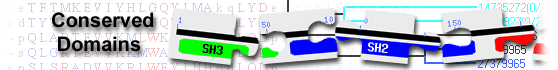|
Name |
Accession |
Description |
Interval |
E-value |
| Smc |
COG1196 |
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
573-1074 |
6.22e-22 |
|
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 102.71 E-value: 6.22e-22
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 573 LKLEVEEKKQAMLLLQRALAQQRDLTARRVKETEKALSRQLQRQREHYEATIQR---HLAFIDQLIEDKKVLSEKCEAVV 649
Cdd:COG1196 218 LKEELKELEAELLLLKLRELEAELEELEAELEELEAELEELEAELAELEAELEElrlELEELELELEEAQAEEYELLAEL 297
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 650 AELKQEDQRCTERVAQAQAQHELEIKKLKELMSATEKARREkwISEKTKKIKEvtvrgLEPEIQKLIARHKQEVRRLKSL 729
Cdd:COG1196 298 ARLEQDIARLEERRRELEERLEELEEELAELEEELEELEEE--LEELEEELEE-----AEEELEEAEAELAEAEEALLEA 370
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 730 hEAELLQSDERASQRCLRQAEELREQLEREKEALGQQERERARQRFQQHLEQEQWALQQQRQRLYSEVAEERERLGQQAA 809
Cdd:COG1196 371 -EAELAEAEEELEELAEELLEALRAAAELAAQLEELEEAEEALLERLERLEEELEELEEALAELEEEEEEEEEALEEAAE 449
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 810 RQRAELEELRQQLEESSSALTRALRAEFEKGREEQERRHQMELNTLKQQLELERQAWEAGRTRKEEAWLLNREQELREEI 889
Cdd:COG1196 450 EEAELEEEEEALLELLAELLEEAALLEAALAELLEELAEAAARLLLLLEAEADYEGFLEGVKAALLLAGLRGLAGAVAVL 529
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 890 RKGRDKEIELVIHRLEADMALAKEESEKAAESRIKRLRDKYEAELSELEQSERKLQERCSELKGQLGEAEGENLRLQGLV 969
Cdd:COG1196 530 IGVEAAYEAALEAALAAALQNIVVEDDEVAAAAIEYLKAAKAGRATFLPLDKIRARAALAAALARGAIGAAVDLVASDLR 609
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 970 RQKERA-LEDAQAVNEQLSSERSNLAQVIRQEFEDRLAAS--EEETRQAKAELATLQARQQLELEEVHRRVKTALARKEE 1046
Cdd:COG1196 610 EADARYyVLGDTLLGRTLVAARLEAALRRAVTLAGRLREVtlEGEGGSAGGSLTGGSRRELLAALLEAEAELEELAERLA 689
|
490 500
....*....|....*....|....*...
gi 111955084 1047 AVSSLRTQHEAAVKRADHLEELLEQHRR 1074
Cdd:COG1196 690 EEELELEEALLAEEEEERELAEAEEERL 717
|
|
| Smc |
COG1196 |
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
572-1074 |
5.93e-21 |
|
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 99.24 E-value: 5.93e-21
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 572 RLKLEVEEKKQAMLLLQRALAQQRDLTARRvkETEKALSRQLQRQREHYEATIQRHLAFIDQLIEDKKVLSEKCEAVVAE 651
Cdd:COG1196 240 ELEELEAELEELEAELEELEAELAELEAEL--EELRLELEELELELEEAQAEEYELLAELARLEQDIARLEERRRELEER 317
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 652 LKQEDQRCTERVAQAQAQHELEIKKLKELMSATEKARREKWISEKTKKIKEVTVRGLEPEIQKLIARHKQEVRRLKSLHE 731
Cdd:COG1196 318 LEELEEELAELEEELEELEEELEELEEELEEAEEELEEAEAELAEAEEALLEAEAELAEAEEELEELAEELLEALRAAAE 397
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 732 AE-LLQSDERASQRCLRQAEELREQLEREKEALGQQERERARQRfQQHLEQEQWALQQQRQRLysEVAEERERLGQQAAR 810
Cdd:COG1196 398 LAaQLEELEEAEEALLERLERLEEELEELEEALAELEEEEEEEE-EALEEAAEEEAELEEEEE--ALLELLAELLEEAAL 474
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 811 QRAELEELRQQLEESSS--ALTRALRAEFEKGREEQERRHQMELNTLKQQLELERQAWEAGRTRKEEAWLLNREQELREE 888
Cdd:COG1196 475 LEAALAELLEELAEAAArlLLLLEAEADYEGFLEGVKAALLLAGLRGLAGAVAVLIGVEAAYEAALEAALAAALQNIVVE 554
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 889 IRKGRDKEIE-LVIHRLEADMALAKEESEKAAESRIKRLRDKYEAELSELEQSERKLQERCSELKGQLGEAEGENLRLQG 967
Cdd:COG1196 555 DDEVAAAAIEyLKAAKAGRATFLPLDKIRARAALAAALARGAIGAAVDLVASDLREADARYYVLGDTLLGRTLVAARLEA 634
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 968 LVRQKERALEDAQAVneQLSSERSNLAQVIRQEFEDRLAASEEETRQAKAELATLQARQQLELEEVHRRVKTALARKEEA 1047
Cdd:COG1196 635 ALRRAVTLAGRLREV--TLEGEGGSAGGSLTGGSRRELLAALLEAEAELEELAERLAEEELELEEALLAEEEEERELAEA 712
|
490 500
....*....|....*....|....*..
gi 111955084 1048 VSSLRTQHEAAVKRADHLEELLEQHRR 1074
Cdd:COG1196 713 EEERLEEELEEEALEEQLEAEREELLE 739
|
|
| Smc |
COG1196 |
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
762-1072 |
3.36e-18 |
|
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 90.38 E-value: 3.36e-18
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 762 ALGQQERERARQRFQQHLEQEQWALQQQRQRLySEVAEERERLGQQAARQRAELEELRQQLEESSSALTRALraefekgr 841
Cdd:COG1196 217 ELKEELKELEAELLLLKLRELEAELEELEAEL-EELEAELEELEAELAELEAELEELRLELEELELELEEAQ-------- 287
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 842 eEQERRHQMELNTLKQQLELERQAWEAGRTRKEEawLLNREQELREEIrkgrdKEIELVIHRLEADMALAKEESEKAAES 921
Cdd:COG1196 288 -AEEYELLAELARLEQDIARLEERRRELEERLEE--LEEELAELEEEL-----EELEEELEELEEELEEAEEELEEAEAE 359
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 922 RIKRlrdkyEAELSELEQSERKLQERCSELKGQLGEAEGENLRLQGLVRQKERALEDAQAVNEQLSSERSNLAQVIRQEF 1001
Cdd:COG1196 360 LAEA-----EEALLEAEAELAEAEEELEELAEELLEALRAAAELAAQLEELEEAEEALLERLERLEEELEELEEALAELE 434
|
250 260 270 280 290 300 310
....*....|....*....|....*....|....*....|....*....|....*....|....*....|.
gi 111955084 1002 EDRLAASEEETRQAKAELATLQARQQLELEEVHRRVKTALArkEEAVSSLRTQHEAAVKRADHLEELLEQH 1072
Cdd:COG1196 435 EEEEEEEEALEEAAEEEAELEEEEEALLELLAELLEEAALL--EAALAELLEELAEAAARLLLLLEAEADY 503
|
|
| Smc |
COG1196 |
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
711-1059 |
9.42e-18 |
|
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 88.84 E-value: 9.42e-18
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 711 EIQKLIARHKQEVRRLKSLHEAELLQSDERASQRCLRQAEELREQLEREKEAL--GQQERERARQRFQQHLEQEQWALQQ 788
Cdd:COG1196 206 ERQAEKAERYRELKEELKELEAELLLLKLRELEAELEELEAELEELEAELEELeaELAELEAELEELRLELEELELELEE 285
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 789 QRQRLYsEVAEERERLGQQAARQRAELEELRQQLEEsssaLTRALRAEFEKGREEQERRHqmELNTLKQQLELERQAWEA 868
Cdd:COG1196 286 AQAEEY-ELLAELARLEQDIARLEERRRELEERLEE----LEEELAELEEELEELEEELE--ELEEELEEAEEELEEAEA 358
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 869 GRTRKEEAwLLNREQELREEIRKGRDKEIELVIHRLEADMALAKEESEKAAESRIKRLRDKYEAELSELEQSERKLQERC 948
Cdd:COG1196 359 ELAEAEEA-LLEAEAELAEAEEELEELAEELLEALRAAAELAAQLEELEEAEEALLERLERLEEELEELEEALAELEEEE 437
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 949 SELKGQLGEAEGENLRLQGLVRQKERALEDAQAVNEQLSSERSNLAQVIRQEFEDRLAASEEETRQAKAELATLQARQQL 1028
Cdd:COG1196 438 EEEEEALEEAAEEEAELEEEEEALLELLAELLEEAALLEAALAELLEELAEAAARLLLLLEAEADYEGFLEGVKAALLLA 517
|
330 340 350
....*....|....*....|....*....|.
gi 111955084 1029 ELEEVHRRVKTALARKEEAVSSLRTQHEAAV 1059
Cdd:COG1196 518 GLRGLAGAVAVLIGVEAAYEAALEAALAAAL 548
|
|
| PTZ00121 |
PTZ00121 |
MAEBL; Provisional |
280-1070 |
3.82e-15 |
|
MAEBL; Provisional
Pssm-ID: 173412 [Multi-domain] Cd Length: 2084 Bit Score: 80.96 E-value: 3.82e-15
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 280 RHQVQRRGAGAARLEhllQAKREEQRQRSGEGTLLDLHQQKEAARRKAREEKARQARRAAiqelQQKRALRAQKASTAER 359
Cdd:PTZ00121 1165 KAEEARKAEDAKKAE---AARKAEEVRKAEELRKAEDARKAEAARKAEEERKAEEARKAE----DAKKAEAVKKAEEAKK 1237
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 360 GPPENPRETRVpgmRQPAQELSPTPGGTAHQALKANNTGGGLPAAGPGDRCLPTSDSSPEPQQPPEDRTQDVLaqdaagd 439
Cdd:PTZ00121 1238 DAEEAKKAEEE---RNNEEIRKFEEARMAHFARRQAAIKAEEARKADELKKAEEKKKADEAKKAEEKKKADEA------- 1307
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 440 nlemmapsRGSAKSRGPLEELLHTLQLLEKEPDVLPRPRTHHRGRYAWASEEDDASSLTADNLEKFGKlsafpeppEDGT 519
Cdd:PTZ00121 1308 --------KKKAEEAKKADEAKKKAEEAKKKADAAKKKAEEAKKAAEAAKAEAEAAADEAEAAEEKAE--------AAEK 1371
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 520 LLSEAKLQSIMSFLDEMEKSGQDQLDSQQEGWVPEAGPgpLELGSEVSTSVMRLKLEVEEKKQAMLLLQRALAQQRDLTA 599
Cdd:PTZ00121 1372 KKEEAKKKADAAKKKAEEKKKADEAKKKAEEDKKKADE--LKKAAAAKKKADEAKKKAEEKKKADEAKKKAEEAKKADEA 1449
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 600 RRVKETEKALSRQLQRQREHYEATiqrhlafidqliEDKKVLSEKCEAvvAELKQEDQRCTERVAQAQAQHElEIKKLKE 679
Cdd:PTZ00121 1450 KKKAEEAKKAEEAKKKAEEAKKAD------------EAKKKAEEAKKA--DEAKKKAEEAKKKADEAKKAAE-AKKKADE 1514
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 680 LMSATEKARREKW-ISEKTKKIKEVtvRGLEPEIQKLIARHKQEVRRLKSLHEAELLQSDERASQRCLRQAEELREQLER 758
Cdd:PTZ00121 1515 AKKAEEAKKADEAkKAEEAKKADEA--KKAEEKKKADELKKAEELKKAEEKKKAEEAKKAEEDKNMALRKAEEAKKAEEA 1592
|
490 500 510 520 530 540 550 560
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 759 EKEALGQQERERARQRFQQHLEQEQWALQQQRQRLYSEVAEERERLGQQAARQRAELEELRQQLEESSsaltraLRAEFE 838
Cdd:PTZ00121 1593 RIEEVMKLYEEEKKMKAEEAKKAEEAKIKAEELKKAEEEKKKVEQLKKKEAEEKKKAEELKKAEEENK------IKAAEE 1666
|
570 580 590 600 610 620 630 640
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 839 KGREEQERRHQMElntLKQQLELERQAWEAGRTRKEEAwllNREQELR----EEIRKGRDKEIELVIHRLEADMALAKEE 914
Cdd:PTZ00121 1667 AKKAEEDKKKAEE---AKKAEEDEKKAAEALKKEAEEA---KKAEELKkkeaEEKKKAEELKKAEEENKIKAEEAKKEAE 1740
|
650 660 670 680 690 700 710 720
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 915 SEKaaesrikrlRDKYEAELSELEQSERKLQERCSELKGQLGEAEGENLRLQGLvrqKERALEDAQAVNEQLSSERSNLA 994
Cdd:PTZ00121 1741 EDK---------KKAEEAKKDEEEKKKIAHLKKEEEKKAEEIRKEKEAVIEEEL---DEEDEKRRMEVDKKIKDIFDNFA 1808
|
730 740 750 760 770 780 790
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*...
gi 111955084 995 QVIRQEFEDRLA--ASEEETRQAKAELATLQARQQLELEEVHRRVKTALARKEEAVSSLRTQHEAAVKRADHLEELLE 1070
Cdd:PTZ00121 1809 NIIEGGKEGNLVinDSKEMEDSAIKEVADSKNMQLEEADAFEKHKFNKNNENGEDGNKEADFNKEKDLKEDDEEEIEE 1886
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
788-1069 |
5.47e-15 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 80.10 E-value: 5.47e-15
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 788 QQRQRLYSEVAEERERLGQQAARQRAELEELRQQLEESSSALTRALRAEFEKGREEQERRHQMELNTLKQQLELERQAwe 867
Cdd:TIGR02168 673 LERRREIEELEEKIEELEEKIAELEKALAELRKELEELEEELEQLRKELEELSRQISALRKDLARLEAEVEQLEERIA-- 750
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 868 agRTRKEEAWLLNREQELREEIRKGRD--KEIELVIHRLEADMALAKEESeKAAESRIKRLRdkyeAELSELEQSERKLQ 945
Cdd:TIGR02168 751 --QLSKELTELEAEIEELEERLEEAEEelAEAEAEIEELEAQIEQLKEEL-KALREALDELR----AELTLLNEEAANLR 823
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 946 ERCSELKGQLGEAEgenLRLQGLVRQKERALEDAQAVNEQLSSERSNLAQVIRQ--EFEDRLAASEEETRQAKAELATLQ 1023
Cdd:TIGR02168 824 ERLESLERRIAATE---RRLEDLEEQIEELSEDIESLAAEIEELEELIEELESEleALLNERASLEEALALLRSELEELS 900
|
250 260 270 280
....*....|....*....|....*....|....*....|....*.
gi 111955084 1024 ARQQlELEEVHRRVKTALARKEEAVSSLRTQHEAAVKRADHLEELL 1069
Cdd:TIGR02168 901 EELR-ELESKRSELRRELEELREKLAQLELRLEGLEVRIDNLQERL 945
|
|
| PTZ00121 |
PTZ00121 |
MAEBL; Provisional |
574-1074 |
5.74e-15 |
|
MAEBL; Provisional
Pssm-ID: 173412 [Multi-domain] Cd Length: 2084 Bit Score: 80.19 E-value: 5.74e-15
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 574 KLEVEEKKQAMLLLQRALAQQRDLTARRVKETEKALSRQLQRQREHYEATIQRHLAFIDQLIEDKKVLSEKCEAVVAELK 653
Cdd:PTZ00121 1244 KAEEERNNEEIRKFEEARMAHFARRQAAIKAEEARKADELKKAEEKKKADEAKKAEEKKKADEAKKKAEEAKKADEAKKK 1323
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 654 QEDQRCTERVAQAQAQhelEIKKLKELMSATEKARREKwiSEKTKKIKEVTVRGLEPEIQKLIARHKQEVRRLKSLHEAE 733
Cdd:PTZ00121 1324 AEEAKKKADAAKKKAE---EAKKAAEAAKAEAEAAADE--AEAAEEKAEAAEKKKEEAKKKADAAKKKAEEKKKADEAKK 1398
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 734 LLQSDERASQRCLRQAEELREQLEREKEALGQQERERARQRFQQHLEQEQWALQQQRQRLYSEV---AEERERLGQ--QA 808
Cdd:PTZ00121 1399 KAEEDKKKADELKKAAAAKKKADEAKKKAEEKKKADEAKKKAEEAKKADEAKKKAEEAKKAEEAkkkAEEAKKADEakKK 1478
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 809 ARQRAELEELRQQLEESSSALTRALRAEFEKGREEQERRhqMELNTLKQQLELERQAWEAGRTRKEEAWLLNREQELREE 888
Cdd:PTZ00121 1479 AEEAKKADEAKKKAEEAKKKADEAKKAAEAKKKADEAKK--AEEAKKADEAKKAEEAKKADEAKKAEEKKKADELKKAEE 1556
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 889 IRKGRDKEIELVIHRLEAD--MALAK-EESEKAAESRIKRLRDKYEAELSELEQSERKLQERCSELKgQLGEAEGENLRL 965
Cdd:PTZ00121 1557 LKKAEEKKKAEEAKKAEEDknMALRKaEEAKKAEEARIEEVMKLYEEEKKMKAEEAKKAEEAKIKAE-ELKKAEEEKKKV 1635
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 966 QGLVRQKERALEDAQAVNEQLSSERSNLAQVIRQEFEDRLAASE----EETRQAKAELATLQARQQLELEEVHRRVKTAL 1041
Cdd:PTZ00121 1636 EQLKKKEAEEKKKAEELKKAEEENKIKAAEEAKKAEEDKKKAEEakkaEEDEKKAAEALKKEAEEAKKAEELKKKEAEEK 1715
|
490 500 510
....*....|....*....|....*....|...
gi 111955084 1042 ARKEEavssLRTQHEAAVKRADHLEELLEQHRR 1074
Cdd:PTZ00121 1716 KKAEE----LKKAEEENKIKAEEAKKEAEEDKK 1744
|
|
| Smc |
COG1196 |
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
666-1074 |
6.26e-15 |
|
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 79.98 E-value: 6.26e-15
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 666 AQAQHELEIKKLKELMSATEKARREKWISEKTKKIKEvtvrglepEIQKLIARHKQEVRRLKSLHEAELLQSDERASQRC 745
Cdd:COG1196 210 EKAERYRELKEELKELEAELLLLKLRELEAELEELEA--------ELEELEAELEELEAELAELEAELEELRLELEELEL 281
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 746 LRQAEELREQLEREKEALGQQERERARQR---FQQHLEQEQWALQQQRQRLySEVAEERERLGQQAARQRAELEELRQQL 822
Cdd:COG1196 282 ELEEAQAEEYELLAELARLEQDIARLEERrreLEERLEELEEELAELEEEL-EELEEELEELEEELEEAEEELEEAEAEL 360
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 823 EESSSALTRALRAEFEKGREEQERRHQmELNTLKQQLELERQAWEAGRTRKEeawLLNREQELREEIRKGRDKEIELvih 902
Cdd:COG1196 361 AEAEEALLEAEAELAEAEEELEELAEE-LLEALRAAAELAAQLEELEEAEEA---LLERLERLEEELEELEEALAEL--- 433
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 903 RLEADMALAKEESEKAAESRIKRLRDKYEAELSELEQSERKLQERCSELKGQLGEAEGENLRLQGLVRQKERALEDAQAV 982
Cdd:COG1196 434 EEEEEEEEEALEEAAEEEAELEEEEEALLELLAELLEEAALLEAALAELLEELAEAAARLLLLLEAEADYEGFLEGVKAA 513
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 983 neqlsSERSNLAQVIRQEFEDRLAASEEETRQAKAELATLQARQQLELEEVHRRVKTALARKEEAVSSLRTQHEAAVKRA 1062
Cdd:COG1196 514 -----LLLAGLRGLAGAVAVLIGVEAAYEAALEAALAAALQNIVVEDDEVAAAAIEYLKAAKAGRATFLPLDKIRARAAL 588
|
410
....*....|..
