation involving their N- and C-terminal beta strands. Many C2 domains are Ca2+-dependent membrane-targeting modules that bind a wide variety of substances including bind phospholipids, inositol polyphosphates, and intracellular proteins. Most C2 domain proteins are either signal transduction enzymes that contain a single C2 domain, such as protein kinase C, or membrane trafficking proteins which contain at least two C2 domains, such as synaptotagmin 1. However, there are a few exceptions to this including RIM isoforms and some splice variants of piccolo/aczonin and intersectin which only have a single C2 domain. C2 domains with a calcium binding region have negatively charged residues, primarily aspartates, that serve as ligands for calcium ions. : Pssm-ID: 175988 [Multi-domain] Cd Length: 125 Bit Score: 184.79 E-value: 1.47e-54
|
||||||||||||||
| SP1-4_N super family | cl41773 | N-terminal domain of transcription factor Specificity Proteins (SP) 1-4; Specificity Proteins ... |
236-344 | 4.37e-04 | ||||||||||
N-terminal domain of transcription factor Specificity Proteins (SP) 1-4; Specificity Proteins (SPs) are transcription factors that are involved in many cellular processes, including cell differentiation, cell growth, apoptosis, immune responses, response to DNA damage, and chromatin remodeling. There are many SPs in vertebrates (9 SPs in humans and mice, 7 SPs in chicken, and 11 SPs in teleost fish), but arthropods only have 3 SPs. SPs belong to a family of proteins, called the SP/Kruppel or Krueppel-like Factor (KLF) family, characterized by a C-terminal DNA-binding domain of 81 amino acids consisting of three Kruppel-like C2H2 zinc fingers. These factors bind to a loose consensus motif, namely NNRCRCCYY (where N is any nucleotide; R is A/G, and Y is C/T), such as the recurring motifs in GC and GT boxes (5'-GGGGCGGGG-3' and 5-GGTGTGGGG-3') that are present in promoters and more distal regulatory elements of mammalian genes. SP factors preferentially bind GC boxes, while KLFs bind CACCC boxes. Another characteristic hallmark of SP factors is the presence of the Buttonhead (BTD) box CXCPXC, just N-terminal to the zinc fingers. The function of the BTD box is unknown, but it is thought to play an important physiological role. Another feature of most SP factors is the presence of a conserved amino acid stretch, the so-called SP box, located close to the N-terminus. SP factors may be separated into three groups based on their domain architecture and the similarity of their N-terminal transactivation domains: SP1-4, SP5, and SP6-9. The transactivation domains between the three groups are not homologous to one another. SP1-4 have similar N-terminal transactivation domains characterized by glutamine-rich regions, which, in most cases, have adjacent serine/threonine-rich regions. This model represents the N-terminal domain of SP1-4. The actual alignment was detected with superfamily member cd22536: Pssm-ID: 425404 [Multi-domain] Cd Length: 623 Bit Score: 44.14 E-value: 4.37e-04
|
||||||||||||||
| Name | Accession | Description | Interval | E-value | ||||||||||
| HUL4 | COG5021 | Ubiquitin-protein ligase [Posttranslational modification, protein turnover, chaperones]; |
307-922 | 5.27e-170 | ||||||||||
Ubiquitin-protein ligase [Posttranslational modification, protein turnover, chaperones]; Pssm-ID: 227354 [Multi-domain] Cd Length: 872 Bit Score: 517.01 E-value: 5.27e-170
|
||||||||||||||
| HECTc | cd00078 | HECT domain; C-terminal catalytic domain of a subclass of Ubiquitin-protein ligase (E3). It ... |
568-920 | 8.41e-170 | ||||||||||
HECT domain; C-terminal catalytic domain of a subclass of Ubiquitin-protein ligase (E3). It binds specific ubiquitin-conjugating enzymes (E2), accepts ubiquitin from E2, transfers ubiquitin to substrate lysine side chains, and transfers additional ubiquitin molecules to the end of growing ubiquitin chains. Pssm-ID: 238033 [Multi-domain] Cd Length: 352 Bit Score: 497.47 E-value: 8.41e-170
|
||||||||||||||
| HECTc | smart00119 | Domain Homologous to E6-AP Carboxyl Terminus with; E3 ubiquitin-protein ligases. Can bind to ... |
591-919 | 4.94e-159 | ||||||||||
Domain Homologous to E6-AP Carboxyl Terminus with; E3 ubiquitin-protein ligases. Can bind to E2 enzymes. Pssm-ID: 214523 Cd Length: 328 Bit Score: 469.02 E-value: 4.94e-159
|
||||||||||||||
| HECT | pfam00632 | HECT-domain (ubiquitin-transferase); The name HECT comes from Homologous to the E6-AP Carboxyl ... |
617-920 | 1.32e-119 | ||||||||||
HECT-domain (ubiquitin-transferase); The name HECT comes from Homologous to the E6-AP Carboxyl Terminus. Pssm-ID: 459880 Cd Length: 304 Bit Score: 366.16 E-value: 1.32e-119
|
||||||||||||||
| C2_E3_ubiquitin_ligase | cd04021 | C2 domain present in E3 ubiquitin ligase; E3 ubiquitin ligase is part of the ubiquitylation ... |
17-140 | 1.47e-54 | ||||||||||
