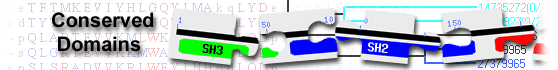


syntaxin-binding protein 5-like isoform 1 [Homo sapiens]
Protein Classification

LLGL and R-SNARE_STXBP5 domain-containing protein( domain architecture ID 11456851)
protein containing domains WD40, LLGL, and R-SNARE_STXBP5
List of domain hits
| Name | Accession | Description | Interval | E-value | |||||
| LLGL | pfam08366 | LLGL2; This domain is found in lethal giant larvae homolog 2 (LLGL2) proteins and ... |
288-397 | 3.80e-45 | |||||
LLGL2; This domain is found in lethal giant larvae homolog 2 (LLGL2) proteins and syntaxin-binding proteins like tomosyn. It has been identified in eukaryotes and tends to be found together with WD repeats (pfam00400). : Pssm-ID: 462446 Cd Length: 103 Bit Score: 157.74 E-value: 3.80e-45
|
|||||||||
| R-SNARE_STXBP5 | cd15893 | SNARE domain of STXBP5; Syntaxin binding protein 5 (STXBP5, also called Tomosyn), as well as ... |
1119-1179 | 9.87e-32 | |||||
SNARE domain of STXBP5; Syntaxin binding protein 5 (STXBP5, also called Tomosyn), as well as its relative Syntaxin binding protein 6 (STXBP6, also called Amisyn) contains a C-terminal R-SNARE-like domain, which allows it to assemble into SNARE complexes, which in turn makes the complexes inactive and inhibits exocytosis. Tomosyn contains an N-terminal WD40 repeat region and has been shown to form complexes with SNAP-25 and syntaxin 1a, as well as SNAP-23 and syntaxin 4. In general, SNARE (soluble N-ethylmaleimide-sensitive factor attachment protein receptor) proteins consist of coiled-coil helices (called SNARE motifs) which mediate the interactions between SNARE proteins, and a transmembrane domain. The SNARE complex mediates membrane fusion, important for trafficking of newly synthesized proteins, recycling of pre-existing proteins and organelle formation. SNARE proteins are classified into four groups, Qa-, Qb-, Qc- and R-SNAREs, depending on whether the residue in the hydrophilic center layer of the four-helical bundle is a glutamine (Q) or arginine (R). Qc-, as well as Qa- and Qb-SNAREs, are localized to target organelle membranes, while R-SNARE is localized to vesicle membranes. They form unique complexes consisting of one member of each subgroup, that mediate fusion between a specific type of vesicles and their target organelle. : Pssm-ID: 277246 Cd Length: 61 Bit Score: 118.22 E-value: 9.87e-32
|
|||||||||
| WD40 | COG2319 | WD40 repeat [General function prediction only]; |
37-295 | 5.47e-14 | |||||
WD40 repeat [General function prediction only]; : Pssm-ID: 441893 [Multi-domain] Cd Length: 403 Bit Score: 75.33 E-value: 5.47e-14
|
|||||||||
| Name | Accession | Description | Interval | E-value | |||||
| LLGL | pfam08366 | LLGL2; This domain is found in lethal giant larvae homolog 2 (LLGL2) proteins and ... |
288-397 | 3.80e-45 | |||||
LLGL2; This domain is found in lethal giant larvae homolog 2 (LLGL2) proteins and syntaxin-binding proteins like tomosyn. It has been identified in eukaryotes and tends to be found together with WD repeats (pfam00400). Pssm-ID: 462446 Cd Length: 103 Bit Score: 157.74 E-value: 3.80e-45
|
|||||||||
| R-SNARE_STXBP5 | cd15893 | SNARE domain of STXBP5; Syntaxin binding protein 5 (STXBP5, also called Tomosyn), as well as ... |
1119-1179 | 9.87e-32 | |||||
SNARE domain of STXBP5; Syntaxin binding protein 5 (STXBP5, also called Tomosyn), as well as its relative Syntaxin binding protein 6 (STXBP6, also called Amisyn) contains a C-terminal R-SNARE-like domain, which allows it to assemble into SNARE complexes, which in turn makes the complexes inactive and inhibits exocytosis. Tomosyn contains an N-terminal WD40 repeat region and has been shown to form complexes with SNAP-25 and syntaxin 1a, as well as SNAP-23 and syntaxin 4. In general, SNARE (soluble N-ethylmaleimide-sensitive factor attachment protein receptor) proteins consist of coiled-coil helices (called SNARE motifs) which mediate the interactions between SNARE proteins, and a transmembrane domain. The SNARE complex mediates membrane fusion, important for trafficking of newly synthesized proteins, recycling of pre-existing proteins and organelle formation. SNARE proteins are classified into four groups, Qa-, Qb-, Qc- and R-SNAREs, depending on whether the residue in the hydrophilic center layer of the four-helical bundle is a glutamine (Q) or arginine (R). Qc-, as well as Qa- and Qb-SNAREs, are localized to target organelle membranes, while R-SNARE is localized to vesicle membranes. They form unique complexes consisting of one member of each subgroup, that mediate fusion between a specific type of vesicles and their target organelle. Pssm-ID: 277246 Cd Length: 61 Bit Score: 118.22 E-value: 9.87e-32