gi 111955084 1063 DHLEELLEQHRR 1074
Cdd:COG1196 589 AAALARGAIGAA 600
|
|
| Smc |
COG1196 |
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
793-1075 |
6.43e-15 |
|
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 79.98 E-value: 6.43e-15
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 793 LYSEVAEERERLGQQA--ARQRAELEELRQQLEESSSALTRALRAEFEKGREEQERRHQMELNTLKQQLELERQAWEAGR 870
Cdd:COG1196 194 ILGELERQLEPLERQAekAERYRELKEELKELEAELLLLKLRELEAELEELEAELEELEAELEELEAELAELEAELEELR 273
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 871 TRKEEAwllnreqELREEIRKGRDKEIELVIHRLEADMALAKEEsEKAAESRIKRLrdkyEAELSELEQSERKLQERCSE 950
Cdd:COG1196 274 LELEEL-------ELELEEAQAEEYELLAELARLEQDIARLEER-RRELEERLEEL----EEELAELEEELEELEEELEE 341
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 951 LKGQLGEAEGENLRLQGLVRQKERALEDAQAVNEQLSSERSNLAQVIRQEFEDRLAASEEETRQAKAELATLQARQQLEL 1030
Cdd:COG1196 342 LEEELEEAEEELEEAEAELAEAEEALLEAEAELAEAEEELEELAEELLEALRAAAELAAQLEELEEAEEALLERLERLEE 421
|
250 260 270 280
....*....|....*....|....*....|....*....|....*
gi 111955084 1031 EEvhRRVKTALARKEEAVSSLRTQHEAAVKRADHLEELLEQHRRP 1075
Cdd:COG1196 422 EL--EELEEALAELEEEEEEEEEALEEAAEEEAELEEEEEALLEL 464
|
|
| Smc |
COG1196 |
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning]; ... |
572-1046 |
2.06e-14 |
|
Chromosome segregation ATPase Smc [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 440809 [Multi-domain] Cd Length: 983 Bit Score: 78.05 E-value: 2.06e-14
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 572 RLKLEVEEKKQAMLLLQRALA---QQRDLTARRVKETEKALsRQLQRQREHYEATIQRHLAFIDQLIEDKKVLSEKCEAV 648
Cdd:COG1196 278 ELELELEEAQAEEYELLAELArleQDIARLEERRRELEERL-EELEEELAELEEELEELEEELEELEEELEEAEEELEEA 356
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 649 VAELKQEDQRCTERVAQAQAQHELEIKKLKELMSATEKARREKWISEKTKKIKEvtvrglepEIQKLIARHKQEVRRLKS 728
Cdd:COG1196 357 EAELAEAEEALLEAEAELAEAEEELEELAEELLEALRAAAELAAQLEELEEAEE--------ALLERLERLEEELEELEE 428
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 729 LHEAELLQSDERASQRCLRQAEELREQLEREKEALGQQERERARQRFQQHLEQEQWALQQQRQRLYSEVAEERERLGQQA 808
Cdd:COG1196 429 ALAELEEEEEEEEEALEEAAEEEAELEEEEEALLELLAELLEEAALLEAALAELLEELAEAAARLLLLLEAEADYEGFLE 508
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 809 ARQRAEL------------------EELRQQLEESSSAL---------------------TRALRAEFEkgREEQERRHQ 849
Cdd:COG1196 509 GVKAALLlaglrglagavavligveAAYEAALEAALAAAlqnivveddevaaaaieylkaAKAGRATFL--PLDKIRARA 586
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 850 MELNTLKQQLELERQAWEAGRTRKEEAWLLNREQELREEIRKGRDKEIELVIHRLEADMALAKEESEKAAESRIKRLRDK 929
Cdd:COG1196 587 ALAAALARGAIGAAVDLVASDLREADARYYVLGDTLLGRTLVAARLEAALRRAVTLAGRLREVTLEGEGGSAGGSLTGGS 666
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 930 YEAELSELEQSERKLQERCSELKGQLGEAEGENLRLQGLVRQKERALEDAQAVNEQLSSERSNLAQVIRQEFEDRLAASE 1009
Cdd:COG1196 667 RRELLAALLEAEAELEELAERLAEEELELEEALLAEEEEERELAEAEEERLEEELEEEALEEQLEAEREELLEELLEEEE 746
|
490 500 510
....*....|....*....|....*....|....*..
gi 111955084 1010 EETRQAKAELATLqarqqLELEEVHRRVKTALARKEE 1046
Cdd:COG1196 747 LLEEEALEELPEP-----PDLEELERELERLEREIEA 778
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
773-1073 |
2.25e-12 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 71.63 E-value: 2.25e-12
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 773 QRFQQHLEQEQWALQQQRqrlYSEVAEERERLGQQAARQRAELEELRQQLEESSSALTRaLRAEFEKGREEQERRhQMEL 852
Cdd:TIGR02168 216 KELKAELRELELALLVLR---LEELREELEELQEELKEAEEELEELTAELQELEEKLEE-LRLEVSELEEEIEEL-QKEL 290
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 853 NTLKQQL-ELERQAweaGRTRKEEAWLLNREQELREEIRKGRDKEIEL--VIHRLEADMALAKEESEkAAESRIKRLRDK 929
Cdd:TIGR02168 291 YALANEIsRLEQQK---QILRERLANLERQLEELEAQLEELESKLDELaeELAELEEKLEELKEELE-SLEAELEELEAE 366
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 930 YEaelsELEQSERKLQERCSELKGQLGEAEGENLRLQGLVRQKERALEDAQAVNEQLSSERSNLAQVIRQEFEDRLAASE 1009
Cdd:TIGR02168 367 LE----ELESRLEELEEQLETLRSKVAQLELQIASLNNEIERLEARLERLEDRRERLQQEIEELLKKLEEAELKELQAEL 442
|
250 260 270 280 290 300
....*....|....*....|....*....|....*....|....*....|....*....|....
gi 111955084 1010 EETRQAKAELATLQARQQLELEEVHRRvktaLARKEEAVSSLRTQHEAAVKRADHLEELLEQHR 1073
Cdd:TIGR02168 443 EELEEELEELQEELERLEEALEELREE----LEEAEQALDAAERELAQLQARLDSLERLQENLE 502
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
695-1025 |
2.82e-11 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 68.16 E-value: 2.82e-11
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 695 EKTKKIKEVT--VRGLEPEIQKLiarhKQEVRRLKslHEAELLQSDERASQRCLRQAEELREQLEREKEALGQQERERAR 772
Cdd:TIGR02168 674 ERRREIEELEekIEELEEKIAEL----EKALAELR--KELEELEEELEQLRKELEELSRQISALRKDLARLEAEVEQLEE 747
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 773 QRFQQHLEQEQwaLQQQRQRLYSEVAEERERLgqqaarqrAELEELRQQLEESSSALTRALRAEFEKGREEQERRHQMEL 852
Cdd:TIGR02168 748 RIAQLSKELTE--LEAEIEELEERLEEAEEEL--------AEAEAEIEELEAQIEQLKEELKALREALDELRAELTLLNE 817
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 853 NTLKQQLELERQAWEAGRTRKEEAWLLNREQELREeirkgrdkEIELVIHRLEaDMALAKEESEKAAESrikrlrdkYEA 932
Cdd:TIGR02168 818 EAANLRERLESLERRIAATERRLEDLEEQIEELSE--------DIESLAAEIE-ELEELIEELESELEA--------LLN 880
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 933 ELSELEQSERKLQERCSELKGQLGEAEGENLRLQGLVRQKERALEDAQAVNEQLSSERSNLAQVIRQEFEDRLAASEEET 1012
Cdd:TIGR02168 881 ERASLEEALALLRSELEELSEELRELESKRSELRRELEELREKLAQLELRLEGLEVRIDNLQERLSEEYSLTLEEAEALE 960
|
330
....*....|...
gi 111955084 1013 RQAKAELATLQAR 1025
Cdd:TIGR02168 961 NKIEDDEEEARRR 973
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
673-1033 |
3.94e-11 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 67.40 E-value: 3.94e-11
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 673 EIKKLKELMSATEKARREkwisektkkIKEVTVRglEPEIQKLIARHKQEVRRLKSLHEAELLQSDERASQRCLRQaeel 752
Cdd:TIGR02169 161 EIAGVAEFDRKKEKALEE---------LEEVEEN--IERLDLIIDEKRQQLERLRREREKAERYQALLKEKREYEG---- 225
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 753 rEQLEREKEALGQQERERARQRfqQHLEQEQWALQQQRQRLYSEVAEERERLGQQAARQRAELEE----LRQQLEESSSA 828
Cdd:TIGR02169 226 -YELLKEKEALERQKEAIERQL--ASLEEELEKLTEEISELEKRLEEIEQLLEELNKKIKDLGEEeqlrVKEKIGELEAE 302
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 829 LTRALRAEFEKGREEQ---ERRHQMELNTLKQQLELERQAWEAGRTRKEEAWLLNREQELREEIRKGRDKeielvIHRLE 905
Cdd:TIGR02169 303 IASLERSIAEKERELEdaeERLAKLEAEIDKLLAEIEELEREIEEERKRRDKLTEEYAELKEELEDLRAE-----LEEVD 377
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 906 ADMALAKEESeKAAESRIkrlrDKYEAELSELEQSERKLQERCSELKGQLGEAEGENLRLQGLVRQKERALEDAQAVNEQ 985
Cdd:TIGR02169 378 KEFAETRDEL-KDYREKL----EKLKREINELKRELDRLQEELQRLSEELADLNAAIAGIEAKINELEEEKEDKALEIKK 452
|
330 340 350 360 370
....*....|....*....|....*....|....*....|....*....|....
gi 111955084 986 LSSERSNLAQV---IRQEFEDR---LAASEEETRQAKAELATLQARQQLELEEV 1033
Cdd:TIGR02169 453 QEWKLEQLAADlskYEQELYDLkeeYDRVEKELSKLQRELAEAEAQARASEERV 506
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
635-999 |
8.25e-11 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 66.63 E-value: 8.25e-11
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 635 IEDKKVLSEKCEAVVAELKQEDQRCTERVAQAQAQHELEIKK----LKELMSATEKARREK-----WISEKTKKIKEVTV 705
Cdd:TIGR02169 179 LEEVEENIERLDLIIDEKRQQLERLRREREKAERYQALLKEKreyeGYELLKEKEALERQKeaierQLASLEEELEKLTE 258
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 706 R--GLEPEIQKLIARHKQEVRRLKSLHEAELL--QSDERASQRCLRQAEELREQLEREKEALGQQERERARQRFQQHLEQ 781
Cdd:TIGR02169 259 EisELEKRLEEIEQLLEELNKKIKDLGEEEQLrvKEKIGELEAEIASLERSIAEKERELEDAEERLAKLEAEIDKLLAEI 338
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 782 EQWALQQQRQRLysevaeERERLGQQAARQRAELEELRQQLEESSSALtRALRAEFEKGREEQERrHQMELNTLKQqlEL 861
Cdd:TIGR02169 339 EELEREIEEERK------RRDKLTEEYAELKEELEDLRAELEEVDKEF-AETRDELKDYREKLEK-LKREINELKR--EL 408
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 862 ERQAWEAGRTRKEEAwllnreqELREEIRKGRDKEIELVIHRLEADMALAKEESEKaaeSRIKRLRDKYEAELSELEQSE 941
Cdd:TIGR02169 409 DRLQEELQRLSEELA-------DLNAAIAGIEAKINELEEEKEDKALEIKKQEWKL---EQLAADLSKYEQELYDLKEEY 478
|
330 340 350 360 370
....*....|....*....|....*....|....*....|....*....|....*...
gi 111955084 942 RKLQERCSELKGQLGEAEGEnlrlqglVRQKERALEDAQAVNEQLSSERSNLAQVIRQ 999
Cdd:TIGR02169 479 DRVEKELSKLQRELAEAEAQ-------ARASEERVRGGRAVEEVLKASIQGVHGTVAQ 529
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
564-1071 |
3.41e-10 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 64.31 E-value: 3.41e-10
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 564 SEVSTSVMRLKLEVEEKKQAMLLLQRAL----AQQRDLTARrvKETEKALSRQLQRQREHYEATIQRHLAFIDQLIEDKK 639
Cdd:TIGR02168 263 QELEEKLEELRLEVSELEEEIEELQKELyalaNEISRLEQQ--KQILRERLANLERQLEELEAQLEELESKLDELAEELA 340
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 640 VLSEKCEAVVAELKQEDQRCTERVAQAQAQHELEIKKLKELmsaTEKARREKWISEKTKKIKEvTVRGLEPEIQKLIARH 719
Cdd:TIGR02168 341 ELEEKLEELKEELESLEAELEELEAELEELESRLEELEEQL---ETLRSKVAQLELQIASLNN-EIERLEARLERLEDRR 416
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 720 KQEVRRLKSlHEAELLQSDERASQRCLRQAEELREQLEREKEALgQQERERARQRFQQhLEQEQWALQQQRQRLYSEVAE 799
Cdd:TIGR02168 417 ERLQQEIEE-LLKKLEEAELKELQAELEELEEELEELQEELERL-EEALEELREELEE-AEQALDAAERELAQLQARLDS 493
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 800 ERERLGQQAARQRAELEELRQQL----------------EESSSALTRALRA-----------------EFEKgREEQER 846
Cdd:TIGR02168 494 LERLQENLEGFSEGVKALLKNQSglsgilgvlselisvdEGYEAAIEAALGGrlqavvvenlnaakkaiAFLK-QNELGR 572
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 847 RHQMELNTLKQQL----ELERQAWEAG----------------------------------------RTRKEEA------ 876
Cdd:TIGR02168 573 VTFLPLDSIKGTEiqgnDREILKNIEGflgvakdlvkfdpklrkalsyllggvlvvddldnalelakKLRPGYRivtldg 652
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 877 ------WLLNREQELREEIRKGRDKEIElvihRLEADMALAkEESEKAAESRIKRLRDKYEAELSELEQSERKLQE---R 947
Cdd:TIGR02168 653 dlvrpgGVITGGSAKTNSSILERRREIE----ELEEKIEEL-EEKIAELEKALAELRKELEELEEELEQLRKELEElsrQ 727
|
490 500 510 520 530 540 550 560
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 948 CSELKGQLGEAEGENLRLQGLVRQKERALEDAQAVNEQLSSERSNLAQVIrQEFEDRLAASEEETRQAKAELATLQaRQQ 1027
Cdd:TIGR02168 728 ISALRKDLARLEAEVEQLEERIAQLSKELTELEAEIEELEERLEEAEEEL-AEAEAEIEELEAQIEQLKEELKALR-EAL 805
|
570 580 590 600
....*....|....*....|....*....|....*....|....
gi 111955084 1028 LELEEVHRRVKTALARKEEAVSSLRTQHEAAVKRADHLEELLEQ 1071
Cdd:TIGR02168 806 DELRAELTLLNEEAANLRERLESLERRIAATERRLEDLEEQIEE 849
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
593-899 |
2.65e-09 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 61.61 E-value: 2.65e-09
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 593 QQRDLTARRVKETEKALSR------QLQRQREHYEATIQRHLAFIDQ-----------LIEDKKVLSEKCEAVVAELKQE 655
Cdd:TIGR02168 172 ERRKETERKLERTRENLDRledilnELERQLKSLERQAEKAERYKELkaelrelelalLVLRLEELREELEELQEELKEA 251
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 656 DQRCTERVAQAQAQHEleikKLKELMSatEKARREKWISEKTKKIKEVT--VRGLEPEIQKLIARHKQEVRRLKSLhEAE 733
Cdd:TIGR02168 252 EEELEELTAELQELEE----KLEELRL--EVSELEEEIEELQKELYALAneISRLEQQKQILRERLANLERQLEEL-EAQ 324
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 734 LLQSDERASQRCLRQAEELREQLEREKEALGQQERERARQRFQQHLEQEQWALQQQRQRLYSEVAEERerlgQQAARQRA 813
Cdd:TIGR02168 325 LEELESKLDELAEELAELEEKLEELKEELESLEAELEELEAELEELESRLEELEEQLETLRSKVAQLE----LQIASLNN 400
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 814 ELEELRQQLEESSSALTRA---LRAEFEKGREEQERRHQMELNTLKQQLELERQAWEAGRTRKEEawLLNREQELREEIR 890
Cdd:TIGR02168 401 EIERLEARLERLEDRRERLqqeIEELLKKLEEAELKELQAELEELEEELEELQEELERLEEALEE--LREELEEAEQALD 478
|
....*....