C2 domain present in E3 ubiquitin ligase; E3 ubiquitin ligase is part of the ubiquitylation mechanism responsible for controlling surface expression of membrane proteins. The sequential action of several enzymes are involved: ubiquitin-activating enzyme E1, ubiquitin-conjugating enzyme E2, and ubiquitin-protein ligase E3 which is responsible for substrate recognition and promoting the transfer of ubiquitin to the target protein. E3 ubiquitin ligase is composed of an N-terminal C2 domain, 4 WW domains, and a HECTc domain. C2 domains fold into an 8-standed beta-sandwich that can adopt 2 structural arrangements: Type I and Type II, distinguished by a circular permutation involving their N- and C-terminal beta strands. Many C2 domains are Ca2+-dependent membrane-targeting modules that bind a wide variety of substances including bind phospholipids, inositol polyphosphates, and intracellular proteins. Most C2 domain proteins are either signal transduction enzymes that contain a single C2 domain, such as protein kinase C, or membrane trafficking proteins which contain at least two C2 domains, such as synaptotagmin 1. However, there are a few exceptions to this including RIM isoforms and some splice variants of piccolo/aczonin and intersectin which only have a single C2 domain. C2 domains with a calcium binding region have negatively charged residues, primarily aspartates, that serve as ligands for calcium ions. Pssm-ID: 175988 [Multi-domain] Cd Length: 125 Bit Score: 184.79 E-value: 1.47e-54
|
||||||||||||||
| C2 | pfam00168 | C2 domain; |
19-103 | 4.07e-12 | ||||||||||
C2 domain; Pssm-ID: 425499 [Multi-domain] Cd Length: 104 Bit Score: 63.49 E-value: 4.07e-12
|
||||||||||||||
| C2 | smart00239 | Protein kinase C conserved region 2 (CalB); Ca2+-binding motif present in phospholipases, ... |
19-111 | 1.38e-09 | ||||||||||
Protein kinase C conserved region 2 (CalB); Ca2+-binding motif present in phospholipases, protein kinases C, and synaptotagmins (among others). Some do not appear to contain Ca2+-binding sites. Particular C2s appear to bind phospholipids, inositol polyphosphates, and intracellular proteins. Unusual occurrence in perforin. Synaptotagmin and PLC C2s are permuted in sequence with respect to N- and C-terminal beta strands. SMART detects C2 domains using one or both of two profiles. Pssm-ID: 214577 [Multi-domain] Cd Length: 101 Bit Score: 55.96 E-value: 1.38e-09
|
||||||||||||||
| SP4_N | cd22536 | N-terminal domain of transcription factor Specificity Protein (SP) 4; Specificity Proteins ... |
236-344 | 4.37e-04 | ||||||||||
N-terminal domain of transcription factor Specificity Protein (SP) 4; Specificity Proteins (SPs) are transcription factors that are involved in many cellular processes, including cell differentiation, cell growth, apoptosis, immune responses, response to DNA damage, and chromatin remodeling. Human SP4 is a risk gene of multiple psychiatric disorders including schizophrenia, bipolar disorder, and major depression. SP4 belongs to a family of proteins, called the SP/Kruppel or Krueppel-like Factor (KLF) family, characterized by a C-terminal DNA-binding domain of 81 amino acids consisting of three Kruppel-like C2H2 zinc fingers. These factors bind to a loose consensus motif, namely NNRCRCCYY (where N is any nucleotide; R is A/G, and Y is C/T), such as the recurring motifs in GC and GT boxes (5'-GGGGCGGGG-3' and 5-GGTGTGGGG-3') that are present in promoters and more distal regulatory elements of mammalian genes. SP factors preferentially bind GC boxes, while KLFs bind CACCC boxes. Another characteristic hallmark of SP factors is the presence of the Buttonhead (BTD) box CXCPXC, just N-terminal to the zinc fingers. The function of the BTD box is unknown, but it is thought to play an important physiological role. Another feature of most SP factors is the presence of a conserved amino acid stretch, the so-called SP box, located close to the N-terminus. SP factors may be separated into three groups based on their domain architecture and the similarity of their N-terminal transactivation domains: SP1-4, SP5, and SP6-9. The transactivation domains between the three groups are not homologous to one another. SP1-4 have similar N-terminal transactivation domains characterized by glutamine-rich regions, which, in most cases, have adjacent serine/threonine-rich regions. This model represents the N-terminal domain of SP4. Pssm-ID: 411773 [Multi-domain] Cd Length: 623 Bit Score: 44.14 E-value: 4.37e-04
|
||||||||||||||
| Name | Accession | Description | Interval | E-value | ||||||||||
| HUL4 | COG5021 | Ubiquitin-protein ligase [Posttranslational modification, protein turnover, chaperones]; |
307-922 | 5.27e-170 | ||||||||||
Ubiquitin-protein ligase [Posttranslational modification, protein turnover, chaperones]; Pssm-ID: 227354 [Multi-domain] Cd Length: 872 Bit Score: 517.01 E-value: 5.27e-170
|
||||||||||||||
| HECTc | cd00078 | HECT domain; C-terminal catalytic domain of a subclass of Ubiquitin-protein ligase (E3). It ... |
568-920 | 8.41e-170 | ||||||||||
HECT domain; C-terminal catalytic domain of a subclass of Ubiquitin-protein ligase (E3). It binds specific ubiquitin-conjugating enzymes (E2), accepts ubiquitin from E2, transfers ubiquitin to substrate lysine side chains, and transfers additional ubiquitin molecules to the end of growing ubiquitin chains. Pssm-ID: 238033 [Multi-domain] Cd Length: 352 Bit Score: 497.47 E-value: 8.41e-170
|
||||||||||||||
| HECTc | smart00119 | Domain Homologous to E6-AP Carboxyl Terminus with; E3 ubiquitin-protein ligases. Can bind to ... |
591-919 | 4.94e-159 | ||||||||||
Domain Homologous to E6-AP Carboxyl Terminus with; E3 ubiquitin-protein ligases. Can bind to E2 enzymes. Pssm-ID: 214523 Cd Length: 328 Bit Score: 469.02 E-value: 4.94e-159