|
|||||||||
| WD40 | COG2319 | WD40 repeat [General function prediction only]; |
37-295 | 5.47e-14 | |||||
WD40 repeat [General function prediction only]; Pssm-ID: 441893 [Multi-domain] Cd Length: 403 Bit Score: 75.33 E-value: 5.47e-14
|
|||||||||
| WD40 | cd00200 | WD40 domain, found in a number of eukaryotic proteins that cover a wide variety of functions ... |
74-281 | 1.58e-13 | |||||
WD40 domain, found in a number of eukaryotic proteins that cover a wide variety of functions including adaptor/regulatory modules in signal transduction, pre-mRNA processing and cytoskeleton assembly; typically contains a GH dipeptide 11-24 residues from its N-terminus and the WD dipeptide at its C-terminus and is 40 residues long, hence the name WD40; between GH and WD lies a conserved core; serves as a stable propeller-like platform to which proteins can bind either stably or reversibly; forms a propeller-like structure with several blades where each blade is composed of a four-stranded anti-parallel b-sheet; instances with few detectable copies are hypothesized to form larger structures by dimerization; each WD40 sequence repeat forms the first three strands of one blade and the last strand in the next blade; the last C-terminal WD40 repeat completes the blade structure of the first WD40 repeat to create the closed ring propeller-structure; residues on the top and bottom surface of the propeller are proposed to coordinate interactions with other proteins and/or small ligands; 7 copies of the repeat are present in this alignment. Pssm-ID: 238121 [Multi-domain] Cd Length: 289 Bit Score: 72.37 E-value: 1.58e-13
|
|||||||||
| Synaptobrevin | pfam00957 | Synaptobrevin; |
1145-1184 | 5.95e-04 | |||||
Synaptobrevin; Pssm-ID: 395764 Cd Length: 89 Bit Score: 39.83 E-value: 5.95e-04
|
|||||||||
| Name | Accession | Description | Interval | E-value | |||||
| LLGL | pfam08366 | LLGL2; This domain is found in lethal giant larvae homolog 2 (LLGL2) proteins and ... |
288-397 | 3.80e-45 | |||||
LLGL2; This domain is found in lethal giant larvae homolog 2 (LLGL2) proteins and syntaxin-binding proteins like tomosyn. It has been identified in eukaryotes and tends to be found together with WD repeats (pfam00400). Pssm-ID: 462446 Cd Length: 103 Bit Score: 157.74 E-value: 3.80e-45
|
|||||||||
| R-SNARE_STXBP5 | cd15893 | SNARE domain of STXBP5; Syntaxin binding protein 5 (STXBP5, also called Tomosyn), as well as ... |
1119-1179 | 9.87e-32 | |||||
SNARE domain of STXBP5; Syntaxin binding protein 5 (STXBP5, also called Tomosyn), as well as its relative Syntaxin binding protein 6 (STXBP6, also called Amisyn) contains a C-terminal R-SNARE-like domain, which allows it to assemble into SNARE complexes, which in turn makes the complexes inactive and inhibits exocytosis. Tomosyn contains an N-terminal WD40 repeat region and has been shown to form complexes with SNAP-25 and syntaxin 1a, as well as SNAP-23 and syntaxin 4. In general, SNARE (soluble N-ethylmaleimide-sensitive factor attachment protein receptor) proteins consist of coiled-coil helices (called SNARE motifs) which mediate the interactions between SNARE proteins, and a transmembrane domain. The SNARE complex mediates membrane fusion, important for trafficking of newly synthesized proteins, recycling of pre-existing proteins and organelle formation. SNARE proteins are classified into four groups, Qa-, Qb-, Qc- and R-SNAREs, depending on whether the residue in the hydrophilic center layer of the four-helical bundle is a glutamine (Q) or arginine (R). Qc-, as well as Qa- and Qb-SNAREs, are localized to target organelle membranes, while R-SNARE is localized to vesicle membranes. They form unique complexes consisting of one member of each subgroup, that mediate fusion between a specific type of vesicles and their target organelle. Pssm-ID: 277246 Cd Length: 61 Bit Score: 118.22 E-value: 9.87e-32