gi 111955084 891 KGRDKEIEL 899
Cdd:TIGR02168 479 AAERELAQL 487
|
|
| YhaN |
COG4717 |
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; |
581-1073 |
2.70e-09 |
|
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown];
Pssm-ID: 443752 [Multi-domain] Cd Length: 641 Bit Score: 61.32 E-value: 2.70e-09
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 581 KQAMLLLQRALAQQRDLTARRVKETEKALsRQLQRQREHYEATIQRhLAFIDQLIEDKKVLSEKCEAVVAELKQEDQRCT 660
Cdd:COG4717 52 EKEADELFKPQGRKPELNLKELKELEEEL-KEAEEKEEEYAELQEE-LEELEEELEELEAELEELREELEKLEKLLQLLP 129
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 661 ERVAQAQAQHELE--IKKLKELmsateKARREKWISektkkiKEVTVRGLEPEIQKLiARHKQEVRRLKSLHEAELLQSD 738
Cdd:COG4717 130 LYQELEALEAELAelPERLEEL-----EERLEELRE------LEEELEELEAELAEL-QEELEELLEQLSLATEEELQDL 197
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 739 ERASQRCLRQAEELREQLEREKEALGQQERERARQRFQQHLEQEQWALQQQRQ--RLYSEVAEERERLGQQAARQRAELE 816
Cdd:COG4717 198 AEELEELQQRLAELEEELEEAQEELEELEEELEQLENELEAAALEERLKEARLllLIAAALLALLGLGGSLLSLILTIAG 277
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 817 ELRQQLEESSSALTRALRAEFEKGREEQERRHQMELNTLKQQL---ELERQAWEAGRTRKEEAWLLNREQELREEIRKGR 893
Cdd:COG4717 278 VLFLVLGLLALLFLLLAREKASLGKEAEELQALPALEELEEEEleeLLAALGLPPDLSPEELLELLDRIEELQELLREAE 357
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 894 DKEIELVIHRLE----ADMALAKEESEKAAESRIKRLRdKYEAELSELEQSERKLQERCSELKGQLGEAEGENLRLQglV 969
Cdd:COG4717 358 ELEEELQLEELEqeiaALLAEAGVEDEEELRAALEQAE-EYQELKEELEELEEQLEELLGELEELLEALDEEELEEE--L 434
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 970 RQKERALEDAQAVNEQLSSERSNLAQVIRQefedrlAASEEETRQAKAELATLQARQQlELEEVHRRVKTALARKEEAVS 1049
Cdd:COG4717 435 EELEEELEELEEELEELREELAELEAELEQ------LEEDGELAELLQELEELKAELR-ELAEEWAALKLALELLEEARE 507
|
490 500
....*....|....*....|....*
gi 111955084 1050 SLRTQHEAAV-KRADHLEELLEQHR 1073
Cdd:COG4717 508 EYREERLPPVlERASEYFSRLTDGR 532
|
|
| PRK03918 |
PRK03918 |
DNA double-strand break repair ATPase Rad50; |
607-1074 |
3.43e-09 |
|
DNA double-strand break repair ATPase Rad50;
Pssm-ID: 235175 [Multi-domain] Cd Length: 880 Bit Score: 61.23 E-value: 3.43e-09
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 607 KALSRQLQRQREHYEATIQRHlAFIDQLIEDKKVLSEKCEAVVAELKQEDQRCTERVAQAQAqhelEIKKLKELMSATEK 686
Cdd:PRK03918 168 GEVIKEIKRRIERLEKFIKRT-ENIEELIKEKEKELEEVLREINEISSELPELREELEKLEK----EVKELEELKEEIEE 242
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 687 ARREKWISEKTKKIKEVTVRGLEPEIQKLIARHK---QEVRRLKSLHEAEllqsderasqrclrqaeelreqlerekeal 763
Cdd:PRK03918 243 LEKELESLEGSKRKLEEKIRELEERIEELKKEIEeleEKVKELKELKEKA------------------------------ 292
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 764 gqqERERARQRFQQHLEQEQWALQQQRQRLYSEVAEERERLgQQAARQRAELEELRQQLEESSSALtralrAEFEKGREE 843
Cdd:PRK03918 293 ---EEYIKLSEFYEEYLDELREIEKRLSRLEEEINGIEERI-KELEEKEERLEELKKKLKELEKRL-----EELEERHEL 363
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 844 QERRHQMELNtlKQQLELERQAWEAGRTRKEEAWLLNREQELREEIRKGRDKEIELviHRLEADMALAKEESEKA----- 918
Cdd:PRK03918 364 YEEAKAKKEE--LERLKKRLTGLTPEKLEKELEELEKAKEEIEEEISKITARIGEL--KKEIKELKKAIEELKKAkgkcp 439
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 919 ------AESRIKRLRDKYEAELSELEQSERKLQERCSELKGQLGEAEGENLRLQGLVRQKERAledaqavnEQLSSERSN 992
Cdd:PRK03918 440 vcgrelTEEHRKELLEEYTAELKRIEKELKEIEEKERKLRKELRELEKVLKKESELIKLKELA--------EQLKELEEK 511
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 993 LAQVIRQEFEdrlaASEEETRQAKAELATLQARQqleleevhRRVKTALARKEEAVSSLRTQHEAAVKRADHLEELLEQH 1072
Cdd:PRK03918 512 LKKYNLEELE----KKAEEYEKLKEKLIKLKGEI--------KSLKKELEKLEELKKKLAELEKKLDELEEELAELLKEL 579
|
..
gi 111955084 1073 RR 1074
Cdd:PRK03918 580 EE 581
|
|
| sbcc |
TIGR00618 |
exonuclease SbcC; All proteins in this family for which functions are known are part of an ... |
578-1074 |
5.12e-09 |
|
exonuclease SbcC; All proteins in this family for which functions are known are part of an exonuclease complex with sbcD homologs. This complex is involved in the initiation of recombination to regulate the levels of palindromic sequences in DNA. This family is based on the phylogenomic analysis of JA Eisen (1999, Ph.D. Thesis, Stanford University). [DNA metabolism, DNA replication, recombination, and repair]
Pssm-ID: 129705 [Multi-domain] Cd Length: 1042 Bit Score: 60.75 E-value: 5.12e-09
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 578 EEKKQAMLLLQRALAQQRDLTArrVKETEKALSRQLQRQREHYEATIQRHLAFIDqliedkkvlsEKCEAVVAELKQEDQ 657
Cdd:TIGR00618 369 EISCQQHTLTQHIHTLQQQKTT--LTQKLQSLCKELDILQREQATIDTRTSAFRD----------LQGQLAHAKKQQELQ 436
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 658 RCTERVAQAQAQHELEIKKLKELMsATEKARREKWISEKTKKIKEVTVRglEPEIQKLIARHKQEVRRLKSLHEAELLQS 737
Cdd:TIGR00618 437 QRYAELCAAAITCTAQCEKLEKIH-LQESAQSLKEREQQLQTKEQIHLQ--ETRKKAVVLARLLELQEEPCPLCGSCIHP 513
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 738 DERASQRCLRQAEELREQLEREKEALGQQERERARQRFQQHLEQeQWALQQQRQRL---YSEVAEERERLGQQAARQRAE 814
Cdd:TIGR00618 514 NPARQDIDNPGPLTRRMQRGEQTYAQLETSEEDVYHQLTSERKQ-RASLKEQMQEIqqsFSILTQCDNRSKEDIPNLQNI 592
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 815 LEELRQQLEESSSALTRALRAEFEKGREEQERRHQMELNTLKQQLELERQAWEAGRTRKEEAWLLNREQELREEIRKgrD 894
Cdd:TIGR00618 593 TVRLQDLTEKLSEAEDMLACEQHALLRKLQPEQDLQDVRLHLQQCSQELALKLTALHALQLTLTQERVREHALSIRV--L 670
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 895 KEIELVIHRLEADMALAKEESEKAAESRIKRLRDKYEAELSELEQSERKLQERCSELKGQLGEAEGENLRLQGLVRQ--- 971
Cdd:TIGR00618 671 PKELLASRQLALQKMQSEKEQLTYWKEMLAQCQTLLRELETHIEEYDREFNEIENASSSLGSDLAAREDALNQSLKElmh 750
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 972 ------KERALEDAQA-----VNEQLSSERSNLAQVI------RQEFEDRLAASEEETRQAKAELATLQARQQLELEEVH 1034
Cdd:TIGR00618 751 qartvlKARTEAHFNNneevtAALQTGAELSHLAAEIqffnrlREEDTHLLKTLEAEIGQEIPSDEDILNLQCETLVQEE 830
|
490 500 510 520
....*....|....*....|....*....|....*....|
gi 111955084 1035 RRVKTALARKEEAVSSLRTQHEAAVKRADHLEELLEQHRR 1074
Cdd:TIGR00618 831 EQFLSRLEEKSATLGEITHQLLKYEECSKQLAQLTQEQAK 870
|
|
| COG4913 |
COG4913 |
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown]; |
709-961 |
5.32e-09 |
|
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown];
Pssm-ID: 443941 [Multi-domain] Cd Length: 1089 Bit Score: 60.70 E-value: 5.32e-09
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 709 EPEIQKLIARHKQEVRRLKSLHEAELlqsDERASQRCLRQAEELREQLEREKEALGQQERERAR------QRFQQHLEQE 782
Cdd:COG4913 220 EPDTFEAADALVEHFDDLERAHEALE---DAREQIELLEPIRELAERYAAARERLAELEYLRAAlrlwfaQRRLELLEAE 296
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 783 QWALQQQRQRLysevAEERERLGQQAARQRAELEELRQQLEESSSALTRALRAEFEKGREEQERR------HQMELNTLK 856
Cdd:COG4913 297 LEELRAELARL----EAELERLEARLDALREELDELEAQIRGNGGDRLEQLEREIERLERELEERerrrarLEALLAALG 372
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 857 QQLELERQAWEAgrTRKEEAWLLNREQELREEIRKGRDKeielvihrleadmalakeesEKAAESRIKRLRDKYEAELSE 936
Cdd:COG4913 373 LPLPASAEEFAA--LRAEAAALLEALEEELEALEEALAE--------------------AEAALRDLRRELRELEAEIAS 430
|
250 260
....*....|....*....|....*....
gi 111955084 937 LEQS----ERKLQERCSELKGQLGEAEGE 961
Cdd:COG4913 431 LERRksniPARLLALRDALAEALGLDEAE 459
|
|
| DUF3584 |
pfam12128 |
Protein of unknown function (DUF3584); This protein is found in bacteria and eukaryotes. ... |
576-1060 |
1.29e-08 |
|
Protein of unknown function (DUF3584); This protein is found in bacteria and eukaryotes. Proteins in this family are typically between 943 to 1234 amino acids in length. This family contains a P-loop motif suggesting it is a nucleotide binding protein. It may be involved in replication.
Pssm-ID: 432349 [Multi-domain] Cd Length: 1191 Bit Score: 59.47 E-value: 1.29e-08
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 576 EVEEKKQAMLLLQRALAQQRDLTARRVKETEKALSRQ---LQRQREHYEATIQRHLAFIDQLIEDKKVLSEKCEAVVAEL 652
Cdd:pfam12128 277 RQEERQETSAELNQLLRTLDDQWKEKRDELNGELSAAdaaVAKDRSELEALEDQHGAFLDADIETAAADQEQLPSWQSEL 356
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 653 KQEDQRC---TERVAQAQAQHELEIKKLKElmsatEKARREKWISEKTKKIKEVTVRGLEPE---IQKLIA--RHKQEVR 724
Cdd:pfam12128 357 ENLEERLkalTGKHQDVTAKYNRRRSKIKE-----QNNRDIAGIKDKLAKIREARDRQLAVAeddLQALESelREQLEAG 431
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 725 RLKSLHEAELLQSdeRASQRCLRQAEELREQLEREKEALGQQERERARQRfQQHLEQEQWALQQQRQRLYSEVAEERERL 804
Cdd:pfam12128 432 KLEFNEEEYRLKS--RLGELKLRLNQATATPELLLQLENFDERIERAREE-QEAANAEVERLQSELRQARKRRDQASEAL 508
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 805 GQQAAR---QRAELEELRQQLEESSSALTRALRAEfekgreeqerrhqmelntlkqqlelerqaweAGRTRKEEAWLLNR 881
Cdd:pfam12128 509 RQASRRleeRQSALDELELQLFPQAGTLLHFLRKE-------------------------------APDWEQSIGKVISP 557
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 882 EQELREEIRKGRDKEI---ELVIHRLEADMALAKEESEKAAESRIKRLRDKYEAELseleQSERKLQERCSElkgQLGEA 958
Cdd:pfam12128 558 ELLHRTDLDPEVWDGSvggELNLYGVKLDLKRIDVPEWAASEEELRERLDKAEEAL----QSAREKQAAAEE---QLVQA 630
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 959 EGENLRLQGLVRQKERALEDAQAVNEQLSSERSNLAQVIRQEFEDRLAASEEETRQAKAELATLQARQQLELEEVHRRVK 1038
Cdd:pfam12128 631 NGELEKASREETFARTALKNARLDLRRLFDEKQSEKDKKNKALAERKDSANERLNSLEAQLKQLDKKHQAWLEEQKEQKR 710
|
490 500 510 520
....*....|....*....|....*....|....*....|
gi 111955084 1039 TA------------------LARKEEAVSSLRTQHEAAVK 1060
Cdd:pfam12128 711 EArtekqaywqvvegaldaqLALLKAAIAARRSGAKAELK 750
|
|
| PTZ00121 |
PTZ00121 |
MAEBL; Provisional |
534-1063 |
1.76e-08 |
|
MAEBL; Provisional
Pssm-ID: 173412 [Multi-domain] Cd Length: 2084 Bit Score: 59.00 E-value: 1.76e-08
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 534 DEMEKSGQDQLDSQQEGWVPEAGPGPLELGSEVSTSvmrlklevEEKKQAMLLLQRALAQQRDLTARRVKETEKAL-SRQ 612
Cdd:PTZ00121 1082 DAKEDNRADEATEEAFGKAEEAKKTETGKAEEARKA--------EEAKKKAEDARKAEEARKAEDARKAEEARKAEdAKR 1153
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 613 LQRQREHYEAtiqrHLAFIDQLIEDKKVLSEKCEAVVAElKQEDQRCTERVAQAQAQHELE-IKKLKELMSATEKARREK 691
Cdd:PTZ00121 1154 VEIARKAEDA----RKAEEARKAEDAKKAEAARKAEEVR-KAEELRKAEDARKAEAARKAEeERKAEEARKAEDAKKAEA 1228
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 692 WISEKTKKIKEVTVRGLEPEIQKLIARHKQEVRRLKSLHEAELLQSDERASQRCLRQAEELREQLEREKEALGQQERERA 771
Cdd:PTZ00121 1229 VKKAEEAKKDAEEAKKAEEERNNEEIRKFEEARMAHFARRQAAIKAEEARKADELKKAEEKKKADEAKKAEEKKKADEAK 1308
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 772 RQRFQQHLEQEQWALQQQRQRLYSEVAEERERLGQQAARQRAELEELRQQLEESSSaltralRAEFEKGREEQERRHQME 851
Cdd:PTZ00121 1309 KKAEEAKKADEAKKKAEEAKKKADAAKKKAEEAKKAAEAAKAEAEAAADEAEAAEE------KAEAAEKKKEEAKKKADA 1382
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 852 lntLKQQLELERQAWEAgRTRKEEAWLLNREQELREEIRKGRDKEIELVIHRLEADMALAKEESEKAAESRIKRLRDKYE 931
Cdd:PTZ00121 1383 ---AKKKAEEKKKADEA-KKKAEEDKKKADELKKAAAAKKKADEAKKKAEEKKKADEAKKKAEEAKKADEAKKKAEEAKK 1458
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 932 AELSELEQSERKlqeRCSELKGQLGEAEGENLRLQGLVRQKERALEDAQAVNEQLSSERSNLAQVIRQEFEDRLAASE-- 1009
Cdd:PTZ00121 1459 AEEAKKKAEEAK---KADEAKKKAEEAKKADEAKKKAEEAKKKADEAKKAAEAKKKADEAKKAEEAKKADEAKKAEEAkk 1535
|
490 500 510 520 530
....*....|....*....|....*....|....*....|....*....|....*
gi 111955084 1010 -EETRQAKAELATLQARQQLELEEVHRRVKTALARKEEAVSSLRTQHEAAVKRAD 1063
Cdd:PTZ00121 1536 aDEAKKAEEKKKADELKKAEELKKAEEKKKAEEAKKAEEDKNMALRKAEEAKKAE 1590
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
870-1074 |
1.85e-08 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 58.91 E-value: 1.85e-08
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 870 RTRKEEAWL--------LNREQELREEIRKGRDKeIELVIHRLEADMALAKEESEKAAESRIKRLRDkYEAELSELEQSE 941
Cdd:TIGR02168 171 KERRKETERklertrenLDRLEDILNELERQLKS-LERQAEKAERYKELKAELRELELALLVLRLEE-LREELEELQEEL 248
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 942 RKLQERCSELKGQLGEAEGENLRLQGLVRQKERALEDAQAVNEQLSSERSNLAQVIrQEFEDRLAASEEETRQAKAELAT 1021
Cdd:TIGR02168 249 KEAEEELEELTAELQELEEKLEELRLEVSELEEEIEELQKELYALANEISRLEQQK-QILRERLANLERQLEELEAQLEE 327
|
170 180 190 200 210
....*....|....*....|....*....|....*....|....*....|....*....
gi 111955084 1022 LQARQQLELEEVHRR------VKTALARKEEAVSSLRTQHEAAVKRADHLEELLEQHRR 1074
Cdd:TIGR02168 328 LESKLDELAEELAELeekleeLKEELESLEAELEELEAELEELESRLEELEEQLETLRS 386
|
|
| DUF5401 |
pfam17380 |
Family of unknown function (DUF5401); This is a family of unknown function found in ... |
723-1051 |
2.53e-08 |
|
Family of unknown function (DUF5401); This is a family of unknown function found in Chromadorea.
Pssm-ID: 375164 [Multi-domain] Cd Length: 722 Bit Score: 58.21 E-value: 2.53e-08
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 723 VRRLKSLHEAELLQSDERASQRCLRQAEELREQLEREKEALGQQERERarqrfqQHLEQEQWALQQQRQRLYSEVAEERE 802
Cdd:pfam17380 278 VQHQKAVSERQQQEKFEKMEQERLRQEKEEKAREVERRRKLEEAEKAR------QAEMDRQAAIYAEQERMAMERERELE 351
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 803 RLgQQAARQRaELEELRQQleesssaltrALRAEFEKGREEQerRHQMELntlKQQLELERQAWEAGRtrkeeawllnrE 882
Cdd:pfam17380 352 RI-RQEERKR-ELERIRQE----------EIAMEISRMRELE--RLQMER---QQKNERVRQELEAAR-----------K 403
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 883 QELREEIRKGRDKEielvihrLEADMALAKEESEKAAESRIKRLRDKYEAELSELEQSERKLQERCSELKGQLGEAEGEN 962
Cdd:pfam17380 404 VKILEEERQRKIQQ-------QKVEMEQIRAEQEEARQREVRRLEEERAREMERVRLEEQERQQQVERLRQQEEERKRKK 476
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 963 LRLQGLVRQKERALEDAQAVNEQLSSER-------SNLAQVIRQEFEDRLAASEEETRQAKAElatLQARQQLELEEvHR 1035
Cdd:pfam17380 477 LELEKEKRDRKRAEEQRRKILEKELEERkqamieeERKRKLLEKEMEERQKAIYEEERRREAE---EERRKQQEMEE-RR 552
|
330
....*....|....*.
gi 111955084 1036 RVKTALARKEEAVSSL 1051
Cdd:pfam17380 553 RIQEQMRKATEERSRL 568
|
|
| EnvC |
COG4942 |
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, ... |
781-1028 |
2.55e-08 |
|
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 443969 [Multi-domain] Cd Length: 377 Bit Score: 57.47 E-value: 2.55e-08
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 781 QEQWALQQQRQRLYSEVAEERERLgQQAARQRAELEELRQQLEESSSALTRALRAefekgREEQERRHQMELNTLKQQLE 860
Cdd:COG4942 20 DAAAEAEAELEQLQQEIAELEKEL-AALKKEEKALLKQLAALERRIAALARRIRA-----LEQELAALEAELAELEKEIA 93
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 861 LERQAWEAGRTRKEEAwllnreqeLREEIRKGRDKEIELVIHRLEADMALAKEESEKAAESRIKRLRDKYEAELSELEQS 940
Cdd:COG4942 94 ELRAELEAQKEELAEL--------LRALYRLGRQPPLALLLSPEDFLDAVRRLQYLKYLAPARREQAEELRADLAELAAL 165
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 941 ERKLQERCSELKGQLGEAEGENLRLQGLVRQKERALEDAQAVNEQLSSERSNLAQVIR--QEFEDRLAASEEETRQAKAE 1018
Cdd:COG4942 166 RAELEAERAELEALLAELEEERAALEALKAERQKLLARLEKELAELAAELAELQQEAEelEALIARLEAEAAAAAERTPA 245
|
250
....*....|
gi 111955084 1019 LATLQARQQL 1028
Cdd:COG4942 246 AGFAALKGKL 255
|
|
| DUF5401 |
pfam17380 |
Family of unknown function (DUF5401); This is a family of unknown function found in ... |
601-899 |
4.37e-08 |
|
Family of unknown function (DUF5401); This is a family of unknown function found in Chromadorea.