|
||||||||||||||
| HECT | pfam00632 | HECT-domain (ubiquitin-transferase); The name HECT comes from Homologous to the E6-AP Carboxyl ... |
617-920 | 1.32e-119 | ||||||||||
HECT-domain (ubiquitin-transferase); The name HECT comes from Homologous to the E6-AP Carboxyl Terminus. Pssm-ID: 459880 Cd Length: 304 Bit Score: 366.16 E-value: 1.32e-119
|
||||||||||||||
| C2_E3_ubiquitin_ligase | cd04021 | C2 domain present in E3 ubiquitin ligase; E3 ubiquitin ligase is part of the ubiquitylation ... |
17-140 | 1.47e-54 | ||||||||||
C2 domain present in E3 ubiquitin ligase; E3 ubiquitin ligase is part of the ubiquitylation mechanism responsible for controlling surface expression of membrane proteins. The sequential action of several enzymes are involved: ubiquitin-activating enzyme E1, ubiquitin-conjugating enzyme E2, and ubiquitin-protein ligase E3 which is responsible for substrate recognition and promoting the transfer of ubiquitin to the target protein. E3 ubiquitin ligase is composed of an N-terminal C2 domain, 4 WW domains, and a HECTc domain. C2 domains fold into an 8-standed beta-sandwich that can adopt 2 structural arrangements: Type I and Type II, distinguished by a circular permutation involving their N- and C-terminal beta strands. Many C2 domains are Ca2+-dependent membrane-targeting modules that bind a wide variety of substances including bind phospholipids, inositol polyphosphates, and intracellular proteins. Most C2 domain proteins are either signal transduction enzymes that contain a single C2 domain, such as protein kinase C, or membrane trafficking proteins which contain at least two C2 domains, such as synaptotagmin 1. However, there are a few exceptions to this including RIM isoforms and some splice variants of piccolo/aczonin and intersectin which only have a single C2 domain. C2 domains with a calcium binding region have negatively charged residues, primarily aspartates, that serve as ligands for calcium ions. Pssm-ID: 175988 [Multi-domain] Cd Length: 125 Bit Score: 184.79 E-value: 1.47e-54
|
||||||||||||||
| WW | pfam00397 | WW domain; The WW domain is a protein module with two highly conserved tryptophans that binds ... |
351-380 | 4.05e-13 | ||||||||||
WW domain; The WW domain is a protein module with two highly conserved tryptophans that binds proline-rich peptide motifs in vitro. Pssm-ID: 459800 [Multi-domain] Cd Length: 30 Bit Score: 64.06 E-value: 4.05e-13
|
||||||||||||||
| WW | smart00456 | Domain with 2 conserved Trp (W) residues; Also known as the WWP or rsp5 domain. Binds ... |
350-382 | 1.44e-12 | ||||||||||
Domain with 2 conserved Trp (W) residues; Also known as the WWP or rsp5 domain. Binds proline-rich polypeptides. Pssm-ID: 197736 [Multi-domain] Cd Length: 33 Bit Score: 62.23 E-value: 1.44e-12
|
||||||||||||||
| WW | cd00201 | Two conserved tryptophans domain; also known as the WWP or rsp5 domain; around 40 amino acids; ... |
352-382 | 1.97e-12 | ||||||||||
Two conserved tryptophans domain; also known as the WWP or rsp5 domain; around 40 amino acids; functions as an interaction module in a diverse set of signalling proteins; binds specific proline-rich sequences but at low affinities compared to other peptide recognition proteins such as antibodies and receptors; WW domains have a single groove formed by a conserved Trp and Tyr which recognizes a pair of residues of the sequence X-Pro; variable loops and neighboring domains confer specificity in this domain; there are five distinct groups based on binding: 1) PPXY motifs 2) the PPLP motif; 3) PGM motifs; 4) PSP or PTP motifs; 5) PR motifs. Pssm-ID: 238122 [Multi-domain] Cd Length: 31 Bit Score: 61.77 E-value: 1.97e-12
|
||||||||||||||
| WW | pfam00397 | WW domain; The WW domain is a protein module with two highly conserved tryptophans that binds ... |
458-487 | 3.02e-12 | ||||||||||
WW domain; The WW domain is a protein module with two highly conserved tryptophans that binds proline-rich peptide motifs in vitro. Pssm-ID: 459800 [Multi-domain] Cd Length: 30 Bit Score: 61.37 E-value: 3.02e-12
|
||||||||||||||
| C2 | pfam00168 | C2 domain; |
19-103 | 4.07e-12 | ||||||||||
C2 domain; Pssm-ID: 425499 [Multi-domain] Cd Length: 104 Bit Score: 63.49 E-value: 4.07e-12
|
||||||||||||||
| WW | cd00201 | Two conserved tryptophans domain; also known as the WWP or rsp5 domain; around 40 amino acids; ... |
459-488 | 1.13e-11 | ||||||||||
Two conserved tryptophans domain; also known as the WWP or rsp5 domain; around 40 amino acids; functions as an interaction module in a diverse set of signalling proteins; binds specific proline-rich sequences but at low affinities compared to other peptide recognition proteins such as antibodies and receptors; WW domains have a single groove formed by a conserved Trp and Tyr which recognizes a pair of residues of the sequence X-Pro; variable loops and neighboring domains confer specificity in this domain; there are five distinct groups based on binding: 1) PPXY motifs 2) the PPLP motif; 3) PGM motifs; 4) PSP or PTP motifs; 5) PR motifs. Pssm-ID: 238122 [Multi-domain] Cd Length: 31 Bit Score: 59.85 E-value: 1.13e-11
|
||||||||||||||
| WW | smart00456 | Domain with 2 conserved Trp (W) residues; Also known as the WWP or rsp5 domain. Binds ... |
457-488 | 1.16e-11 | ||||||||||