|
|||||||||
| R-SNARE_STXBP5_6 | cd15873 | SNARE domain of STXBP5, STXBP6 and related proteins; Syntaxin binding protein 5 (STXBP5, also ... |
1119-1179 | 2.22e-21 | |||||
SNARE domain of STXBP5, STXBP6 and related proteins; Syntaxin binding protein 5 (STXBP5, also called Tomosyn), as well as its relative Syntaxin binding protein 6 (STXBP6, also called Amisyn) contains a C-terminal R-SNARE-like domain, which allows it to assemble into SNARE complexes, which in turn makes the complexes inactive and inhibits exocytosis. In general, SNARE (soluble N-ethylmaleimide-sensitive factor attachment protein receptor) proteins consist of coiled-coil helices (called SNARE motifs) which mediate the interactions between SNARE proteins, and a transmembrane domain. The SNARE complex mediates membrane fusion, important for trafficking of newly synthesized proteins, recycling of pre-existing proteins and organelle formation. SNARE proteins are classified into four groups, Qa-, Qb-, Qc- and R-SNAREs, depending on whether the residue in the hydrophilic center layer of the four-helical bundle is a glutamine (Q) or arginine (R). Qc-, as well as Qa- and Qb-SNAREs, are localized to target organelle membranes, while R-SNARE is localized to vesicle membranes. They form unique complexes consisting of one member of each subgroup, that mediate fusion between a specific type of vesicles and their target organelle. Pssm-ID: 277226 Cd Length: 61 Bit Score: 88.47 E-value: 2.22e-21
|
|||||||||
| WD40 | COG2319 | WD40 repeat [General function prediction only]; |
37-295 | 5.47e-14 | |||||
WD40 repeat [General function prediction only]; Pssm-ID: 441893 [Multi-domain] Cd Length: 403 Bit Score: 75.33 E-value: 5.47e-14
|
|||||||||
| WD40 | cd00200 | WD40 domain, found in a number of eukaryotic proteins that cover a wide variety of functions ... |
74-281 | 1.58e-13 | |||||
WD40 domain, found in a number of eukaryotic proteins that cover a wide variety of functions including adaptor/regulatory modules in signal transduction, pre-mRNA processing and cytoskeleton assembly; typically contains a GH dipeptide 11-24 residues from its N-terminus and the WD dipeptide at its C-terminus and is 40 residues long, hence the name WD40; between GH and WD lies a conserved core; serves as a stable propeller-like platform to which proteins can bind either stably or reversibly; forms a propeller-like structure with several blades where each blade is composed of a four-stranded anti-parallel b-sheet; instances with few detectable copies are hypothesized to form larger structures by dimerization; each WD40 sequence repeat forms the first three strands of one blade and the last strand in the next blade; the last C-terminal WD40 repeat completes the blade structure of the first WD40 repeat to create the closed ring propeller-structure; residues on the top and bottom surface of the propeller are proposed to coordinate interactions with other proteins and/or small ligands; 7 copies of the repeat are present in this alignment. Pssm-ID: 238121 [Multi-domain] Cd Length: 289 Bit Score: 72.37 E-value: 1.58e-13
|
|||||||||
| WD40 | COG2319 | WD40 repeat [General function prediction only]; |
74-281 | 4.85e-13 | |||||
WD40 repeat [General function prediction only]; Pssm-ID: 441893 [Multi-domain] Cd Length: 403 Bit Score: 72.64 E-value: 4.85e-13
|
|||||||||
| WD40 | cd00200 | WD40 domain, found in a number of eukaryotic proteins that cover a wide variety of functions ... |
67-278 | 5.59e-12 | |||||