Pssm-ID: 375164 [Multi-domain] Cd Length: 722 Bit Score: 57.44 E-value: 4.37e-08
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 601 RVKETEKALSRQLQRQREHYEATIQRHLAFIDQ--LIEDKKVLSEKCEAVVAELKQED-QRCTERVAQAQAQheLEIKKL 677
Cdd:pfam17380 300 RLRQEKEEKAREVERRRKLEEAEKARQAEMDRQaaIYAEQERMAMERERELERIRQEErKRELERIRQEEIA--MEISRM 377
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 678 KEL----MSATEKARREKWISEKTKKIKEvtvrgLEPEIQKLIARHKQEVRRLKSLHE---AELLQSDERASQRCLRQAE 750
Cdd:pfam17380 378 RELerlqMERQQKNERVRQELEAARKVKI-----LEEERQRKIQQQKVEMEQIRAEQEearQREVRRLEEERAREMERVR 452
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 751 ELREQLEREKEALGQQERERARQRFQQHLEQEQWAL-QQQRQRLYSEVAEERERLGQQAARQRAELEelrQQLEESSSAL 829
Cdd:pfam17380 453 LEEQERQQQVERLRQQEEERKRKKLELEKEKRDRKRaEEQRRKILEKELEERKQAMIEEERKRKLLE---KEMEERQKAI 529
|
250 260 270 280 290 300 310
....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 830 TRalraEFEKGREEQERRHQMELNTLKQQLELERQAWEAgRTRKEEawlLNREQELREEIRKGRDKEIEL 899
Cdd:pfam17380 530 YE----EERRREAEEERRKQQEMEERRRIQEQMRKATEE-RSRLEA---MEREREMMRQIVESEKARAEY 591
|
|
| YhaN |
COG4717 |
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; |
696-1074 |
4.83e-08 |
|
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown];
Pssm-ID: 443752 [Multi-domain] Cd Length: 641 Bit Score: 57.08 E-value: 4.83e-08
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 696 KTKKIKEVTVRGLEPEIQKLIARHKQEVRRLKSLHEAELLQSDERASQRCLRQAEELREQLEREKEALgqQERERARQRF 775
Cdd:COG4717 64 RKPELNLKELKELEEELKEAEEKEEEYAELQEELEELEEELEELEAELEELREELEKLEKLLQLLPLY--QELEALEAEL 141
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 776 QQhlEQEQWALQQQRQRLYSEVAEERERLGQQAARQRAELEELRQQLEESSSALTRALRAEFEKGREEQERRHQmELNTL 855
Cdd:COG4717 142 AE--LPERLEELEERLEELRELEEELEELEAELAELQEELEELLEQLSLATEEELQDLAEELEELQQRLAELEE-ELEEA 218
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 856 KQQLELERQAWEAGRTRKEEAWLLNREQELREEIR--------KGRDKEIELVI-------------------------- 901
Cdd:COG4717 219 QEELEELEEELEQLENELEAAALEERLKEARLLLLiaaallalLGLGGSLLSLIltiagvlflvlgllallflllareka 298
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 902 -HRLEADMALAKEESEKAAESRIKRLRDKYEAELSELEQSERKLQERCSELKGQLGEAEGENLRLQGLVRQKERA--LED 978
Cdd:COG4717 299 sLGKEAEELQALPALEELEEEELEELLAALGLPPDLSPEELLELLDRIEELQELLREAEELEEELQLEELEQEIAalLAE 378
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 979 AQAVNE--------------QLSSERSNLAQVIRQEFEDRLAASEEETR-QAKAELATLQARQQlELEEVHRRVKTALAR 1043
Cdd:COG4717 379 AGVEDEeelraaleqaeeyqELKEELEELEEQLEELLGELEELLEALDEeELEEELEELEEELE-ELEEELEELREELAE 457
|
410 420 430
....*....|....*....|....*....|.
gi 111955084 1044 KEEAVSSLRTQHEAAVKRADHlEELLEQHRR 1074
Cdd:COG4717 458 LEAELEQLEEDGELAELLQEL-EELKAELRE 487
|
|
| PRK12704 |
PRK12704 |
phosphodiesterase; Provisional |
726-920 |
5.18e-08 |
|
phosphodiesterase; Provisional
Pssm-ID: 237177 [Multi-domain] Cd Length: 520 Bit Score: 56.71 E-value: 5.18e-08
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 726 LKSLHEAELLQSDERAsQRCLRQAEELREQLEREKEALGQQERERARQRFQQHLEQEQWALQQQRQRLysevaEERErlg 805
Cdd:PRK12704 25 RKKIAEAKIKEAEEEA-KRILEEAKKEAEAIKKEALLEAKEEIHKLRNEFEKELRERRNELQKLEKRL-----LQKE--- 95
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 806 QQAARQRAELEELRQQLEESSSALTRaLRAEFEKGREEQERRHQmelntlKQQLELERQaweAGRTrKEEAwllnrEQEL 885
Cdd:PRK12704 96 ENLDRKLELLEKREEELEKKEKELEQ-KQQELEKKEEELEELIE------EQLQELERI---SGLT-AEEA-----KEIL 159
|
170 180 190
....*....|....*....|....*....|....*
gi 111955084 886 REEIRKGRDKEIELVIHRLEADmalAKEESEKAAE 920
Cdd:PRK12704 160 LEKVEEEARHEAAVLIKEIEEE---AKEEADKKAK 191
|
|
| PRK02224 |
PRK02224 |
DNA double-strand break repair Rad50 ATPase; |
765-1073 |
7.01e-08 |
|
DNA double-strand break repair Rad50 ATPase;
Pssm-ID: 179385 [Multi-domain] Cd Length: 880 Bit Score: 56.97 E-value: 7.01e-08
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 765 QQERERARQRFQQHLE--QEQWALQQQRQRLYSEVAE---ERERLGQQAARQRAELEELRQQLEE--SSSALTRALRAEF 837
Cdd:PRK02224 233 RETRDEADEVLEEHEErrEELETLEAEIEDLRETIAEterEREELAEEVRDLRERLEELEEERDDllAEAGLDDADAEAV 312
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 838 EKGREEQERRhqmeLNTLKQQLELERQAweAGRTRKEEAWLLNREQELREEIRKGRDKEIELVIHRLEADMALAKEESEK 917
Cdd:PRK02224 313 EARREELEDR----DEELRDRLEECRVA--AQAHNEEAESLREDADDLEERAEELREEAAELESELEEAREAVEDRREEI 386
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 918 AA-ESRIKRLRDKYE---AELSELEQSERKLQERCSELKGQLGEAEGENLRLQGLVRQKERALEDAQAVNEQLSSERSNL 993
Cdd:PRK02224 387 EElEEEIEELRERFGdapVDLGNAEDFLEELREERDELREREAELEATLRTARERVEEAEALLEAGKCPECGQPVEGSPH 466
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 994 AQVIrQEFEDRLAASEEETRQAKAELATLQAR--QQLELEEVHRRVKTaLARKEEAVSSLRTQHEAAV-----------K 1060
Cdd:PRK02224 467 VETI-EEDRERVEELEAELEDLEEEVEEVEERleRAEDLVEAEDRIER-LEERREDLEELIAERRETIeekreraeelrE 544
|
330
....*....|...
gi 111955084 1061 RADHLEELLEQHR 1073
Cdd:PRK02224 545 RAAELEAEAEEKR 557
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
792-1071 |
1.52e-07 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 55.84 E-value: 1.52e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 792 RLYSEVAEERERLGQ---QAARQRAELEELRQQLEESSSALTRALRAEFEKGRE-----EQERRHQMELNTLKQQLELER 863
Cdd:TIGR02169 671 SEPAELQRLRERLEGlkrELSSLQSELRRIENRLDELSQELSDASRKIGEIEKEieqleQEEEKLKERLEELEEDLSSLE 750
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 864 QAWEAGRTRKEEawLLNREQELREEIRKgrdkeIELVIHRLEADMALAKEESEKAAESRIKRLRDKYEAELSELEQSERK 943
Cdd:TIGR02169 751 QEIENVKSELKE--LEARIEELEEDLHK-----LEEALNDLEARLSHSRIPEIQAELSKLEEEVSRIEARLREIEQKLNR 823
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 944 LQERCSELKGQLGEAEGENLRLQGLVRQKERALEDAQAVNEQLSSERSNLAQVIRqEFEDRLAASEEETRQAKAELATLQ 1023
Cdd:TIGR02169 824 LTLEKEYLEKEIQELQEQRIDLKEQIKSIEKEIENLNGKKEELEEELEELEAALR-DLESRLGDLKKERDELEAQLRELE 902
|
250 260 270 280
....*....|....*....|....*....|....*....|....*...
gi 111955084 1024 ARQQleleevhrRVKTALARKEEAVSSLRTQHEAAVKRADHLEELLEQ 1071
Cdd:TIGR02169 903 RKIE--------ELEAQIEKKRKRLSELKAKLEALEEELSEIEDPKGE 942
|
|
| mukB |
PRK04863 |
chromosome partition protein MukB; |
760-1072 |
2.19e-07 |
|
chromosome partition protein MukB;
Pssm-ID: 235316 [Multi-domain] Cd Length: 1486 Bit Score: 55.35 E-value: 2.19e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 760 KEALGQQERERARQRFQQHLEQEQWALQQQRQRLYSEVAEERERLGQQAARQR--AELEELRQQLEESSSAltRALRAEF 837
Cdd:PRK04863 300 RQLAAEQYRLVEMARELAELNEAESDLEQDYQAASDHLNLVQTALRQQEKIERyqADLEELEERLEEQNEV--VEEADEQ 377
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 838 EKGREEQERRHQMELNTLKQQLELERQAWEAGRTRK----------EEAWLLNREQELREE-----IRKGRDKEIELVIH 902
Cdd:PRK04863 378 QEENEARAEAAEEEVDELKSQLADYQQALDVQQTRAiqyqqavqalERAKQLCGLPDLTADnaedwLEEFQAKEQEATEE 457
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 903 RLEADMAL-----AKEESEKAAESrIKRLRDKYEAE---------LSELEqSERKLQERCSELKGQLGEAEGEnLRLQgl 968
Cdd:PRK04863 458 LLSLEQKLsvaqaAHSQFEQAYQL-VRKIAGEVSRSeawdvarelLRRLR-EQRHLAEQLQQLRMRLSELEQR-LRQQ-- 532
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 969 vRQKERALEDAQAVNEQLSSERSNLaqvirQEFEDRLAASEEETRQAKAELATLQARQQLELEEVHRRVKTALARK---- 1044
Cdd:PRK04863 533 -QRAERLLAEFCKRLGKNLDDEDEL-----EQLQEELEARLESLSESVSEARERRMALRQQLEQLQARIQRLAARApawl 606
|
330 340 350
....*....|....*....|....*....|
gi 111955084 1045 --EEAVSSLRTQHEAAVKRADHLEELLEQH 1072
Cdd:PRK04863 607 aaQDALARLREQSGEEFEDSQDVTEYMQQL 636
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
711-1071 |
2.69e-07 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 55.07 E-value: 2.69e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 711 EIQKLIARHKQEVRRLKSlHEAELLQSDERASQRclrqaeelreQLEREKEALGQQERERARQRFQQHLEQEQWALQQQR 790
Cdd:TIGR02169 685 GLKRELSSLQSELRRIEN-RLDELSQELSDASRK----------IGEIEKEIEQLEQEEEKLKERLEELEEDLSSLEQEI 753
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 791 QRLYSEVAEERERLgqqaARQRAELEELRQQLEEsssaLTRALRAEFEKgreeqerrhqmELNTLKQQLELERQAWEAgR 870
Cdd:TIGR02169 754 ENVKSELKELEARI----EELEEDLHKLEEALND----LEARLSHSRIP-----------EIQAELSKLEEEVSRIEA-R 813
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 871 TRKEEAwLLNREQELREEIRKGRDKEIELVIhrleaDMALAKEESEKAAESRIKRLRDKyEAELSELEQSERKLQERCSE 950
Cdd:TIGR02169 814 LREIEQ-KLNRLTLEKEYLEKEIQELQEQRI-----DLKEQIKSIEKEIENLNGKKEEL-EEELEELEAALRDLESRLGD 886
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 951 LKGQLGEAEGENLRLQGLVRQKERALEDAQAVNEQLSSERSNLAQVIrQEFEDRLAASEEET------RQAKAELATLQA 1024
Cdd:TIGR02169 887 LKKERDELEAQLRELERKIEELEAQIEKKRKRLSELKAKLEALEEEL-SEIEDPKGEDEEIPeeelslEDVQAELQRVEE 965
|
330 340 350 360
....*....|....*....|....*....|....*....|....*..
gi 111955084 1025 RQQlELEEVHRRVKTALARKEEAVSSLRTQHEAAVKRADHLEELLEQ 1071
Cdd:TIGR02169 966 EIR-ALEPVNMLAIQEYEEVLKRLDELKEKRAKLEEERKAILERIEE 1011
|
|
| PRK02224 |
PRK02224 |
DNA double-strand break repair Rad50 ATPase; |
796-1072 |
4.55e-07 |
|
DNA double-strand break repair Rad50 ATPase;
Pssm-ID: 179385 [Multi-domain] Cd Length: 880 Bit Score: 54.28 E-value: 4.55e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 796 EVAEERERLGQQAARQRAELEELRQQLEESSSALTRALRAEFEKGREE-------QERRHQME-LNTLKQQLELERQAWE 867
Cdd:PRK02224 416 ELREERDELREREAELEATLRTARERVEEAEALLEAGKCPECGQPVEGsphvetiEEDRERVEeLEAELEDLEEEVEEVE 495
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 868 AGRTRKEEAWLLNREQELREEIRkgrdkeiELVIHRLEADMALAKEESEKAAESRIKrlRDKYEAELSELEQSERKLQER 947
Cdd:PRK02224 496 ERLERAEDLVEAEDRIERLEERR-------EDLEELIAERRETIEEKRERAEELRER--AAELEAEAEEKREAAAEAEEE 566
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 948 CSELKGQLGEAEGE----NLRLQGLVRQKER--ALEDAQAVNEQLSSERSNLAQVIRQEfEDRLAASEEETRQAKAEL-- 1019
Cdd:PRK02224 567 AEEAREEVAELNSKlaelKERIESLERIRTLlaAIADAEDEIERLREKREALAELNDER-RERLAEKRERKRELEAEFde 645
|
250 260 270 280 290
....*....|....*....|....*....|....*....|....*....|....*
gi 111955084 1020 -ATLQARQQLE-LEEVHRRVKTALARKEEAVSSLRTQHEAAVKRADHLEELLEQH 1072
Cdd:PRK02224 646 aRIEEAREDKErAEEYLEQVEEKLDELREERDDLQAEIGAVENELEELEELRERR 700
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
573-1074 |
5.20e-07 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 53.92 E-value: 5.20e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 573 LKLEVEEKKQAMLLLQ-RALAQQRDLTARRVKETEKALSrQLQRQREHYEATIQRHLAFIDQL----------------- 634
Cdd:TIGR02169 216 LLKEKREYEGYELLKEkEALERQKEAIERQLASLEEELE-KLTEEISELEKRLEEIEQLLEELnkkikdlgeeeqlrvke 294
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 635 -IEDKKVLSEKCEAVVAELKQEDQRCTERVAQAQAQ---HELEIKKLKELMsATEKARREKWISEKTKKIKEVTVrgLEP 710
Cdd:TIGR02169 295 kIGELEAEIASLERSIAEKERELEDAEERLAKLEAEidkLLAEIEELEREI-EEERKRRDKLTEEYAELKEELED--LRA 371
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 711 EIQKLIARHKQEVRRLKSLHEA-ELLQSDERASQRCLRQAEELREQLEREKEALgQQERERARQR---FQQHLEQEQWAL 786
Cdd:TIGR02169 372 ELEEVDKEFAETRDELKDYREKlEKLKREINELKRELDRLQEELQRLSEELADL-NAAIAGIEAKineLEEEKEDKALEI 450
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 787 QQQRQRLySEVAEERERLGQQAARQRAELEELRQQLEESSSALTRALRAEFEKGREEQERRHQMEL---------NTLKQ 857
Cdd:TIGR02169 451 KKQEWKL-EQLAADLSKYEQELYDLKEEYDRVEKELSKLQRELAEAEAQARASEERVRGGRAVEEVlkasiqgvhGTVAQ 529
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 858 QLELERQ---AWE-AGRTR------------KEEAWLLNREQELREE---IRKGRDKEIELVIHRLEA--DMALAKEESE 916
Cdd:TIGR02169 530 LGSVGERyatAIEvAAGNRlnnvvveddavaKEAIELLKRRKAGRATflpLNKMRDERRDLSILSEDGviGFAVDLVEFD 609
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 917 KAAESRI----------------KRLRDKY-----EAELSE---------------------LEQSERKLQERCSELKGQ 954
Cdd:TIGR02169 610 PKYEPAFkyvfgdtlvvedieaaRRLMGKYrmvtlEGELFEksgamtggsraprggilfsrsEPAELQRLRERLEGLKRE 689
|
490 500 510 520 530 540 550 560
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 955 LGEAEGENLRLQGLVRQKERALEDAQAVNEQLSSERSNLAQVIRQEFEdRLAASEEETRQAKAELATLQARQQlELEEVH 1034
Cdd:TIGR02169 690 LSSLQSELRRIENRLDELSQELSDASRKIGEIEKEIEQLEQEEEKLKE-RLEELEEDLSSLEQEIENVKSELK-ELEARI 767
|
570 580 590 600
....*....|....*....|....*....|....*....|..
gi 111955084 1035 RRVKTALARKEEAVSSL--RTQHEAAVKRADHLEELLEQHRR 1074
Cdd:TIGR02169 768 EELEEDLHKLEEALNDLeaRLSHSRIPEIQAELSKLEEEVSR 809
|
|
| PRK02224 |
PRK02224 |
DNA double-strand break repair Rad50 ATPase; |
796-1071 |
5.26e-07 |
|
DNA double-strand break repair Rad50 ATPase;
Pssm-ID: 179385 [Multi-domain] Cd Length: 880 Bit Score: 53.89 E-value: 5.26e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 796 EVAEERErlgQQAARQRAELEELRQQLEESSSALTRALRA-EFEKGREEQERRHQmelnTLKQQLELERQAWEAGRTRKE 874
Cdd:PRK02224 468 ETIEEDR---ERVEELEAELEDLEEEVEEVEERLERAEDLvEAEDRIERLEERRE----DLEELIAERRETIEEKRERAE 540
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 875 EawLLNREQELREEIRKGRDKEIELVIHRLEADMALAKEESEKAA-ESRIKRLrDKYEAELSELEQSERKLQERCSELKG 953
Cdd:PRK02224 541 E--LRERAAELEAEAEEKREAAAEAEEEAEEAREEVAELNSKLAElKERIESL-ERIRTLLAAIADAEDEIERLREKREA 617
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 954 QlgeAEGENLRLQGLVRQKERALEDAQAVNEqlssERSNLAQVIRQEFEDRLAASEEETRQAKAELATLQARQQLeleev 1033
Cdd:PRK02224 618 L---AELNDERRERLAEKRERKRELEAEFDE----ARIEEAREDKERAEEYLEQVEEKLDELREERDDLQAEIGA----- 685
|
250 260 270
....*....|....*....|....*....|....*...