Domain with 2 conserved Trp (W) residues; Also known as the WWP or rsp5 domain. Binds proline-rich polypeptides. Pssm-ID: 197736 [Multi-domain] Cd Length: 33 Bit Score: 59.92 E-value: 1.16e-11
|
||||||||||||||
| C2 | cd00030 | C2 domain; The C2 domain was first identified in PKC. C2 domains fold into an 8-standed ... |
20-103 | 1.51e-11 | ||||||||||
C2 domain; The C2 domain was first identified in PKC. C2 domains fold into an 8-standed beta-sandwich that can adopt 2 structural arrangements: Type I and Type II, distinguished by a circular permutation involving their N- and C-terminal beta strands. Many C2 domains are Ca2+-dependent membrane-targeting modules that bind a wide variety of substances including bind phospholipids, inositol polyphosphates, and intracellular proteins. Most C2 domain proteins are either signal transduction enzymes that contain a single C2 domain, such as protein kinase C, or membrane trafficking proteins which contain at least two C2 domains, such as synaptotagmin 1. However, there are a few exceptions to this including RIM isoforms and some splice variants of piccolo/aczonin and intersectin which only have a single C2 domain. C2 domains with a calcium binding region have negatively charged residues, primarily aspartates, that serve as ligands for calcium ions. Pssm-ID: 175973 [Multi-domain] Cd Length: 102 Bit Score: 61.70 E-value: 1.51e-11
|
||||||||||||||
| C2 | smart00239 | Protein kinase C conserved region 2 (CalB); Ca2+-binding motif present in phospholipases, ... |
19-111 | 1.38e-09 | ||||||||||
Protein kinase C conserved region 2 (CalB); Ca2+-binding motif present in phospholipases, protein kinases C, and synaptotagmins (among others). Some do not appear to contain Ca2+-binding sites. Particular C2s appear to bind phospholipids, inositol polyphosphates, and intracellular proteins. Unusual occurrence in perforin. Synaptotagmin and PLC C2s are permuted in sequence with respect to N- and C-terminal beta strands. SMART detects C2 domains using one or both of two profiles. Pssm-ID: 214577 [Multi-domain] Cd Length: 101 Bit Score: 55.96 E-value: 1.38e-09
|
||||||||||||||
| WW | cd00201 | Two conserved tryptophans domain; also known as the WWP or rsp5 domain; around 40 amino acids; ... |
499-528 | 1.67e-08 | ||||||||||
Two conserved tryptophans domain; also known as the WWP or rsp5 domain; around 40 amino acids; functions as an interaction module in a diverse set of signalling proteins; binds specific proline-rich sequences but at low affinities compared to other peptide recognition proteins such as antibodies and receptors; WW domains have a single groove formed by a conserved Trp and Tyr which recognizes a pair of residues of the sequence X-Pro; variable loops and neighboring domains confer specificity in this domain; there are five distinct groups based on binding: 1) PPXY motifs 2) the PPLP motif; 3) PGM motifs; 4) PSP or PTP motifs; 5) PR motifs. Pssm-ID: 238122 [Multi-domain] Cd Length: 31 Bit Score: 50.99 E-value: 1.67e-08
|
||||||||||||||
| WW | smart00456 | Domain with 2 conserved Trp (W) residues; Also known as the WWP or rsp5 domain. Binds ... |
497-529 | 2.21e-08 | ||||||||||
Domain with 2 conserved Trp (W) residues; Also known as the WWP or rsp5 domain. Binds proline-rich polypeptides. Pssm-ID: 197736 [Multi-domain] Cd Length: 33 Bit Score: 50.68 E-value: 2.21e-08
|
||||||||||||||
| WW | pfam00397 | WW domain; The WW domain is a protein module with two highly conserved tryptophans that binds ... |
498-527 | 1.41e-07 | ||||||||||
WW domain; The WW domain is a protein module with two highly conserved tryptophans that binds proline-rich peptide motifs in vitro. Pssm-ID: 459800 [Multi-domain] Cd Length: 30 Bit Score: 48.27 E-value: 1.41e-07
|
||||||||||||||
| C2_Smurf-like | cd08382 | C2 domain present in Smad ubiquitination-related factor (Smurf)-like proteins; A single C2 ... |
20-99 | 1.12e-06 | ||||||||||
C2 domain present in Smad ubiquitination-related factor (Smurf)-like proteins; A single C2 domain is found in Smurf proteins, C2-WW-HECT-domain E3s, which play an important role in the downregulation of the TGF-beta signaling pathway. Smurf proteins also regulate cell shape, motility, and polarity by degrading small guanosine triphosphatases (GTPases). C2 domains fold into an 8-standed beta-sandwich that can adopt 2 structural arrangements: Type I and Type II, distinguished by a circular permutation involving their N- and C-terminal beta strands. Many C2 domains are Ca2+-dependent membrane-targeting modules that bind a wide variety of substances including bind phospholipids, inositol polyphosphates, and intracellular proteins. Most C2 domain proteins are either signal transduction enzymes that contain a single C2 domain, such as protein kinase C, or membrane trafficking proteins which contain at least two C2 domains, such as synaptotagmin 1. However, there are a few exceptions to this including RIM isoforms and some splice variants of piccolo/aczonin and intersectin which only have a single C2 domain. C2 domains with a calcium binding region have negatively charged residues, primarily aspartates, that serve as ligands for calcium ions. Members here have type-II topology. Pssm-ID: 176028 [Multi-domain] Cd Length: 123 Bit Score: 48.46 E-value: 1.12e-06
|
||||||||||||||