WD40 domain, found in a number of eukaryotic proteins that cover a wide variety of functions including adaptor/regulatory modules in signal transduction, pre-mRNA processing and cytoskeleton assembly; typically contains a GH dipeptide 11-24 residues from its N-terminus and the WD dipeptide at its C-terminus and is 40 residues long, hence the name WD40; between GH and WD lies a conserved core; serves as a stable propeller-like platform to which proteins can bind either stably or reversibly; forms a propeller-like structure with several blades where each blade is composed of a four-stranded anti-parallel b-sheet; instances with few detectable copies are hypothesized to form larger structures by dimerization; each WD40 sequence repeat forms the first three strands of one blade and the last strand in the next blade; the last C-terminal WD40 repeat completes the blade structure of the first WD40 repeat to create the closed ring propeller-structure; residues on the top and bottom surface of the propeller are proposed to coordinate interactions with other proteins and/or small ligands; 7 copies of the repeat are present in this alignment. Pssm-ID: 238121 [Multi-domain] Cd Length: 289 Bit Score: 67.75 E-value: 5.59e-12
|
|||||||||
| R-SNARE_STXBP6 | cd15892 | SNARE domain of STXBP6; Syntaxin binding protein 6 (STXBP6, also called Amisyn), as well as ... |
1118-1179 | 3.74e-11 | |||||
SNARE domain of STXBP6; Syntaxin binding protein 6 (STXBP6, also called Amisyn), as well as its relative Syntaxin binding protein 5 (STXBP5, also called Tomosyn), contains a C-terminal R-SNARE-like domain, which allows it to assemble into SNARE complexes, which in turn makes the complexes inactive and inhibits exocytosis. In general, SNARE (soluble N-ethylmaleimide-sensitive factor attachment protein receptor) proteins consist of coiled-coil helices (called SNARE motifs) which mediate the interactions between SNARE proteins, and a transmembrane domain. The SNARE complex mediates membrane fusion, important for trafficking of newly synthesized proteins, recycling of pre-existing proteins and organelle formation. SNARE proteins are classified into four groups, Qa-, Qb-, Qc- and R-SNAREs, depending on whether the residue in the hydrophilic center layer of the four-helical bundle is a glutamine (Q) or arginine (R). Qc-, as well as Qa- and Qb-SNAREs, are localized to target organelle membranes, while R-SNARE is localized to vesicle membranes. They form unique complexes consisting of one member of each subgroup, that mediate fusion between a specific type of vesicles and their target organelle. Pssm-ID: 277245 Cd Length: 62 Bit Score: 59.78 E-value: 3.74e-11
|
|||||||||
| R-SNARE | cd15843 | SNARE motif, subgroup R-SNARE; SNARE (soluble N-ethylmaleimide-sensitive factor attachment ... |
1145-1179 | 3.69e-05 | |||||
SNARE motif, subgroup R-SNARE; SNARE (soluble N-ethylmaleimide-sensitive factor attachment protein receptor) proteins consist of coiled-coil helices (called SNARE motifs) which mediate the interactions between SNARE proteins, and a transmembrane domain. The SNARE complex mediates membrane fusion, important for trafficking of newly synthesized proteins, recycling of pre-existing proteins and organelle formation. SNARE proteins are classified into four groups, Qa-, Qb-, Qc- and R-SNAREs, depending on whether the residue in the hydrophilic center layer of the four-helical bundle is a glutamine (Q) or arginine (R). In contrast to Qa-, Qb- and Qc-SNAREs that are localized to target organelle membranes, R-SNAREs are localized to vesicle membranes. They form unique complexes consisting of one member of each subgroup, that mediate fusion between a specific type of vesicles and their target organelle. Their SNARE motifs form twisted and parallel heterotetrameric helix bundles. Examples for members of the Qa SNAREs are syntaxin 18, syntaxin 5, syntaxin 16, and syntaxin 1. Pssm-ID: 277196 [Multi-domain] Cd Length: 60 Bit Score: 42.49 E-value: 3.69e-05
|
|||||||||
| Synaptobrevin | pfam00957 | Synaptobrevin; |
1145-1184 | 5.95e-04 | |||||
Synaptobrevin; Pssm-ID: 395764 Cd Length: 89 Bit Score: 39.83 E-value: 5.95e-04
|
|||||||||
| WD40 | COG2319 | WD40 repeat [General function prediction only]; |
68-141 | 1.11e-03 | |||||
WD40 repeat [General function prediction only]; Pssm-ID: 441893 [Multi-domain] Cd Length: 403 Bit Score: 42.98 E-value: 1.11e-03
|
|||||||||
| Blast search parameters | ||||
|