gi 111955084 1034 hrrVKTALARKEEavssLRTQHEAAVKRADHLEELLEQ 1071
Cdd:PRK02224 686 ---VENELEELEE----LRERREALENRVEALEALYDE 716
|
|
| COG4913 |
COG4913 |
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown]; |
804-1073 |
6.41e-07 |
|
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown];
Pssm-ID: 443941 [Multi-domain] Cd Length: 1089 Bit Score: 53.77 E-value: 6.41e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 804 LGQQAARQRAELEELRQQLEESSSALTRALRAefEKGREEQERRHQMELNTLKQQLELERQAWEAGRTrkeeawLLNREQ 883
Cdd:COG4913 604 LGFDNRAKLAALEAELAELEEELAEAEERLEA--LEAELDALQERREALQRLAEYSWDEIDVASAERE------IAELEA 675
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 884 ELrEEIRKGRD--KEIELVIHRLEADMALAKEESEkAAESRIKRLRDKYEAELSELEQSERKLqERCSELKGQLGEAEGE 961
Cdd:COG4913 676 EL-ERLDASSDdlAALEEQLEELEAELEELEEELD-ELKGEIGRLEKELEQAEEELDELQDRL-EAAEDLARLELRALLE 752
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 962 NLRLQGLVRQKERAL-EDAQAVNEQLSSERSNLAQVIRQEFED----------RLAASEEETRQAKAELATLQARqqlEL 1030
Cdd:COG4913 753 ERFAAALGDAVERELrENLEERIDALRARLNRAEEELERAMRAfnrewpaetaDLDADLESLPEYLALLDRLEED---GL 829
|
250 260 270 280
....*....|....*....|....*....|....*....|....*...
gi 111955084 1031 EEVHRRVKTALARKEEA-----VSSLRTQHEAAVKRADHLEELLEQHR 1073
Cdd:COG4913 830 PEYEERFKELLNENSIEfvadlLSKLRRAIREIKERIDPLNDSLKRIP 877
|
|
| PRK03918 |
PRK03918 |
DNA double-strand break repair ATPase Rad50; |
600-1074 |
8.32e-07 |
|
DNA double-strand break repair ATPase Rad50;
Pssm-ID: 235175 [Multi-domain] Cd Length: 880 Bit Score: 53.14 E-value: 8.32e-07
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 600 RRVKETEKALSR--QLQRQREHYEATIQRHLAFIDQLIEDKKVLSEKCEAVVAELKQEDQRcTERVAQAQAQHEL---EI 674
Cdd:PRK03918 176 RRIERLEKFIKRteNIEELIKEKEKELEEVLREINEISSELPELREELEKLEKEVKELEEL-KEEIEELEKELESlegSK 254
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 675 KKLKELMSATEKARRE--KWISEKTKKIKEVT-VRGLEPEIQKLIARHKQEVRRLKSLH-EAELLQSDERASQRCLRQAE 750
Cdd:PRK03918 255 RKLEEKIRELEERIEElkKEIEELEEKVKELKeLKEKAEEYIKLSEFYEEYLDELREIEkRLSRLEEEINGIEERIKELE 334
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 751 ELREQLEREKEALGQQERERARQRFQQHLEQEQWALQQQRQRLYS----------------------EVAEERERLGQQA 808
Cdd:PRK03918 335 EKEERLEELKKKLKELEKRLEELEERHELYEEAKAKKEELERLKKrltgltpeklekeleelekakeEIEEEISKITARI 414
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 809 ARQRAELEELRQQLEESSSALTRAL---RAEFEKGREEQERRHQMELNTLKQQL-ELERQAWEAGRTRKEEAWLLNREQE 884
Cdd:PRK03918 415 GELKKEIKELKKAIEELKKAKGKCPvcgRELTEEHRKELLEEYTAELKRIEKELkEIEEKERKLRKELRELEKVLKKESE 494
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 885 LR------EEIRKGRDKEIELVIHRLEADMALAKEESEKAA--ESRIKRLRDK------YEAELSELEQSERKLQERCSE 950
Cdd:PRK03918 495 LIklkelaEQLKELEEKLKKYNLEELEKKAEEYEKLKEKLIklKGEIKSLKKElekleeLKKKLAELEKKLDELEEELAE 574
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 951 LKGQLGE------------------AEGENLRLQGLVRQKERALEDAQAVNEQLSSERSNLAQV-------------IRQ 999
Cdd:PRK03918 575 LLKELEElgfesveeleerlkelepFYNEYLELKDAEKELEREEKELKKLEEELDKAFEELAETekrleelrkeleeLEK 654
|
490 500 510 520 530 540 550 560
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 1000 EF-EDRLAASEEETRQAKAELATLQARqqleLEEVHRRVKTA------LARKEEAVSSLRTQHEAAVKRADHLEELLEQH 1072
Cdd:PRK03918 655 KYsEEEYEELREEYLELSRELAGLRAE----LEELEKRREEIkktlekLKEELEEREKAKKELEKLEKALERVEELREKV 730
|
..
gi 111955084 1073 RR 1074
Cdd:PRK03918 731 KK 732
|
|
| DUF3584 |
pfam12128 |
Protein of unknown function (DUF3584); This protein is found in bacteria and eukaryotes. ... |
767-1029 |
2.08e-06 |
|
Protein of unknown function (DUF3584); This protein is found in bacteria and eukaryotes. Proteins in this family are typically between 943 to 1234 amino acids in length. This family contains a P-loop motif suggesting it is a nucleotide binding protein. It may be involved in replication.
Pssm-ID: 432349 [Multi-domain] Cd Length: 1191 Bit Score: 52.15 E-value: 2.08e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 767 ERERARQRFQQHLEQEQWALQQQRQRLYSEVAEERERLGQQAARQRAELEELRQQLEESSSALTRALRAEFEKGREEQER 846
Cdd:pfam12128 269 SDETLIASRQEERQETSAELNQLLRTLDDQWKEKRDELNGELSAADAAVAKDRSELEALEDQHGAFLDADIETAAADQEQ 348
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 847 --RHQMELNTLKQQLELERQAwEAGRTRKEEAWLLNREQELR---EEIRKGRDKEIElvihrleaDMALAKEESEKAAES 921
Cdd:pfam12128 349 lpSWQSELENLEERLKALTGK-HQDVTAKYNRRRSKIKEQNNrdiAGIKDKLAKIRE--------ARDRQLAVAEDDLQA 419
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 922 RIKRLRDKYEAELSELEQSERKLQERCSELKGQLGEAEGENLRLQGLvRQKERALEDAQAVNEQLSSERSNLAQVIRQEF 1001
Cdd:pfam12128 420 LESELREQLEAGKLEFNEEEYRLKSRLGELKLRLNQATATPELLLQL-ENFDERIERAREEQEAANAEVERLQSELRQAR 498
|
250 260
....*....|....*....|....*...
gi 111955084 1002 EDRLAASEeetRQAKAELATLQARQQLE 1029
Cdd:pfam12128 499 KRRDQASE---ALRQASRRLEERQSALD 523
|
|
| Myosin_tail_1 |
pfam01576 |
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and ... |
571-1061 |
2.96e-06 |
|
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and four light chains it is a fundamental contractile protein found in all eukaryote cell types. This family consists of the coiled-coil myosin heavy chain tail region. The coiled-coil is composed of the tail from two molecules of myosin. These can then assemble into the macromolecular thick filament. The coiled-coil region provides the structural backbone the thick filament.
Pssm-ID: 460256 [Multi-domain] Cd Length: 1081 Bit Score: 51.71 E-value: 2.96e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 571 MRLKLEVEEKKQAMLLLQRALAQQRDLTARRVKETEKALSRQLQRQREHYEATIQRHLAFI-------DQLIEDKKVLSE 643
Cdd:pfam01576 80 LESRLEEEEERSQQLQNEKKKMQQHIQDLEEQLDEEEAARQKLQLEKVTTEAKIKKLEEDIllledqnSKLSKERKLLEE 159
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 644 KCEAVVAELKQEDQRcTERVAQAQAQHELEIKKLKELMSATEKARREkwiSEKTKKIKEvtvrGLEPEIQKLIARHKQEV 723
Cdd:pfam01576 160 RISEFTSNLAEEEEK-AKSLSKLKNKHEAMISDLEERLKKEEKGRQE---LEKAKRKLE----GESTDLQEQIAELQAQI 231
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 724 RRLKslheAELLQSDERasqrcLRQAEELREQLEREKEALGQQERErarqrFQQHLEQEQWALQQQRQrlYSEVAEERER 803
Cdd:pfam01576 232 AELR----AQLAKKEEE-----LQAALARLEEETAQKNNALKKIRE-----LEAQISELQEDLESERA--ARNKAEKQRR 295
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 804 -LGQQAARQRAELE----------ELRQQLEESSSALTRALRAE---FEKGREEQERRHQMELNTLKQQLELERQAweAG 869
Cdd:pfam01576 296 dLGEELEALKTELEdtldttaaqqELRSKREQEVTELKKALEEEtrsHEAQLQEMRQKHTQALEELTEQLEQAKRN--KA 373
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 870 RTRKEEAWLLNREQELREEIRKgrdkeielvihrleadMALAKEESE---KAAESRIKRLRDKY-EAELSELEQSER--K 943
Cdd:pfam01576 374 NLEKAKQALESENAELQAELRT----------------LQQAKQDSEhkrKKLEGQLQELQARLsESERQRAELAEKlsK 437
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 944 LQERCSELKGQLGEAEGENLRLQGLVRQKERALEDAQAVNEQLSSERSNLAQVIRQEFEDR------LAASEEETRQAKA 1017
Cdd:pfam01576 438 LQSELESVSSLLNEAEGKNIKLSKDVSSLESQLQDTQELLQEETRQKLNLSTRLRQLEDERnslqeqLEEEEEAKRNVER 517
|
490 500 510 520
....*....|....*....|....*....|....*....|....
gi 111955084 1018 ELATLQArQQLELEEVHRRVKTALARKEEAVSSLRTQHEAAVKR 1061
Cdd:pfam01576 518 QLSTLQA-QLSDMKKKLEEDAGTLEALEEGKKRLQRELEALTQQ 560
|
|
| EnvC |
COG4942 |
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, ... |
864-1074 |
3.21e-06 |
|
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 443969 [Multi-domain] Cd Length: 377 Bit Score: 50.53 E-value: 3.21e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 864 QAWEAGRTRKEEAWLLNREQELREEIRKGRDKEIELV--IHRLEADMALAKEEsEKAAESRIKRLRDKYEAELSELEQSE 941
Cdd:COG4942 18 QADAAAEAEAELEQLQQEIAELEKELAALKKEEKALLkqLAALERRIAALARR-IRALEQELAALEAELAELEKEIAELR 96
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 942 RKLQERCSELKGQLGEAE--GENLRLQGLVRQKE-RALEDAQAVNEQLSSERSNLAQVIRQEFEdRLAASEEETRQAKAE 1018
Cdd:COG4942 97 AELEAQKEELAELLRALYrlGRQPPLALLLSPEDfLDAVRRLQYLKYLAPARREQAEELRADLA-ELAALRAELEAERAE 175
|
170 180 190 200 210
....*....|....*....|....*....|....*....|....*....|....*....
gi 111955084 1019 LATL---QARQQLELEEVHRRVKTALARKEEAVSSLRTQHEAAVKRADHLEELLEQHRR 1074
Cdd:COG4942 176 LEALlaeLEEERAALEALKAERQKLLARLEKELAELAAELAELQQEAEELEALIARLEA 234
|
|
| CCDC158 |
pfam15921 |
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. ... |
601-1039 |
3.85e-06 |
|
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. The function is not known.
Pssm-ID: 464943 [Multi-domain] Cd Length: 1112 Bit Score: 51.27 E-value: 3.85e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 601 RVKETEKALSRQLQRQREHYEATIQRHLAFIDQLIEDKKV----LSEKCEAVVAELKQEDQRCTERVAQAQAQHELEIKK 676
Cdd:pfam15921 239 RIFPVEDQLEALKSESQNKIELLLQQHQDRIEQLISEHEVeitgLTEKASSARSQANSIQSQLEIIQEQARNQNSMYMRQ 318
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 677 LKELMSATEKARREKWISEKT--KKIKEVTVR-----------------------GLEPEIQKLIAR-HKQEVR-RLKSL 729
Cdd:pfam15921 319 LSDLESTVSQLRSELREAKRMyeDKIEELEKQlvlanseltearterdqfsqesgNLDDQLQKLLADlHKREKElSLEKE 398
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 730 HEAELLQSDERASQRC--LRQAEELREQLEREKEALGQQERERArqrfQQHLEQEQWALQQQRQRLySEVAEERERLGQQ 807
Cdd:pfam15921 399 QNKRLWDRDTGNSITIdhLRRELDDRNMEVQRLEALLKAMKSEC----QGQMERQMAAIQGKNESL-EKVSSLTAQLEST 473
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 808 AARQRAELEEL--RQQLEESSSALTRALRAEFEKgREEQERRHQMELNTLKQQLELERQAWEAGRTRKEEAWLLNREQEL 885
Cdd:pfam15921 474 KEMLRKVVEELtaKKMTLESSERTVSDLTASLQE-KERAIEATNAEITKLRSRVDLKLQELQHLKNEGDHLRNVQTECEA 552
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 886 REEIRKGRDKEIELVIHRLEADMALAKEESEKAAESRIKRLRDKYE-----AELSELEQSERKLQERCSELKGQLGEAEG 960
Cdd:pfam15921 553 LKLQMAEKDKVIEILRQQIENMTQLVGQHGRTAGAMQVEKAQLEKEindrrLELQEFKILKDKKDAKIRELEARVSDLEL 632
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 961 ENLRLQGLVRQKERALEDAQAVNEQLSSE----RSNLA------QVIRQEFEDRLAASEEETRQAKAELATLQArqqlEL 1030
Cdd:pfam15921 633 EKVKLVNAGSERLRAVKDIKQERDQLLNEvktsRNELNslsedyEVLKRNFRNKSEEMETTTNKLKMQLKSAQS----EL 708
|
....*....
gi 111955084 1031 EEVHRRVKT 1039
Cdd:pfam15921 709 EQTRNTLKS 717
|
|
| sbcc |
TIGR00618 |
exonuclease SbcC; All proteins in this family for which functions are known are part of an ... |
573-1032 |
5.38e-06 |
|
exonuclease SbcC; All proteins in this family for which functions are known are part of an exonuclease complex with sbcD homologs. This complex is involved in the initiation of recombination to regulate the levels of palindromic sequences in DNA. This family is based on the phylogenomic analysis of JA Eisen (1999, Ph.D. Thesis, Stanford University). [DNA metabolism, DNA replication, recombination, and repair]
Pssm-ID: 129705 [Multi-domain] Cd Length: 1042 Bit Score: 50.74 E-value: 5.38e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 573 LKLEVEEKKQAMLLLQRALAQQRDLTARRvkeTEKALSRQLQRQREHYEATIQRHLAFIDQLIEDKKVLSEKCEAVVAE- 651
Cdd:TIGR00618 403 DILQREQATIDTRTSAFRDLQGQLAHAKK---QQELQQRYAELCAAAITCTAQCEKLEKIHLQESAQSLKEREQQLQTKe 479
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 652 --LKQEDQRCTERVAQAQAQHELEiKKLKELMSATEKARREKWISEKTKKI---KEVTVRGLEPEIQKLIARHKQEVRRL 726
Cdd:TIGR00618 480 qiHLQETRKKAVVLARLLELQEEP-CPLCGSCIHPNPARQDIDNPGPLTRRmqrGEQTYAQLETSEEDVYHQLTSERKQR 558
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 727 KSLHEAELLQSDERASQRCLRQAEELREQLEREKEALGQ-----QERERARQRFQQHLEQEQWALQQQRQRLYSEVAEER 801
Cdd:TIGR00618 559 ASLKEQMQEIQQSFSILTQCDNRSKEDIPNLQNITVRLQdltekLSEAEDMLACEQHALLRKLQPEQDLQDVRLHLQQCS 638
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 802 ERLGQQAARQRAELEELRQQLEESSSALTRALRAEFEKGREEQERRHQMELNTLKQQLELERQAWEAGR---TRKEEAWL 878
Cdd:TIGR00618 639 QELALKLTALHALQLTLTQERVREHALSIRVLPKELLASRQLALQKMQSEKEQLTYWKEMLAQCQTLLReleTHIEEYDR 718
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 879 LNREQELREEIRK----GRDKEIELVIHRLEADMALAKEESEKAAESRIKRL--RDKYEAELSELEQSERKLQERCSELK 952
Cdd:TIGR00618 719 EFNEIENASSSLGsdlaAREDALNQSLKELMHQARTVLKARTEAHFNNNEEVtaALQTGAELSHLAAEIQFFNRLREEDT 798
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 953 GQLGEAEGENLR-----LQGLVRQKERALEDAQAVNEQLSSERSNLAQVIRQEFEDrlaaseEETRQAKAELATLQARQQ 1027
Cdd:TIGR00618 799 HLLKTLEAEIGQeipsdEDILNLQCETLVQEEEQFLSRLEEKSATLGEITHQLLKY------EECSKQLAQLTQEQAKII 872
|
....*
gi 111955084 1028 LELEE 1032
Cdd:TIGR00618 873 QLSDK 877
|
|
| 46 |
PHA02562 |
endonuclease subunit; Provisional |
766-952 |
5.87e-06 |
|
endonuclease subunit; Provisional
Pssm-ID: 222878 [Multi-domain] Cd Length: 562 Bit Score: 50.40 E-value: 5.87e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 766 QERERARQRFQQHLEQEQWALQQQRQRLYSEVAEERERLGQQAARQRAELEELRQQLEESSSALT--RALRAEFEKGREE 843
Cdd:PHA02562 194 QQQIKTYNKNIEEQRKKNGENIARKQNKYDELVEEAKTIKAEIEELTDELLNLVMDIEDPSAALNklNTAAAKIKSKIEQ 273
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 844 QERRHQM-----ELNTLKQQLELERQAWEAGRTRKEEAWL-LNREQELREEIRKGRDK--EIELVIHRLEADMALAK--- 912
Cdd:PHA02562 274 FQKVIKMyekggVCPTCTQQISEGPDRITKIKDKLKELQHsLEKLDTAIDELEEIMDEfnEQSKKLLELKNKISTNKqsl 353
|
170 180 190 200
....*....|....*....|....*....|....*....|....*.
gi 111955084 913 ---EESEKAAESRIKRLRDK---YEAELSELEQSERKLQERCSELK 952
Cdd:PHA02562 354 itlVDKAKKVKAAIEELQAEfvdNAEELAKLQDELDKIVKTKSELV 399
|
|
| CCDC158 |
pfam15921 |
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. ... |
761-1074 |
6.90e-06 |
|
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. The function is not known.