| C2_SRC2_like | cd04051 | C2 domain present in Soybean genes Regulated by Cold 2 (SRC2)-like proteins; SRC2 production ... |
20-103 | 3.05e-05 | ||||||||||
C2 domain present in Soybean genes Regulated by Cold 2 (SRC2)-like proteins; SRC2 production is a response to pathogen infiltration. The initial response of increased Ca2+ concentrations are coupled to downstream signal transduction pathways via calcium binding proteins. SRC2 contains a single C2 domain which localizes to the plasma membrane and is involved in Ca2+ dependent protein binding. C2 domains fold into an 8-standed beta-sandwich that can adopt 2 structural arrangements: Type I and Type II, distinguished by a circular permutation involving their N- and C-terminal beta strands. Many C2 domains are Ca2+-dependent membrane-targeting modules that bind a wide variety of substances including bind phospholipids, inositol polyphosphates, and intracellular proteins. Most C2 domain proteins are either signal transduction enzymes that contain a single C2 domain, such as protein kinase C, or membrane trafficking proteins which contain at least two C2 domains, such as synaptotagmin 1. However, there are a few exceptions to this including RIM isoforms and some splice variants of piccolo/aczonin and intersectin which only have a single C2 domain. C2 domains with a calcium binding region have negatively charged residues, primarily aspartates, that serve as ligands for calcium ions. Pssm-ID: 176016 [Multi-domain] Cd Length: 125 Bit Score: 44.53 E-value: 3.05e-05
|
||||||||||||||
| C2_C21orf25-like | cd08678 | C2 domain found in the Human chromosome 21 open reading frame 25 (C21orf25) protein; The ... |
52-137 | 1.19e-04 | ||||||||||
C2 domain found in the Human chromosome 21 open reading frame 25 (C21orf25) protein; The members in this cd are named after the Human C21orf25 which contains a single C2 domain. Several other members contain a C1 domain downstream of the C2 domain. No other information on this protein is currently known. The C2 domain was first identified in PKC. C2 domains fold into an 8-standed beta-sandwich that can adopt 2 structural arrangements: Type I and Type II, distinguished by a circular permutation involving their N- and C-terminal beta strands. Many C2 domains are Ca2+-dependent membrane-targeting modules that bind a wide variety of substances including bind phospholipids, inositol polyphosphates, and intracellular proteins. Most C2 domain proteins are either signal transduction enzymes that contain a single C2 domain, such as protein kinase C, or membrane trafficking proteins which contain at least two C2 domains, such as synaptotagmin 1. However, there are a few exceptions to this including RIM isoforms and some splice variants of piccolo/aczonin and intersectin which only have a single C2 domain. C2 domains with a calcium binding region have negatively charged residues, primarily aspartates, that serve as ligands for calcium ions. Pssm-ID: 176060 [Multi-domain] Cd Length: 126 Bit Score: 42.74 E-value: 1.19e-04
|
||||||||||||||
| C2_Munc13_fungal | cd04043 | C2 domain in Munc13 (mammalian uncoordinated) proteins; fungal group; C2-like domains are ... |
49-101 | 1.36e-04 | ||||||||||
C2 domain in Munc13 (mammalian uncoordinated) proteins; fungal group; C2-like domains are thought to be involved in phospholipid binding in a Ca2+ independent manner in both Unc13 and Munc13. Caenorabditis elegans Unc13 has a central domain with sequence similarity to PKC, which includes C1 and C2-related domains. Unc13 binds phorbol esters and DAG with high affinity in a phospholipid manner. Mutations in Unc13 results in abnormal neuronal connections and impairment in cholinergic neurotransmission in the nematode. Munc13 is the mammalian homolog which are expressed in the brain. There are 3 isoforms (Munc13-1, -2, -3) and are thought to play a role in neurotransmitter release and are hypothesized to be high-affinity receptors for phorbol esters. Unc13 and Munc13 contain both C1 and C2 domains. There are two C2 related domains present, one central and one at the carboxyl end. Munc13-1 contains a third C2-like domain. Munc13 interacts with syntaxin, synaptobrevin, and synaptotagmin suggesting a role for these as scaffolding proteins. C2 domains fold into an 8-standed beta-sandwich that can adopt 2 structural arrangements: Type I and Type II, distinguished by a circular permutation involving their N- and C-terminal beta strands. Many C2 domains are Ca2+-dependent membrane-targeting modules that bind a wide variety of substances including bind phospholipids, inositol polyphosphates, and intracellular proteins. Most C2 domain proteins are either signal transduction enzymes that contain a single C2 domain, such as protein kinase C, or membrane trafficking proteins which contain at least two C2 domains, such as synaptotagmin 1. However, there are a few exceptions to this including RIM isoforms and some splice variants of piccolo/aczonin and intersectin which only have a single C2 domain. C2 domains with a calcium binding region have negatively charged residues, primarily aspartates, that serve as ligands for calcium ions. This cd contains the second C2 repeat, C2B, and has a type-II topology. Pssm-ID: 176008 [Multi-domain] Cd Length: 126 Bit Score: 42.64 E-value: 1.36e-04
|
||||||||||||||