Pssm-ID: 464943 [Multi-domain] Cd Length: 1112 Bit Score: 50.50 E-value: 6.90e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 761 EALGQQERERARQRFQQHlEQEQWALQQQRQRLYSE---VAEERERLGQQAARQRAELEELRQQLEESSSALTRALRaef 837
Cdd:pfam15921 259 ELLLQQHQDRIEQLISEH-EVEITGLTEKASSARSQansIQSQLEIIQEQARNQNSMYMRQLSDLESTVSQLRSELR--- 334
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 838 ekgreEQERRHQMELNTLKQQLELERQAWEAGRTRKEEawLLNREQELREEIRKgrdkeIELVIHRLEADMALAKEESek 917
Cdd:pfam15921 335 -----EAKRMYEDKIEELEKQLVLANSELTEARTERDQ--FSQESGNLDDQLQK-----LLADLHKREKELSLEKEQN-- 400
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 918 aaesriKRLRDKYEAELSELEQSERKLQERCSE-------LKGQLGEAEGENLRLQGLVRQKERALEDAQAVNEQLSSER 990
Cdd:pfam15921 401 ------KRLWDRDTGNSITIDHLRRELDDRNMEvqrlealLKAMKSECQGQMERQMAAIQGKNESLEKVSSLTAQLESTK 474
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 991 SNLAQVIRQ--------EFEDR----LAASEEETRQA----KAELATLQARQQLELEEV--------HRR--------VK 1038
Cdd:pfam15921 475 EMLRKVVEEltakkmtlESSERtvsdLTASLQEKERAieatNAEITKLRSRVDLKLQELqhlknegdHLRnvqteceaLK 554
|
330 340 350
....*....|....*....|....*....|....*.
gi 111955084 1039 TALARKEEAVSSLRTQHEaavkradHLEELLEQHRR 1074
Cdd:pfam15921 555 LQMAEKDKVIEILRQQIE-------NMTQLVGQHGR 583
|
|
| sbcc |
TIGR00618 |
exonuclease SbcC; All proteins in this family for which functions are known are part of an ... |
573-1033 |
7.36e-06 |
|
exonuclease SbcC; All proteins in this family for which functions are known are part of an exonuclease complex with sbcD homologs. This complex is involved in the initiation of recombination to regulate the levels of palindromic sequences in DNA. This family is based on the phylogenomic analysis of JA Eisen (1999, Ph.D. Thesis, Stanford University). [DNA metabolism, DNA replication, recombination, and repair]
Pssm-ID: 129705 [Multi-domain] Cd Length: 1042 Bit Score: 50.35 E-value: 7.36e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 573 LKLEVEEKKQamLLLQRALAQQRDLTARRVKETEKALSRQLQRQREHYEATIQRHLAFIDQLIEDKKVLSEKCEAVVAEL 652
Cdd:TIGR00618 158 LKAKSKEKKE--LLMNLFPLDQYTQLALMEFAKKKSLHGKAELLTLRSQLLTLCTPCMPDTYHERKQVLEKELKHLREAL 235
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 653 KQEDQrctervAQAQAQHELEikklkelmSATEKARREKWISEKTKKIKEVtvRGLEPEIQKLIARHKQEVRRLKSLHEA 732
Cdd:TIGR00618 236 QQTQQ------SHAYLTQKRE--------AQEEQLKKQQLLKQLRARIEEL--RAQEAVLEETQERINRARKAAPLAAHI 299
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 733 ELLQSDERASQRCLRQaeelreqlerekeaLGQQERERARQRFQQHLEQEQWALQQQRQRLYSEVAEERERLGQQAARQR 812
Cdd:TIGR00618 300 KAVTQIEQQAQRIHTE--------------LQSKMRSRAKLLMKRAAHVKQQSSIEEQRRLLQTLHSQEIHIRDAHEVAT 365
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 813 AELEELRQQLEESS---------SALTRALRAEFEKGREEQERRHQMELNTLKQQLELERQAWEAGRTRKEEAWLLNREQ 883
Cdd:TIGR00618 366 SIREISCQQHTLTQhihtlqqqkTTLTQKLQSLCKELDILQREQATIDTRTSAFRDLQGQLAHAKKQQELQQRYAELCAA 445
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 884 ELREEIRKGRDKEIELVIHRLEADMALAKEESEKAAESRIKRLRDKYEAELSELEQSERKLQERCSELKG---QLGEAEG 960
Cdd:TIGR00618 446 AITCTAQCEKLEKIHLQESAQSLKEREQQLQTKEQIHLQETRKKAVVLARLLELQEEPCPLCGSCIHPNParqDIDNPGP 525
|
410 420 430 440 450 460 470
....*....|....*....|....*....|....*....|....*....|....*....|....*....|...
gi 111955084 961 ENLRLQGLVRQKERALEDAQAVNEQLSSERSNLAqvirqefedRLAASEEETRQAKAELATLQARQQLELEEV 1033
Cdd:TIGR00618 526 LTRRMQRGEQTYAQLETSEEDVYHQLTSERKQRA---------SLKEQMQEIQQSFSILTQCDNRSKEDIPNL 589
|
|
| SMC_N |
pfam02463 |
RecF/RecN/SMC N terminal domain; This domain is found at the N terminus of SMC proteins. The ... |
565-947 |
9.45e-06 |
|
RecF/RecN/SMC N terminal domain; This domain is found at the N terminus of SMC proteins. The SMC (structural maintenance of chromosomes) superfamily proteins have ATP-binding domains at the N- and C-termini, and two extended coiled-coil domains separated by a hinge in the middle. The eukaryotic SMC proteins form two kind of heterodimers: the SMC1/SMC3 and the SMC2/SMC4 types. These heterodimers constitute an essential part of higher order complexes, which are involved in chromatin and DNA dynamics. This family also includes the RecF and RecN proteins that are involved in DNA metabolism and recombination.
Pssm-ID: 426784 [Multi-domain] Cd Length: 1161 Bit Score: 49.97 E-value: 9.45e-06
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 565 EVSTSVMRLKLEVEEKKQAMLLLQRALAQQRDLTARRVKETEKALSRQLQRQREHYEATIQRHLAFIDQLIEDKKVLSEK 644
Cdd:pfam02463 633 ELTKLKESAKAKESGLRKGVSLEEGLAEKSEVKASLSELTKELLEIQELQEKAESELAKEEILRRQLEIKKKEQREKEEL 712
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 645 CEAVVAELKQEDQRCTERVAQAQAQHELEIKKLKELMSATEKARREKWISEKTKKIKEVTVRGLEPEIQKLIARHKQEVR 724
Cdd:pfam02463 713 KKLKLEAEELLADRVQEAQDKINEELKLLKQKIDEEEEEEEKSRLKKEEKEEEKSELSLKEKELAEEREKTEKLKVEEEK 792
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 725 RLKSLHEAELLQSDERASQRclrQAEELREQLEREKEALGQQERERARQRFQQHLEQEQWALQQQRQRLYSEVAEERErl 804
Cdd:pfam02463 793 EEKLKAQEEELRALEEELKE---EAELLEEEQLLIEQEEKIKEEELEELALELKEEQKLEKLAEEELERLEEEITKEE-- 867
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 805 gqqaarQRAELEELRQQLEESssaltRALRAEFEKGREEQERRHQMELNTLKQQLELERQAWEAGRTRKEEAWLLNREQE 884
Cdd:pfam02463 868 ------LLQELLLKEEELEEQ-----KLKDELESKEEKEKEEKKELEEESQKLNLLEEKENEIEERIKEEAEILLKYEEE 936
|
330 340 350 360 370 380
....*....|....*....|....*....|....*....|....*....|....*....|....*...
gi 111955084 885 LREEIRKGRDKEIELVIHRLEAD-----MALAKEESEKAAESRIKRLRDKYEAELSELEQSERKLQER 947
Cdd:pfam02463 937 PEELLLEEADEKEKEENNKEEEEernkrLLLAKEELGKVNLMAIEEFEEKEERYNKDELEKERLEEEK 1004
|
|
| rad50 |
TIGR00606 |
rad50; All proteins in this family for which functions are known are involvedin recombination, ... |
649-1067 |
1.22e-05 |
|
rad50; All proteins in this family for which functions are known are involvedin recombination, recombinational repair, and/or non-homologous end joining.They are components of an exonuclease complex with MRE11 homologs. This family is distantly related to the SbcC family of bacterial proteins.This family is based on the phylogenomic analysis of JA Eisen (1999, Ph.D. Thesis, Stanford University).
Pssm-ID: 129694 [Multi-domain] Cd Length: 1311 Bit Score: 49.66 E-value: 1.22e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 649 VAELKQEDQRCT---ERVAQAQAQHELEIKKL--KELMSATEKARREKWISEKTKKIKEVTvrGLEPEIQKLIARHKQEV 723
Cdd:TIGR00606 669 ITQLTDENQSCCpvcQRVFQTEAELQEFISDLqsKLRLAPDKLKSTESELKKKEKRRDEML--GLAPGRQSIIDLKEKEI 746
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 724 RRLKslheaELLQSDERASQRclrqaeelreqlerEKEALGQQERERARQRFQQHLEQEQWALQQQRQRLYSEVAEERER 803
Cdd:TIGR00606 747 PELR-----NKLQKVNRDIQR--------------LKNDIEEQETLLGTIMPEEESAKVCLTDVTIMERFQMELKDVERK 807
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 804 LGQQAARQRA-----ELEELRQQLEESSSALTRA-----LRAEFEKGREEQERRHQMELNTLK-QQLELERQAWEAGRTR 872
Cdd:TIGR00606 808 IAQQAAKLQGsdldrTVQQVNQEKQEKQHELDTVvskieLNRKLIQDQQEQIQHLKSKTNELKsEKLQIGTNLQRRQQFE 887
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 873 KEEAWLLNREQELREEIRKGRDKEIELV-----IHRLEADMALAKEESEKAAESRIKRLRDKYEAELSELEQSERKLQER 947
Cdd:TIGR00606 888 EQLVELSTEVQSLIREIKDAKEQDSPLEtflekDQQEKEELISSKETSNKKAQDKVNDIKEKVKNIHGYMKDIENKIQDG 967
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 948 CSE-LKGQLGEAEGENLRLQGLVRQKERALED----AQAVNEQLSSERSNLAQVIRQEFEDRLAASEEETRQAKAELATL 1022
Cdd:TIGR00606 968 KDDyLKQKETELNTVNAQLEECEKHQEKINEDmrlmRQDIDTQKIQERWLQDNLTLRKRENELKEVEEELKQHLKEMGQM 1047
|
410 420 430 440
....*....|....*....|....*....|....*....|....*
gi 111955084 1023 QARQQleleevhrrvKTALARKEEAVSSLRTQHEAAVKRADHLEE 1067
Cdd:TIGR00606 1048 QVLQM----------KQEHQKLEENIDLIKRNHVLALGRQKGYEK 1082
|
|
| COG4913 |
COG4913 |
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown]; |
572-1074 |
1.34e-05 |
|
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown];
Pssm-ID: 443941 [Multi-domain] Cd Length: 1089 Bit Score: 49.53 E-value: 1.34e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 572 RLKLEVEEKKQAMLLLQRALAQQRDLTARRVKETEKALSRQLQRQRehyeatiqrhlafidqliedkkvlsEKCEAVVAE 651
Cdd:COG4913 266 AARERLAELEYLRAALRLWFAQRRLELLEAELEELRAELARLEAEL-------------------------ERLEARLDA 320
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 652 LKQEDQRCTERVAQAQAQHELEIKKLKELMSATEKARREKW--ISEKTKKIkEVTVRGLEPEIQKLIARHKQEVRRLKSL 729
Cdd:COG4913 321 LREELDELEAQIRGNGGDRLEQLEREIERLERELEERERRRarLEALLAAL-GLPLPASAEEFAALRAEAAALLEALEEE 399
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 730 HEAelLQSDERASQRCLRQAEELREQLEREKEALGQ------QERERARQRFQQHL------------------EQEQW- 784
Cdd:COG4913 400 LEA--LEEALAEAEAALRDLRRELRELEAEIASLERrksnipARLLALRDALAEALgldeaelpfvgelievrpEEERWr 477
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 785 -----ALQQQRQRL------YSEVAE--ERERLGQ------------QAARQRAELEELRQQLEESSSALTRALRAEFEK 839
Cdd:COG4913 478 gaierVLGGFALTLlvppehYAAALRwvNRLHLRGrlvyervrtglpDPERPRLDPDSLAGKLDFKPHPFRAWLEAELGR 557
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 840 GR-------EEQERRHQMELnTLKQQLELERQAWEAG-RTRKEEAWLL---NREQ--ELREEIRkgrdkEIELVIHRLEA 906
Cdd:COG4913 558 RFdyvcvdsPEELRRHPRAI-TRAGQVKGNGTRHEKDdRRRIRSRYVLgfdNRAKlaALEAELA-----ELEEELAEAEE 631
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 907 DMALAKEESEkaaesRIKRLRDKYE--AELSELEQSERKLQERCSELKGQLGEAEGENLRLQGLVRQKERALEDAQAVNE 984
Cdd:COG4913 632 RLEALEAELD-----ALQERREALQrlAEYSWDEIDVASAEREIAELEAELERLDASSDDLAALEEQLEELEAELEELEE 706
|
490 500 510 520 530 540 550 560
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 985 QLssersNLAQVIRQEFEDRLAASEEETRQAKAELATLQARQQLE----LEEVHRRVKTALARKeEAVSSLRTQHEAAVK 1060
Cdd:COG4913 707 EL-----DELKGEIGRLEKELEQAEEELDELQDRLEAAEDLARLElralLEERFAAALGDAVER-ELRENLEERIDALRA 780
|
570
....*....|....
gi 111955084 1061 RADHLEELLEQHRR 1074
Cdd:COG4913 781 RLNRAEEELERAMR 794
|
|
| YhaN |
COG4717 |
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; |
564-985 |
1.43e-05 |
|
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown];
Pssm-ID: 443752 [Multi-domain] Cd Length: 641 Bit Score: 49.00 E-value: 1.43e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 564 SEVSTSVMRLKLEVEEKKQAMLLLQRALAQQRDLtarrvkETEKALSRQLQRQREHYEAtIQRHLAFIDQLIEDKKVLSE 643
Cdd:COG4717 98 EELEEELEELEAELEELREELEKLEKLLQLLPLY------QELEALEAELAELPERLEE-LEERLEELRELEEELEELEA 170
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 644 KCEAVVAELKQEDQRCTERVAQAQAQHELEIKKLKELMSA--TEKARREKWISEKTKKIKEVTVRGLEPEIQKLIARHKQ 721
Cdd:COG4717 171 ELAELQEELEELLEQLSLATEEELQDLAEELEELQQRLAEleEELEEAQEELEELEEELEQLENELEAAALEERLKEARL 250
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 722 EVRRLKSLHEAELLQSDERASQR--------CLRQAEELREQLEREKEALGQQERERARQRFQQHLEQEQWAlqqqrqrl 793
Cdd:COG4717 251 LLLIAAALLALLGLGGSLLSLILtiagvlflVLGLLALLFLLLAREKASLGKEAEELQALPALEELEEEELE-------- 322
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 794 ysevaEERERLGQQAARQRAELEELRQQLEEsssaltraLRAEFEKGREEQERRHQMELNTLKQQLeLERQAWEAGRTRK 873
Cdd:COG4717 323 -----ELLAALGLPPDLSPEELLELLDRIEE--------LQELLREAEELEEELQLEELEQEIAAL-LAEAGVEDEEELR 388
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 874 EEAWLLNREQELREEIrkgrdkeiELVIHRLEADMALAKEESEKAAESRIKRLRDKYEAELSELEQSERKLQERCSELKG 953
Cdd:COG4717 389 AALEQAEEYQELKEEL--------EELEEQLEELLGELEELLEALDEEELEEELEELEEELEELEEELEELREELAELEA 460
|
410 420 430
....*....|....*....|....*....|..
gi 111955084 954 QLGEAEGENlRLQGLVRQKERALEDAQAVNEQ 985
Cdd:COG4717 461 ELEQLEEDG-ELAELLQELEELKAELRELAEE 491
|
|
| DR0291 |
COG1579 |
Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General ... |
791-957 |
1.51e-05 |
|
Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General function prediction only];
Pssm-ID: 441187 [Multi-domain] Cd Length: 236 Bit Score: 47.61 E-value: 1.51e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 791 QRLYSEVAEERERLGqqaaRQRAELEELRQQLEESSSALTrALRAEFEKGREEQeRRHQMELNTLKQQLELERQAWEAGR 870
Cdd:COG1579 13 QELDSELDRLEHRLK----ELPAELAELEDELAALEARLE-AAKTELEDLEKEI-KRLELEIEEVEARIKKYEEQLGNVR 86
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 871 TRKEEAWLLNREQELREEIRKGRDKEIELV--IHRLEADMALAKEEsEKAAESRIKRLRDKYEAELSELEQSERKLQERC 948
Cdd:COG1579 87 NNKEYEALQKEIESLKRRISDLEDEILELMerIEELEEELAELEAE-LAELEAELEEKKAELDEELAELEAELEELEAER 165
|
....*....
gi 111955084 949 SELKGQLGE 957
Cdd:COG1579 166 EELAAKIPP 174
|
|
| SMC_prok_A |
TIGR02169 |
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of ... |
575-951 |
3.33e-05 |
|
chromosome segregation protein SMC, primarily archaeal type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. It is found in a single copy and is homodimeric in prokaryotes, but six paralogs (excluded from this family) are found in eukarotes, where SMC proteins are heterodimeric. This family represents the SMC protein of archaea and a few bacteria (Aquifex, Synechocystis, etc); the SMC of other bacteria is described by TIGR02168. The N- and C-terminal domains of this protein are well conserved, but the central hinge region is skewed in composition and highly divergent. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274009 [Multi-domain] Cd Length: 1164 Bit Score: 48.14 E-value: 3.33e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 575 LEVEEKKQAMLLLQRALAQQRDLTARRVKETEKALS------RQLQRQREhyeaTIQRHLAFIDQLIEDKKVLSEKCEAV 648
Cdd:TIGR02169 677 QRLRERLEGLKRELSSLQSELRRIENRLDELSQELSdasrkiGEIEKEIE----QLEQEEEKLKERLEELEEDLSSLEQE 752
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 649 VAELKQEDQRCTERVaqaqAQHELEIKKLKELMSATEKARREKWISEKTKKIKEvtvrgLEPEIQKLIARHKQEVRRLKS 728
Cdd:TIGR02169 753 IENVKSELKELEARI----EELEEDLHKLEEALNDLEARLSHSRIPEIQAELSK-----LEEEVSRIEARLREIEQKLNR 823
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 729 LHEAELLQSDERASQRCLRQAEELREQLEREKEALGQQERErarqRFQQHLEQEQWALQQQRQRLySEVAEERERLgqqa 808
Cdd:TIGR02169 824 LTLEKEYLEKEIQELQEQRIDLKEQIKSIEKEIENLNGKKE----ELEEELEELEAALRDLESRL-GDLKKERDEL---- 894
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 809 arqRAELEELRQQLEESSSALtralraefekgreEQERRHQMELNTLKQQLELERQAWEAGRTRKEEAwllnREQELREE 888
Cdd:TIGR02169 895 ---EAQLRELERKIEELEAQI-------------EKKRKRLSELKAKLEALEEELSEIEDPKGEDEEI----PEEELSLE 954
|
330 340 350 360 370 380
....*....|....*....|....*....|....*....|....*....|....*....|...
gi 111955084 889 IRKGRDKEIELVIHRLEADMALAKEESEKAAESrikrlRDKYEAELSELEQSERKLQERCSEL 951
Cdd:TIGR02169 955 DVQAELQRVEEEIRALEPVNMLAIQEYEEVLKR-----LDELKEKRAKLEEERKAILERIEEY 1012
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
569-860 |
3.36e-05 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 48.13 E-value: 3.36e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 569 SVMRLKLEVEEKKQAMLLLQRALAQQRDLTARRVKETEKALSRQLQRQREHYEATIQRHLAFIDQLIEDKKVLSE---KC 645
Cdd:TIGR02168 729 SALRKDLARLEAEVEQLEERIAQLSKELTELEAEIEELEERLEEAEEELAEAEAEIEELEAQIEQLKEELKALREaldEL 808
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 646 EAVVAELKQEDQRCTERVAQAQAQHELEIKKLKELMSATEKARREkwISEKTKKIKEVTVRGLEPEIQ---KLIARHKQE 722
Cdd:TIGR02168 809 RAELTLLNEEAANLRERLESLERRIAATERRLEDLEEQIEELSED--IESLAAEIEELEELIEELESEleaLLNERASLE 886
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 723 VRRLKSLHEAELLQSDERASQRCLRQAeelreqlerekealgQQERERARQRFQQHLEQEQwALQQQRQRLYSEVAEERE 802
Cdd:TIGR02168 887 EALALLRSELEELSEELRELESKRSEL---------------RRELEELREKLAQLELRLE-GLEVRIDNLQERLSEEYS 950
|
250 260 270 280 290 300 310
....*....|....*....|....*....|....*....|....*....|....*....|....*....|...
gi 111955084 803 RLGQQAARQRAELEELRQQLEESSSALTRALRA----------EFEkgrEEQERR----HQME-LNTLKQQLE 860
Cdd:TIGR02168 951 LTLEEAEALENKIEDDEEEARRRLKRLENKIKElgpvnlaaieEYE---ELKERYdfltAQKEdLTEAKETLE 1020
|
|
| EnvC |
COG4942 |
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, ... |
663-891 |
3.66e-05 |
|
Septal ring factor EnvC, activator of murein hydrolases AmiA and AmiB [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 443969 [Multi-domain] Cd Length: 377 Bit Score: 47.45 E-value: 3.66e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 663 VAQAQAQHELEiKKLKELMSatEKARREKWISEKTKKIKEvtvrgLEPEIQKLIARHKQEVRRLKSLheaellQSDERAS 742
Cdd:COG4942 16 AAQADAAAEAE-AELEQLQQ--EIAELEKELAALKKEEKA-----LLKQLAALERRIAALARRIRAL------EQELAAL 81
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 743 QRCLRQAEELREQLEREKEALGQQ--ERERARQRFQQH------LEQEQWALQQQRQRLYSEVAEERERLGQQAARQRAE 814
Cdd:COG4942 82 EAELAELEKEIAELRAELEAQKEElaELLRALYRLGRQpplallLSPEDFLDAVRRLQYLKYLAPARREQAEELRADLAE 161
|
170 180 190 200 210 220 230
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*..
gi 111955084 815 LEELRQQLEESSSALTRALraefekgREEQERRHQMELNTLKQQLELERQAWEAGRTRKEEAWLLNREQELREEIRK 891
Cdd:COG4942 162 LAALRAELEAERAELEALL-------AELEEERAALEALKAERQKLLARLEKELAELAAELAELQQEAEELEALIAR 231
|
|
| Myosin_tail_1 |
pfam01576 |
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and ... |
806-1056 |
5.33e-05 |
|
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and four light chains it is a fundamental contractile protein found in all eukaryote cell types. This family consists of the coiled-coil myosin heavy chain tail region. The coiled-coil is composed of the tail from two molecules of myosin. These can then assemble into the macromolecular thick filament. The coiled-coil region provides the structural backbone the thick filament.