| C2_ArfGAP | cd04038 | C2 domain present in Arf GTPase Activating Proteins (GAP); ArfGAP is a GTPase activating ... |
52-117 | 2.20e-04 | ||||||||||
C2 domain present in Arf GTPase Activating Proteins (GAP); ArfGAP is a GTPase activating protein which regulates the ADP ribosylation factor Arf, a member of the Ras superfamily of GTP-binding proteins. The GTP-bound form of Arf is involved in Golgi morphology and is involved in recruiting coat proteins. ArfGAP is responsible for the GDP-bound form of Arf which is necessary for uncoating the membrane and allowing the Golgi to fuse with an acceptor compartment. These proteins contain an N-terminal ArfGAP domain containing the characteristic zinc finger motif (Cys-x2-Cys-x(16,17)-x2-Cys) and C-terminal C2 domain. C2 domains were first identified in Protein Kinase C (PKC). C2 domains fold into an 8-standed beta-sandwich that can adopt 2 structural arrangements: Type I and Type II, distinguished by a circular permutation involving their N- and C-terminal beta strands. Many C2 domains are Ca2+-dependent membrane-targeting modules that bind a wide variety of substances including bind phospholipids, inositol polyphosphates, and intracellular proteins. Most C2 domain proteins are either signal transduction enzymes that contain a single C2 domain, such as protein kinase C, or membrane trafficking proteins which contain at least two C2 domains, such as synaptotagmin 1. However, there are a few exceptions to this including RIM isoforms and some splice variants of piccolo/aczonin and intersectin which only have a single C2 domain. C2 domains with a calcium binding region have negatively charged residues, primarily aspartates, that serve as ligands for calcium ions. Pssm-ID: 176003 [Multi-domain] Cd Length: 145 Bit Score: 42.31 E-value: 2.20e-04
|
||||||||||||||
| PRP40 | COG5104 | Splicing factor [RNA processing and modification]; |
346-412 | 3.66e-04 | ||||||||||
Splicing factor [RNA processing and modification]; Pssm-ID: 227435 [Multi-domain] Cd Length: 590 Bit Score: 44.30 E-value: 3.66e-04
|
||||||||||||||
| SP4_N | cd22536 | N-terminal domain of transcription factor Specificity Protein (SP) 4; Specificity Proteins ... |
236-344 | 4.37e-04 | ||||||||||
N-terminal domain of transcription factor Specificity Protein (SP) 4; Specificity Proteins (SPs) are transcription factors that are involved in many cellular processes, including cell differentiation, cell growth, apoptosis, immune responses, response to DNA damage, and chromatin remodeling. Human SP4 is a risk gene of multiple psychiatric disorders including schizophrenia, bipolar disorder, and major depression. SP4 belongs to a family of proteins, called the SP/Kruppel or Krueppel-like Factor (KLF) family, characterized by a C-terminal DNA-binding domain of 81 amino acids consisting of three Kruppel-like C2H2 zinc fingers. These factors bind to a loose consensus motif, namely NNRCRCCYY (where N is any nucleotide; R is A/G, and Y is C/T), such as the recurring motifs in GC and GT boxes (5'-GGGGCGGGG-3' and 5-GGTGTGGGG-3') that are present in promoters and more distal regulatory elements of mammalian genes. SP factors preferentially bind GC boxes, while KLFs bind CACCC boxes. Another characteristic hallmark of SP factors is the presence of the Buttonhead (BTD) box CXCPXC, just N-terminal to the zinc fingers. The function of the BTD box is unknown, but it is thought to play an important physiological role. Another feature of most SP factors is the presence of a conserved amino acid stretch, the so-called SP box, located close to the N-terminus. SP factors may be separated into three groups based on their domain architecture and the similarity of their N-terminal transactivation domains: SP1-4, SP5, and SP6-9. The transactivation domains between the three groups are not homologous to one another. SP1-4 have similar N-terminal transactivation domains characterized by glutamine-rich regions, which, in most cases, have adjacent serine/threonine-rich regions. This model represents the N-terminal domain of SP4. Pssm-ID: 411773 [Multi-domain] Cd Length: 623 Bit Score: 44.14 E-value: 4.37e-04
|
||||||||||||||
| C2B_MCTP_PRT | cd08376 | C2 domain second repeat found in Multiple C2 domain and Transmembrane region Proteins (MCTP); ... |
61-128 | 7.19e-04 | ||||||||||
C2 domain second repeat found in Multiple C2 domain and Transmembrane region Proteins (MCTP); MCTPs are involved in Ca2+ signaling at the membrane. MCTP is composed of a variable N-terminal sequence, three C2 domains, two transmembrane regions (TMRs), and a short C-terminal sequence. It is one of four protein classes that are anchored to membranes via a transmembrane region; the others being synaptotagmins, extended synaptotagmins, and ferlins. MCTPs are the only membrane-bound C2 domain proteins that contain two functional TMRs. MCTPs are unique in that they bind Ca2+ but not phospholipids. C2 domains fold into an 8-standed beta-sandwich that can adopt 2 structural arrangements: Type I and Type II, distinguished by a circular permutation involving their N- and C-terminal beta strands. Many C2 domains are Ca2+-dependent membrane-targeting modules that bind a wide variety of substances including bind phospholipids, inositol polyphosphates, and intracellular proteins. Most C2 domain proteins are either signal transduction enzymes that contain a single C2 domain, such as protein kinase C, or membrane trafficking proteins which contain at least two C2 domains, such as synaptotagmin 1. However, there are a few exceptions to this including RIM isoforms and some splice variants of piccolo/aczonin and intersectin which only have a single C2 domain. C2 domains with a calcium binding region have negatively charged residues, primarily aspartates, that serve as ligands for calcium ions. This cd contains the second C2 repeat, C2B, and has a type-II topology. Pssm-ID: 176022 [Multi-domain] Cd Length: 116 Bit Score: 40.32 E-value: 7.19e-04
|
||||||||||||||
| C2A_RIM1alpha | cd04031 | C2 domain first repeat contained in Rab3-interacting molecule (RIM) proteins; RIMs are ... |
51-106 | 9.79e-04 | ||||||||||
C2 domain first repeat contained in Rab3-interacting molecule (RIM) proteins; RIMs are believed to organize specialized sites of the plasma membrane called active zones. They also play a role in controlling neurotransmitter release, plasticity processes, as well as memory and learning. RIM contains an N-terminal zinc finger domain, a PDZ domain, and two C-terminal C2 domains (C2A, C2B). C2 domains fold into an 8-standed beta-sandwich that can adopt 2 structural arrangements: Type I and Type II, distinguished by a circular permutation involving their N- and C-terminal beta strands. Many C2 domains are Ca2+-dependent membrane-targeting modules that bind a wide variety of substances including bind phospholipids, inositol polyphosphates, and intracellular proteins. Most C2 domain proteins are either signal transduction enzymes that contain a single C2 domain, such as protein kinase C, or membrane trafficking proteins which contain at least two C2 domains, such as synaptotagmin 1. However, there are a few exceptions to this including RIM isoforms and some splice variants of piccolo/aczonin and intersectin which only have a single C2 domain. C2 domains with a calcium binding region have negatively charged residues, primarily aspartates, that serve as ligands for calcium ions. Members here have a type-I topology and do not bind Ca2+. Pssm-ID: 175997 [Multi-domain] Cd Length: 125 Bit Score: 39.92 E-value: 9.79e-04
|
||||||||||||||
| PRP40 | COG5104 | Splicing factor [RNA processing and modification]; |
462-527 | 1.26e-03 | ||||||||||
Splicing factor [RNA processing and modification]; Pssm-ID: 227435 [Multi-domain] Cd Length: 590 Bit Score: 42.37 E-value: 1.26e-03
|
||||||||||||||
| C2_fungal_Inn1p-like | cd08681 | C2 domain found in fungal Ingression 1 (Inn1) proteins; Saccharomyces cerevisiae Inn1 ... |
20-105 | 2.94e-03 | ||||||||||
C2 domain found in fungal Ingression 1 (Inn1) proteins; Saccharomyces cerevisiae Inn1 associates with the contractile actomyosin ring at the end of mitosis and is needed for cytokinesis. The C2 domain of Inn1, located at the N-terminus, is required for ingression of the plasma membrane. The C-terminus is relatively unstructured and contains eight PXXP motifs that are thought to mediate interaction of Inn1 with other proteins with SH3 domains in the cytokinesis proteins Hof1 (an F-BAR protein) and Cyk3 (whose overexpression can restore primary septum formation in Inn1Delta cells) as well as recruiting Inn1 to the bud-neck by binding to Cyk3. Inn1 and Cyk3 appear to cooperate in activating chitin synthase Chs2 for primary septum formation, which allows coordination of actomyosin ring contraction with ingression of the cleavage furrow. It is thought that the C2 domain of Inn1 helps to preserve the link between the actomyosin ring and the plasma membrane, contributing both to membrane ingression, as well as to stability of the contracting ring. Additionally, Inn1 might induce curvature of the plasma membrane adjacent to the contracting ring, thereby promoting ingression of the membrane. It has been shown that the C2 domain of human synaptotagmin induces curvature in target membranes and thereby contributes to fusion of these membranes with synaptic vesicles. The C2 domain was first identified in PKC. C2 domains fold into an 8-standed beta-sandwich that can adopt 2 structural arrangements: Type I and Type II, distinguished by a circular permutation involving their N- and C-terminal beta strands. Many C2 domains are Ca2+-dependent membrane-targeting modules that bind a wide variety of substances including bind phospholipids, inositol polyphosphates, and intracellular proteins. Most C2 domain proteins are either signal transduction enzymes that contain a single C2 domain, such as protein kinase C, or membrane trafficking proteins which contain at least two C2 domains, such as synaptotagmin1. However, there are a few exceptions to this including RIM isoforms and some splice variants of piccolo/aczonin and intersectin which only have a single C2 domain. C2 domains with a calcium binding region have negatively charged residues, primarily aspartates, that serve as ligands for calcium ions. Pssm-ID: 176063 [Multi-domain] Cd Length: 118 Bit Score: 38.38 E-value: 2.94e-03
|
||||||||||||||
| C2_NEDD4_NEDD4L | cd04033 | C2 domain present in the Human neural precursor cell-expressed, developmentally down-regulated ... |
51-126 | 3.74e-03 | ||||||||||