Pssm-ID: 460256 [Multi-domain] Cd Length: 1081 Bit Score: 47.48 E-value: 5.33e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 806 QQAARQRAELEELRQQLEESSSALTRALRAEFEKGREEQERRhqMELNTLKQQLELERQAWEAGRTRKEEawllnREQEL 885
Cdd:pfam01576 22 QKAESELKELEKKHQQLCEEKNALQEQLQAETELCAEAEEMR--ARLAARKQELEEILHELESRLEEEEE-----RSQQL 94
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 886 REEIRKGRDKEIELVIHRLEADMALAKEESEK-AAESRIKRLRDK---YEAELSELEQSERKLQERCSELKGQLGEAEGE 961
Cdd:pfam01576 95 QNEKKKMQQHIQDLEEQLDEEEAARQKLQLEKvTTEAKIKKLEEDillLEDQNSKLSKERKLLEERISEFTSNLAEEEEK 174
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 962 NLRLQGLVRQKERALEDAQavneqlssERSNLAQVIRQEFEDRLAASEEETRQAKAELATLQARqqleLEEvhrrVKTAL 1041
Cdd:pfam01576 175 AKSLSKLKNKHEAMISDLE--------ERLKKEEKGRQELEKAKRKLEGESTDLQEQIAELQAQ----IAE----LRAQL 238
|
250
....*....|....*
gi 111955084 1042 ARKEEAVSSLRTQHE 1056
Cdd:pfam01576 239 AKKEEELQAALARLE 253
|
|
| SMC_N |
pfam02463 |
RecF/RecN/SMC N terminal domain; This domain is found at the N terminus of SMC proteins. The ... |
816-1047 |
6.46e-05 |
|
RecF/RecN/SMC N terminal domain; This domain is found at the N terminus of SMC proteins. The SMC (structural maintenance of chromosomes) superfamily proteins have ATP-binding domains at the N- and C-termini, and two extended coiled-coil domains separated by a hinge in the middle. The eukaryotic SMC proteins form two kind of heterodimers: the SMC1/SMC3 and the SMC2/SMC4 types. These heterodimers constitute an essential part of higher order complexes, which are involved in chromatin and DNA dynamics. This family also includes the RecF and RecN proteins that are involved in DNA metabolism and recombination.
Pssm-ID: 426784 [Multi-domain] Cd Length: 1161 Bit Score: 47.27 E-value: 6.46e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 816 EELRQQLEESS--SALTRALRAEFEKGREEQERRHQMELNTLKQQLELERQAWEAgRTRKEEAWLLNREQELREEIRKGR 893
Cdd:pfam02463 152 PERRLEIEEEAagSRLKRKKKEALKKLIEETENLAELIIDLEELKLQELKLKEQA-KKALEYYQLKEKLELEEEYLLYLD 230
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 894 DKEIELVIHRLEADMALAKEESEKAAESRIKRLRDKYEAELSELEQSERKLQERCSELKGQLGEAEGENLRLQGLVRQKE 973
Cdd:pfam02463 231 YLKLNEERIDLLQELLRDEQEEIESSKQEIEKEEEKLAQVLKENKEEEKEKKLQEEELKLLAKEEEELKSELLKLERRKV 310
|
170 180 190 200 210 220 230
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....
gi 111955084 974 RALEDAQAVNEQLSSERSNLAQVIRQEFEDRLAASEEETRQAKAELATLQARQQLELEEVHRRVKTALARKEEA 1047
Cdd:pfam02463 311 DDEEKLKESEKEKKKAEKELKKEKEEIEELEKELKELEIKREAEEEEEEELEKLQEKLEQLEEELLAKKKLESE 384
|
|
| MukB |
COG3096 |
Chromosome condensin MukBEF, ATPase and DNA-binding subunit MukB [Cell cycle control, cell ... |
590-1027 |
7.19e-05 |
|
Chromosome condensin MukBEF, ATPase and DNA-binding subunit MukB [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 442330 [Multi-domain] Cd Length: 1470 Bit Score: 47.25 E-value: 7.19e-05
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 590 ALAQQRDLTARRVKETeKALSRQLQRQREHYEATIQRHLAFidqliedkkVLSEKCEAVVAELKQEDQRCTERVAQAQA- 668
Cdd:COG3096 789 ELRAERDELAEQYAKA-SFDVQKLQRLHQAFSQFVGGHLAV---------AFAPDPEAELAALRQRRSELERELAQHRAq 858
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 669 --QHELEIKKLKELMSAtekarrekwisektkkikevtVRGLEPEIQKLIARHKQEvrRLKSLHE-AELLQSDERASQRC 745
Cdd:COG3096 859 eqQLRQQLDQLKEQLQL---------------------LNKLLPQANLLADETLAD--RLEELREeLDAAQEAQAFIQQH 915
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 746 LRQAEELREQLEREKEALGQQERerarqrFQQHLEQEQWALQQQRQRLY--SEVAEERERLGQQAArqraeleelrQQLE 823
Cdd:COG3096 916 GKALAQLEPLVAVLQSDPEQFEQ------LQADYLQAKEQQRRLKQQIFalSEVVQRRPHFSYEDA----------VGLL 979
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 824 ESSSALTRALRAEFEKGrEEQERRHQMELNTLKQQLELERQAWEAGRTRKEeawllNREQELREEIRkgrdkeielvihR 903
Cdd:COG3096 980 GENSDLNEKLRARLEQA-EEARREAREQLRQAQAQYSQYNQVLASLKSSRD-----AKQQTLQELEQ------------E 1041
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 904 LEADMALAKEESEKAAESRikrlRDKYEAELSELEQserklqeRCSELKGQLGEAEGENLRLQGLVRQKERaleDAQAVN 983
Cdd:COG3096 1042 LEELGVQADAEAEERARIR----RDELHEELSQNRS-------RRSQLEKQLTRCEAEMDSLQKRLRKAER---DYKQER 1107
|
410 420 430 440
....*....|....*....|....*....|....*....|....
gi 111955084 984 EQLSSERSNLAQVIRqefedRLAASEEETRQAKAELATLQARQQ 1027
Cdd:COG3096 1108 EQVVQAKAGWCAVLR-----LARDNDVERRLHRRELAYLSADEL 1146
|
|
| PRK02224 |
PRK02224 |
DNA double-strand break repair Rad50 ATPase; |
792-1076 |
1.18e-04 |
|
DNA double-strand break repair Rad50 ATPase;
Pssm-ID: 179385 [Multi-domain] Cd Length: 880 Bit Score: 46.19 E-value: 1.18e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 792 RLYSEVAEERER-LGQQAARQRAELEELRQQLE--ESSSALTRALRAEFEKGREEQERRHQmELNTLKQQLELERQAWEA 868
Cdd:PRK02224 191 QLKAQIEEKEEKdLHERLNGLESELAELDEEIEryEEQREQARETRDEADEVLEEHEERRE-ELETLEAEIEDLRETIAE 269
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 869 GRTRKEEawllnreqeLREEIRKGRDKEIELvihRLEADMALAKEESEKAAESRIkrlrdkyEAELSELEQSERKLQERC 948
Cdd:PRK02224 270 TEREREE---------LAEEVRDLRERLEEL---EEERDDLLAEAGLDDADAEAV-------EARREELEDRDEELRDRL 330
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 949 SELKGQLGEAEGENLRLQGLVRQKERALEDAQAVNEQLSSERSNLAQVIRqEFEDRLAASEEETRQAKAELATLQARQQl 1028
Cdd:PRK02224 331 EECRVAAQAHNEEAESLREDADDLEERAEELREEAAELESELEEAREAVE-DRREEIEELEEEIEELRERFGDAPVDLG- 408
|
250 260 270 280
....*....|....*....|....*....|....*....|....*...
gi 111955084 1029 ELEEVHRRVKTALARKEEAVSSLRTQHEAAVKRADHLEELLEQHRRPT 1076
Cdd:PRK02224 409 NAEDFLEELREERDELREREAELEATLRTARERVEEAEALLEAGKCPE 456
|
|
| rad50 |
TIGR00606 |
rad50; All proteins in this family for which functions are known are involvedin recombination, ... |
570-1071 |
1.25e-04 |
|
rad50; All proteins in this family for which functions are known are involvedin recombination, recombinational repair, and/or non-homologous end joining.They are components of an exonuclease complex with MRE11 homologs. This family is distantly related to the SbcC family of bacterial proteins.This family is based on the phylogenomic analysis of JA Eisen (1999, Ph.D. Thesis, Stanford University).
Pssm-ID: 129694 [Multi-domain] Cd Length: 1311 Bit Score: 46.19 E-value: 1.25e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 570 VMRLKLEVEEKKQAMLLLQRALAQQRDLTARRVKETEKALSRQLQR-QREHYEATIQRHLAFIDQLIEDKKVLSEKCEAV 648
Cdd:TIGR00606 441 TIELKKEILEKKQEELKFVIKELQQLEGSSDRILELDQELRKAERElSKAEKNSLTETLKKEVKSLQNEKADLDRKLRKL 520
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 649 VAELKQEDQRCTER-----VAQAQAQHELEIKKLK-----ELMSAT----EKARREKWISEKTKKIK--EVTVRGLEPEI 712
Cdd:TIGR00606 521 DQEMEQLNHHTTTRtqmemLTKDKMDKDEQIRKIKsrhsdELTSLLgyfpNKKQLEDWLHSKSKEINqtRDRLAKLNKEL 600
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 713 QKLIARHKQEVRRLKSLHEAELLQSDErasqrclrqaeelreqlerEKEALGQQERERARQRFQQHLEQ--EQWALQQQR 790
Cdd:TIGR00606 601 ASLEQNKNHINNELESKEEQLSSYEDK-------------------LFDVCGSQDEESDLERLKEEIEKssKQRAMLAGA 661
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 791 QRLYSEVAEERER-------LGQQAARQRAELEELRQQLEESSSALTRALRAEFEKGREEQERRHQMELNTLKQQLELER 863
Cdd:TIGR00606 662 TAVYSQFITQLTDenqsccpVCQRVFQTEAELQEFISDLQSKLRLAPDKLKSTESELKKKEKRRDEMLGLAPGRQSIIDL 741
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 864 QAWEAGRTRKEEAWLLNREQELREEIRKgRDKEIELVIHRLEA------DMALAKEESEKAAESRIKRLRDKYEAELSEL 937
Cdd:TIGR00606 742 KEKEIPELRNKLQKVNRDIQRLKNDIEE-QETLLGTIMPEEESakvcltDVTIMERFQMELKDVERKIAQQAAKLQGSDL 820
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 938 EQSERKLQERCSELKGQLGEAEGENLRLQGLVRQKERALEDAQAVNEQLSSERSNLAQVI--RQEFEDRLAASEEETRQA 1015
Cdd:TIGR00606 821 DRTVQQVNQEKQEKQHELDTVVSKIELNRKLIQDQQEQIQHLKSKTNELKSEKLQIGTNLqrRQQFEEQLVELSTEVQSL 900
|
490 500 510 520 530
....*....|....*....|....*....|....*....|....*....|....*.
gi 111955084 1016 KAELAtlQARQQLELEEVHRrvKTALARKEEAVSSLRTQHEAAVKRADHLEELLEQ 1071
Cdd:TIGR00606 901 IREIK--DAKEQDSPLETFL--EKDQQEKEELISSKETSNKKAQDKVNDIKEKVKN 952
|
|
| GumC |
COG3206 |
Exopolysaccharide export protein/domain GumC/Wzc1 [Cell wall/membrane/envelope biogenesis]; |
852-1074 |
2.05e-04 |
|
Exopolysaccharide export protein/domain GumC/Wzc1 [Cell wall/membrane/envelope biogenesis];
Pssm-ID: 442439 [Multi-domain] Cd Length: 687 Bit Score: 45.39 E-value: 2.05e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 852 LNTLKQQLELERQAWEAGRTRKEEAWLLNREQELREEIRkgrDKEIELVIHRLEADMALAKEESeKAAESRIKRLrdkyE 931
Cdd:COG3206 154 ANALAEAYLEQNLELRREEARKALEFLEEQLPELRKELE---EAEAALEEFRQKNGLVDLSEEA-KLLLQQLSEL----E 225
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 932 AELSELEQSERKLQERCSELKGQLGEAEGENLRLQGlvrqkeraledaqavNEQLSSERSNLAQVIRQ--EFEDRLAASE 1009
Cdd:COG3206 226 SQLAEARAELAEAEARLAALRAQLGSGPDALPELLQ---------------SPVIQQLRAQLAELEAElaELSARYTPNH 290
|
170 180 190 200 210 220
....*....|....*....|....*....|....*....|....*....|....*....|....*
gi 111955084 1010 EETRQAKAELATLQARQQLELEEVHRRVKTALARKEEAVSSLRTQHEAAVKRADHLEELLEQHRR 1074
Cdd:COG3206 291 PDVIALRAQIAALRAQLQQEAQRILASLEAELEALQAREASLQAQLAQLEARLAELPELEAELRR 355
|
|
| ClpA |
COG0542 |
ATP-dependent Clp protease, ATP-binding subunit ClpA [Posttranslational modification, protein ... |
895-997 |
2.50e-04 |
|
ATP-dependent Clp protease, ATP-binding subunit ClpA [Posttranslational modification, protein turnover, chaperones];
Pssm-ID: 440308 [Multi-domain] Cd Length: 836 Bit Score: 45.07 E-value: 2.50e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 895 KEIELVIHRLEADMALAKEESEKAAESRIKRLRDKY---EAELSELE---QSERKLQERCSELKGQLGEAEGENLRLQGL 968
Cdd:COG0542 414 DELERRLEQLEIEKEALKKEQDEASFERLAELRDELaelEEELEALKarwEAEKELIEEIQELKEELEQRYGKIPELEKE 493
|
90 100 110
....*....|....*....|....*....|
gi 111955084 969 VRQKERALEDAQA-VNEQLSSErsNLAQVI 997
Cdd:COG0542 494 LAELEEELAELAPlLREEVTEE--DIAEVV 521
|
|
| YhaN |
COG4717 |
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; |
878-1074 |
2.61e-04 |
|
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown];
Pssm-ID: 443752 [Multi-domain] Cd Length: 641 Bit Score: 45.14 E-value: 2.61e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 878 LLNREQELREEIRKGRDKEIELVIHRLeadmalakeeseKAAESRIKRLRDKyEAELSELEQSERKLQERCSELKGQLGE 957
Cdd:COG4717 47 LLERLEKEADELFKPQGRKPELNLKEL------------KELEEELKEAEEK-EEEYAELQEELEELEEELEELEAELEE 113
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 958 AEGENLRLQGLVRQKErALEDAQAVNEQLSSERSNLAQVIRQEfeDRLAASEEETRQAKAELATLQARQQLELEEVHRRV 1037
Cdd:COG4717 114 LREELEKLEKLLQLLP-LYQELEALEAELAELPERLEELEERL--EELRELEEELEELEAELAELQEELEELLEQLSLAT 190
|
170 180 190
....*....|....*....|....*....|....*..
gi 111955084 1038 KTALARKEEAVSSLRTQHEAAVKRADHLEELLEQHRR 1074
Cdd:COG4717 191 EEELQDLAEELEELQQRLAELEEELEEAQEELEELEE 227
|
|
| COG5022 |
COG5022 |
Myosin heavy chain [General function prediction only]; |
722-1030 |
4.77e-04 |
|
Myosin heavy chain [General function prediction only];
Pssm-ID: 227355 [Multi-domain] Cd Length: 1463 Bit Score: 44.30 E-value: 4.77e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 722 EVRRLKSLHE-AELLQSDERAS--QRCLRQAEELREQLEREKEALgqqereRARQRFQQHL-------EQEQWALQQQRQ 791
Cdd:COG5022 737 EDMRDAKLDNiATRIQRAIRGRylRRRYLQALKRIKKIQVIQHGF------RLRRLVDYELkwrlfikLQPLLSLLGSRK 810
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 792 RLYSEVAE--------ERERLGQQAARQRAEL--EELRQQLEESSSALTRALR------AEFEKGREEQERRHQMEL--- 852
Cdd:COG5022 811 EYRSYLACiiklqktiKREKKLRETEEVEFSLkaEVLIQKFGRSLKAKKRFSLlkketiYLQSAQRVELAERQLQELkid 890
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 853 ----NTLKQQ-LELErqaWEAGRTRKEEAWLLNREQELREEirkgRDKEIELVIHRLEADMALAKEESEK-------AAE 920
Cdd:COG5022 891 vksiSSLKLVnLELE---SEIIELKKSLSSDLIENLEFKTE----LIARLKKLLNNIDLEEGPSIEYVKLpelnklhEVE 963
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 921 SRIKRLRDKYEAELSELEQSERKLQERCSELKG---QLGEAEGENLRLQ---GLVRQKERALEDAQAVNEQLSSERSNLA 994
Cdd:COG5022 964 SKLKETSEEYEDLLKKSTILVREGNKANSELKNfkkELAELSKQYGALQestKQLKELPVEVAELQSASKIISSESTELS 1043
|
330 340 350
....*....|....*....|....*....|....*.