C2 domain present in the Human neural precursor cell-expressed, developmentally down-regulated 4 (NEDD4) and NEDD4-like (NEDD4L/NEDD42); Nedd4 and Nedd4-2 are two of the nine members of the Human Nedd4 family. All vertebrates appear to have both Nedd4 and Nedd4-2 genes. They are thought to participate in the regulation of epithelial Na+ channel (ENaC) activity. They also have identical specificity for ubiquitin conjugating enzymes (E2). Nedd4 and Nedd4-2 are composed of a C2 domain, 2-4 WW domains, and a ubiquitin ligase Hect domain. Their WW domains can bind PPxY (PY) or LPSY motifs, and in vitro studies suggest that WW3 and WW4 of both proteins bind PY motifs in the key substrates, with WW3 generally exhibiting higher affinity. Most Nedd4 family members, especially Nedd4-2, also have multiple splice variants, which might play different roles in regulating their substrates. C2 domains fold into an 8-standed beta-sandwich that can adopt 2 structural arrangements: Type I and Type II, distinguished by a circular permutation involving their N- and C-terminal beta strands. Many C2 domains are Ca2+-dependent membrane-targeting modules that bind a wide variety of substances including bind phospholipids, inositol polyphosphates, and intracellular proteins. Most C2 domain proteins are either signal transduction enzymes that contain a single C2 domain, such as protein kinase C, or membrane trafficking proteins which contain at least two C2 domains, such as synaptotagmin 1. However, there are a few exceptions to this including RIM isoforms and some splice variants of piccolo/aczonin and intersectin which only have a single C2 domain. C2 domains with a calcium binding region have negatively charged residues, primarily aspartates, that serve as ligands for calcium ions. Pssm-ID: 175999 [Multi-domain] Cd Length: 133 Bit Score: 38.49 E-value: 3.74e-03
|
||||||||||||||
| C2_KIAA0528-like | cd08688 | C2 domain found in the Human KIAA0528 cDNA clone; The members of this CD are named after the ... |
41-106 | 6.77e-03 | ||||||||||
C2 domain found in the Human KIAA0528 cDNA clone; The members of this CD are named after the Human KIAA0528 cDNA clone. All members here contain a single C2 repeat. No other information on this protein is currently known. The C2 domain was first identified in PKC. C2 domains fold into an 8-standed beta-sandwich that can adopt 2 structural arrangements: Type I and Type II, distinguished by a circular permutation involving their N- and C-terminal beta strands. Many C2 domains are Ca2+-dependent membrane-targeting modules that bind a wide variety of substances including bind phospholipids, inositol polyphosphates, and intracellular proteins. Most C2 domain proteins are either signal transduction enzymes that contain a single C2 domain, such as protein kinase C, or membrane trafficking proteins which contain at least two C2 domains, such as synaptotagmin 1. However, there are a few exceptions to this including RIM isoforms and some splice variants of piccolo/aczonin and intersectin which only have a single C2 domain. C2 domains with a calcium binding region have negatively charged residues, primarily aspartates, that serve as ligands for calcium ions. Pssm-ID: 176070 [Multi-domain] Cd Length: 110 Bit Score: 37.29 E-value: 6.77e-03
|
||||||||||||||
| C2A_C2C_Synaptotagmin_like | cd08391 | C2 domain first and third repeat in Synaptotagmin-like proteins; Synaptotagmin is a ... |
20-102 | 8.30e-03 | ||||||||||
C2 domain first and third repeat in Synaptotagmin-like proteins; Synaptotagmin is a membrane-trafficking protein characterized by a N-terminal transmembrane region, a linker, and 2 C-terminal C2 domains. Previously all synaptotagmins were thought to be calcium sensors in the regulation of neurotransmitter release and hormone secretion, but it has been shown that not all of them bind calcium. Of the 17 identified synaptotagmins only 8 bind calcium (1-3, 5-7, 9, 10). The function of the two C2 domains that bind calcium are: regulating the fusion step of synaptic vesicle exocytosis (C2A) and binding to phosphatidyl-inositol-3,4,5-triphosphate (PIP3) in the absence of calcium ions and to phosphatidylinositol bisphosphate (PIP2) in their presence (C2B). C2B also regulates also the recycling step of synaptic vesicles. C2 domains fold into an 8-standed beta-sandwich that can adopt 2 structural arrangements: Type I and Type II, distinguished by a circular permutation involving their N- and C-terminal beta strands. Many C2 domains are Ca2+-dependent membrane-targeting modules that bind a wide variety of substances including bind phospholipids, inositol polyphosphates, and intracellular proteins. Most C2 domain proteins are either signal transduction enzymes that contain a single C2 domain, such as protein kinase C, or membrane trafficking proteins which contain at least two C2 domains, such as synaptotagmin 1. However, there are a few exceptions to this including RIM isoforms and some splice variants of piccolo/aczonin and intersectin which only have a single C2 domain. C2 domains with a calcium binding region have negatively charged residues, primarily aspartates, that serve as ligands for calcium ions. This cd contains either the first or third repeat in Synaptotagmin-like proteins with a type-I topology. Pssm-ID: 176037 [Multi-domain] Cd Length: 121 Bit Score: 37.27 E-value: 8.30e-03
|
||||||||||||||
| Blast search parameters | ||||
|