gi 111955084 995 QviRQEFEDRLAASEEETRQAKAELATLQARQQLEL 1030
Cdd:COG5022 1044 I--LKPLQKLKGLLLLENNQLQARYKALKLRRENSL 1077
|
|
| mukB |
PRK04863 |
chromosome partition protein MukB; |
765-891 |
5.94e-04 |
|
chromosome partition protein MukB;
Pssm-ID: 235316 [Multi-domain] Cd Length: 1486 Bit Score: 44.18 E-value: 5.94e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 765 QQERERARQRFQQHLEQeQWALQQQRQRLYSEVAEERERLGQQAARQRAELEELRQQLEE-----------------SSS 827
Cdd:PRK04863 532 QQRAERLLAEFCKRLGK-NLDDEDELEQLQEELEARLESLSESVSEARERRMALRQQLEQlqariqrlaarapawlaAQD 610
|
90 100 110 120 130 140
....*....|....*....|....*....|....*....|....*....|....*....|....
gi 111955084 828 ALTRaLRAEFEkgrEEQERRHQMElNTLKQQLELERQAweagrtRKEEAWLLNREQELREEIRK 891
Cdd:PRK04863 611 ALAR-LREQSG---EEFEDSQDVT-EYMQQLLEREREL------TVERDELAARKQALDEEIER 663
|
|
| YqiK |
COG2268 |
Uncharacterized membrane protein YqiK, contains Band7/PHB/SPFH domain [Function unknown]; |
787-920 |
6.45e-04 |
|
Uncharacterized membrane protein YqiK, contains Band7/PHB/SPFH domain [Function unknown];
Pssm-ID: 441869 [Multi-domain] Cd Length: 439 Bit Score: 43.32 E-value: 6.45e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 787 QQQRQRLYSEVAEERERLGQQAARQRAELEELRQQLEESSSALTRALRAEFEKGREEQERRHQMELNTLKQQLELERQAW 866
Cdd:COG2268 218 QANREAEEAELEQEREIETARIAEAEAELAKKKAEERREAETARAEAEAAYEIAEANAEREVQRQLEIAEREREIELQEK 297
|
90 100 110 120 130
....*....|....*....|....*....|....*....|....*....|....
gi 111955084 867 EAGRtrkeeawllnREQELREEIRKGRDKEIELVIHRLEADMALAKEESEKAAE 920
Cdd:COG2268 298 EAER----------EEAELEADVRKPAEAEKQAAEAEAEAEAEAIRAKGLAEAE 341
|
|
| Mitofilin |
pfam09731 |
Mitochondrial inner membrane protein; Mitofilin controls mitochondrial cristae morphology. ... |
785-898 |
7.66e-04 |
|
Mitochondrial inner membrane protein; Mitofilin controls mitochondrial cristae morphology. Mitofilin is enriched in the narrow space between the inner boundary and the outer membranes, where it forms a homotypic interaction and assembles into a large multimeric protein complex. The first 78 amino acids contain a typical amino-terminal-cleavable mitochondrial presequence rich in positive-charged and hydroxylated residues and a membrane anchor domain. In addition, it has three centrally located coiled coil domains.
Pssm-ID: 430783 [Multi-domain] Cd Length: 618 Bit Score: 43.59 E-value: 7.66e-04
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 785 ALQQQRQRLYSEVAEERERLGQQAARQRAEL----EELRQQLEESSSALTRALRAEFEKGREEQERRHQMELNTlkqqlE 860
Cdd:pfam09731 295 EIDQLSKKLAELKKREEKHIERALEKQKEELdklaEELSARLEEVRAADEAQLRLEFEREREEIRESYEEKLRT-----E 369
|
90 100 110
....*....|....*....|....*....|....*...
gi 111955084 861 LERQAWEAGRTRKEEawLLNREQELREEIRKGRDKEIE 898
Cdd:pfam09731 370 LERQAEAHEEHLKDV--LVEQEIELQREFLQDIKEKVE 405
|
|
| DUF4670 |
pfam15709 |
Domain of unknown function (DUF4670); This family of proteins is found in eukaryotes. Proteins ... |
767-887 |
1.09e-03 |
|
Domain of unknown function (DUF4670); This family of proteins is found in eukaryotes. Proteins in this family are typically between 373 and 763 amino acids in length.
Pssm-ID: 464815 [Multi-domain] Cd Length: 522 Bit Score: 43.02 E-value: 1.09e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 767 ERERARQRFQQHLEQEQwalQQQRQRLYSEVAEERERLGQQAARQRAELEELRQQLEESSSALTRALRAEFEKGREEQE- 845
Cdd:pfam15709 351 ERKRREQEEQRRLQQEQ---LERAEKMREELELEQQRRFEEIRLRKQRLEEERQRQEEEERKQRLQLQAAQERARQQQEe 427
|
90 100 110 120
....*....|....*....|....*....|....*....|...
gi 111955084 846 -RRHQMELNTLKQQLELERQAWEAGRTRKEEAWLLNREQELRE 887
Cdd:pfam15709 428 fRRKLQELQRKKQQEEAERAEAEKQRQKELEMQLAEEQKRLME 470
|
|
| CALCOCO1 |
pfam07888 |
Calcium binding and coiled-coil domain (CALCOCO1) like; Proteins found in this family are ... |
815-1073 |
1.18e-03 |
|
Calcium binding and coiled-coil domain (CALCOCO1) like; Proteins found in this family are similar to the coiled-coil transcriptional coactivator protein coexpressed by Mus musculus (CoCoA/CALCOCO1). This protein binds to a highly conserved N-terminal domain of p160 coactivators, such as GRIP1, and thus enhances transcriptional activation by a number of nuclear receptors. CALCOCO1 has a central coiled-coil region with three leucine zipper motifs, which is required for its interaction with GRIP1 and may regulate the autonomous transcriptional activation activity of the C-terminal region.
Pssm-ID: 462303 [Multi-domain] Cd Length: 488 Bit Score: 42.57 E-value: 1.18e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 815 LEELRQQLEESSSALTRALRAEFEKGREEQERRHQMEL----NTLKQQLELERQAWEAGRTR--KEEAWLLNREQELREE 888
Cdd:pfam07888 9 LEEESHGEEGGTDMLLVVPRAELLQNRLEECLQERAELlqaqEAANRQREKEKERYKRDREQweRQRRELESRVAELKEE 88
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 889 IRKGRDKEIELVIHRLEADMALAKEESEKAAESRIkrlRDKYEAELSELEQSERKLQERCSELKGQLGEAEGENLRLQGL 968
Cdd:pfam07888 89 LRQSREKHEELEEKYKELSASSEELSEEKDALLAQ---RAAHEARIRELEEDIKTLTQRVLERETELERMKERAKKAGAQ 165
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 969 VRQKERALEDAQAVNEQLSSERSNLAQVIrQEFEDRLAASEEETRQAKAELATLQA------RQQLELEEVHRRVKTA-- 1040
Cdd:pfam07888 166 RKEEEAERKQLQAKLQQTEEELRSLSKEF-QELRNSLAQRDTQVLQLQDTITTLTQklttahRKEAENEALLEELRSLqe 244
|
250 260 270
....*....|....*....|....*....|....
gi 111955084 1041 -LARKEEAVSSLRTQHEAAVKRADHLEELLEQHR 1073
Cdd:pfam07888 245 rLNASERKVEGLGEELSSMAAQRDRTQAELHQAR 278
|
|
| Myosin_tail_1 |
pfam01576 |
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and ... |
765-1068 |
1.30e-03 |
|
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and four light chains it is a fundamental contractile protein found in all eukaryote cell types. This family consists of the coiled-coil myosin heavy chain tail region. The coiled-coil is composed of the tail from two molecules of myosin. These can then assemble into the macromolecular thick filament. The coiled-coil region provides the structural backbone the thick filament.
Pssm-ID: 460256 [Multi-domain] Cd Length: 1081 Bit Score: 42.85 E-value: 1.30e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 765 QQERERARQRFQQHLEQEqwalqqqrqrLYSEVAEERERLgqqaARQRAELEELRQQLE---ESSSALTRALRAEFEKGR 841
Cdd:pfam01576 37 QLCEEKNALQEQLQAETE----------LCAEAEEMRARL----AARKQELEEILHELEsrlEEEEERSQQLQNEKKKMQ 102
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 842 EE-QERRHQM-ELNTLKQQLELERQAWEAGRTRKEEAWLLNREQELREEirkgrdKEIELVIHRLEADMALAKEESEKAa 919
Cdd:pfam01576 103 QHiQDLEEQLdEEEAARQKLQLEKVTTEAKIKKLEEDILLLEDQNSKLS------KERKLLEERISEFTSNLAEEEEKA- 175
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 920 eSRIKRLRDKYEAELS--------------ELEQSERKLQERCSELKGQLGEAEGENLRLQGLVRQKERALEDAQAVNEQ 985
Cdd:pfam01576 176 -KSLSKLKNKHEAMISdleerlkkeekgrqELEKAKRKLEGESTDLQEQIAELQAQIAELRAQLAKKEEELQAALARLEE 254
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 986 LSSERSNLAQVIRqEFEDRLAASEEETRQAKAELATLQaRQQLELEEVHRRVKTALarkEEAVSSLRTQHEAAVKRADHL 1065
Cdd:pfam01576 255 ETAQKNNALKKIR-ELEAQISELQEDLESERAARNKAE-KQRRDLGEELEALKTEL---EDTLDTTAAQQELRSKREQEV 329
|
...
gi 111955084 1066 EEL 1068
Cdd:pfam01576 330 TEL 332
|
|
| MARTX_Nterm |
NF012221 |
MARTX multifunctional-autoprocessing repeats-in-toxin holotoxin N-terminal region; This model ... |
777-1014 |
1.60e-03 |
|
MARTX multifunctional-autoprocessing repeats-in-toxin holotoxin N-terminal region; This model describes the N-terminal 1900 amino acids of MARTX family multifunctional-autoprocessing repeats-in-toxin holotoxins, which contain both repeat regions that facilitate their entry into eukaryotic target cells, and multiple effector domains.
Pssm-ID: 467957 [Multi-domain] Cd Length: 1848 Bit Score: 42.90 E-value: 1.60e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 777 QHLEQEQWAlqqQRQRLYSEVAEE-RERLGQQAARQRAELEELRQQLEESS-SALTRALRAEFEKGREEQeRRHQMELNT 854
Cdd:NF012221 1549 KHAKQDDAA---QNALADKERAEAdRQRLEQEKQQQLAAISGSQSQLESTDqNALETNGQAQRDAILEES-RAVTKELTT 1624
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 855 LKQQLE-LERQAWEAGRTrkEEAW-------LLNREQELREEIRKGRDKEIELVIHRLEADMALAKEESEKaaesrikrl 926
Cdd:NF012221 1625 LAQGLDaLDSQATYAGES--GDQWrnpfaggLLDRVQEQLDDAKKISGKQLADAKQRHVDNQQKVKDAVAK--------- 1693
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 927 rdkyeaelSE--LEQSERKLQErcSELKGQLGEAEGENLRLQGLVRQKE---------RALEDAQAVNEQLSSERSNLAQ 995
Cdd:NF012221 1694 --------SEagVAQGEQNQAN--AEQDIDDAKADAEKRKDDALAKQNEaqqaesdanAAANDAQSRGEQDASAAENKAN 1763
|
250 260
....*....|....*....|
gi 111955084 996 VIRQEFED-RLAASEEETRQ 1014
Cdd:NF012221 1764 QAQADAKGaKQDESDKPNRQ 1783
|
|
| GumC |
COG3206 |
Exopolysaccharide export protein/domain GumC/Wzc1 [Cell wall/membrane/envelope biogenesis]; |
786-975 |
1.62e-03 |
|
Exopolysaccharide export protein/domain GumC/Wzc1 [Cell wall/membrane/envelope biogenesis];
Pssm-ID: 442439 [Multi-domain] Cd Length: 687 Bit Score: 42.31 E-value: 1.62e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 786 LQQQRQRLYSEVAEERERLGQQAARQRAELEELRQQLEE--------SSSALTRALRAEFEKGREEQERRhQMELNTLKQ 857
Cdd:COG3206 162 LEQNLELRREEARKALEFLEEQLPELRKELEEAEAALEEfrqknglvDLSEEAKLLLQQLSELESQLAEA-RAELAEAEA 240
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 858 QLELERQAWEAGRTRKEEAWLLNREQELREEIRKGRDKEIELVIHRLEA--DMALAKEE---SEKAAESRIKRLRDKYEA 932
Cdd:COG3206 241 RLAALRAQLGSGPDALPELLQSPVIQQLRAQLAELEAELAELSARYTPNhpDVIALRAQiaaLRAQLQQEAQRILASLEA 320
|
170 180 190 200
....*....|....*....|....*....|....*....|...
gi 111955084 933 ELSELEQSERKLQERCSELKGQLGEAEGENLRLQGLVRQKERA 975
Cdd:COG3206 321 ELEALQAREASLQAQLAQLEARLAELPELEAELRRLEREVEVA 363
|
|
| CHASE3 |
COG5278 |
Extracytoplasmic sensor domain CHASE3 (specificity unknown) [Signal transduction mechanisms]; |
711-1072 |
1.99e-03 |
|
Extracytoplasmic sensor domain CHASE3 (specificity unknown) [Signal transduction mechanisms];
Pssm-ID: 444089 [Multi-domain] Cd Length: 530 Bit Score: 42.20 E-value: 1.99e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 711 EIQKLIARHKQEVRRLKSLHEAELLQSDERASQRCLRQAEELREQLEREKEALGQQERERARQRFQQHLEQEQWALQQQR 790
Cdd:COG5278 94 ELRSLTADNPEQQARLDELEALIDQWLAELEQVIALRRAGGLEAALALVRSGEGKALMDEIRARLLLLALALAALLLAAA 173
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 791 QRLYSEVAEERERLGQQAARQRAELEELRQQLEESSSALTRALRAEFEKGREEQERRHQMELNTLKQQLELERQAWEAGR 870
Cdd:COG5278 174 ALLLLLLALAALLALAELLLLALARALAALLLLLLLEAELAAAAALLAAAAALAALAALELLAALALALALLLAALLLAL 253
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 871 TRKEEAWLLNREQELREEIRKGRDKEIELVIHRLEADMALAKEESEKAAESRIKRLRDKYEAELSELEQSERKLQERCSE 950
Cdd:COG5278 254 LAALALAALLAAALLALAALLLALAAAAALAAAAALELAAAEALALAELELELLLAAAAAAAAAAAAAAAALAALLALAL 333
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 951 LKGQLGEAEGENLRLQGLVRQKERALEDAQAVNEQLSSERSNLAQVIRQEFEDRLAASEEETRQAKAELATLQARQQLEL 1030
Cdd:COG5278 334 ATALAAAAAALALLAALLAEAAAAAAEEAEAAAEAAAAALAGLAEVEAEGAAEAVELEVLAIAAAAAAAAAEAAAAAAAA 413
|
330 340 350 360
....*....|....*....|....*....|....*....|..
gi 111955084 1031 EEVHRRVKTALARKEEAVSSLRTQHEAAVKRADHLEELLEQH 1072
Cdd:COG5278 414 AAASAAEALELAEALAEALALAEEEALALAAASSELAEAGAA 455
|
|
| YhaN |
COG4717 |
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown]; |
827-1042 |
2.11e-03 |
|
Uncharacterized conserved protein YhaN, contains AAA domain [Function unknown];
Pssm-ID: 443752 [Multi-domain] Cd Length: 641 Bit Score: 42.06 E-value: 2.11e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 827 SALTRALRAEFEKGREEQERRHQMELNTLKqqlELERQAWEAGRTRKEEAWLLNREQELREEIRKGRDKEIELVIHRLEA 906
Cdd:COG4717 45 AMLLERLEKEADELFKPQGRKPELNLKELK---ELEEELKEAEEKEEEYAELQEELEELEEELEELEAELEELREELEKL 121
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 907 DMALAKEESEKAAEsRIKRLRDKYEAELSELEQSERKLQERCSELKGQLGEAEGENLRLQGLVRQ----KERALEDAQAV 982
Cdd:COG4717 122 EKLLQLLPLYQELE-ALEAELAELPERLEELEERLEELRELEEELEELEAELAELQEELEELLEQlslaTEEELQDLAEE 200
|
170 180 190 200 210 220
....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 983 NEQLSSERSNLAQVIRQEfEDRLAASEEETRQAKAELATLQARQQLELEEVHRRVKTALA 1042
Cdd:COG4717 201 LEELQQRLAELEEELEEA-QEELEELEEELEQLENELEAAALEERLKEARLLLLIAAALL 259
|
|
| PRK09039 |
PRK09039 |
peptidoglycan -binding protein; |
885-1044 |
2.23e-03 |
|
peptidoglycan -binding protein;
Pssm-ID: 181619 [Multi-domain] Cd Length: 343 Bit Score: 41.49 E-value: 2.23e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 885 LREEIrKGRDKEIELVIHRLeADMA--LAKEESEKAA-ESRIKRLRdkyeAELSELEqSERklqercSELKGQLGEAEGE 961
Cdd:PRK09039 44 LSREI-SGKDSALDRLNSQI-AELAdlLSLERQGNQDlQDSVANLR----ASLSAAE-AER------SRLQALLAELAGA 110
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 962 NLRLQGLVRQKERALEDAQAV-----------NEQLSSERSNLAQVirqefEDRLAASEEETRQAKAELATLQarqqlel 1030
Cdd:PRK09039 111 GAAAEGRAGELAQELDSEKQVsaralaqvellNQQIAALRRQLAAL-----EAALDASEKRDRESQAKIADLG------- 178
|
170
....*....|....
gi 111955084 1031 eevhRRVKTALARK 1044
Cdd:PRK09039 179 ----RRLNVALAQR 188
|
|
| SMC_prok_B |
TIGR02168 |
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
564-837 |
2.30e-03 |
|
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins]
Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 41.97 E-value: 2.30e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 564 SEVSTSVMRLKLEVEEKKQAMLLLQRA---LAQQRDLTARRVKETEKALSRQLQrQREHYEATIQRHLAFIDQLIEDKKV 640
Cdd:TIGR02168 729 SALRKDLARLEAEVEQLEERIAQLSKElteLEAEIEELEERLEEAEEELAEAEA-EIEELEAQIEQLKEELKALREALDE 807
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 641 LsekcEAVVAELKQEDQRCTERVAQAQAQHELEIKKLKELMSATEKARREkwISEKTKKIKEVTVRGLEPEIQ---KLIA 717
Cdd:TIGR02168 808 L----RAELTLLNEEAANLRERLESLERRIAATERRLEDLEEQIEELSED--IESLAAEIEELEELIEELESEleaLLNE 881
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 718 RHKQEVRRLKSLHEAELLQSDERASQRCLRQAEELREQLEREKEALgQQERERARQRFQQHLEQ--EQWAL--------- 786
Cdd:TIGR02168 882 RASLEEALALLRSELEELSEELRELESKRSELRRELEELREKLAQL-ELRLEGLEVRIDNLQERlsEEYSLtleeaeale 960
|
250 260 270 280 290 300 310
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*...
gi 111955084 787 -------QQQRQRL--------------------YSEVAEERERLgqqaARQRAELEELRQQLEESSSALTRALRAEF 837
Cdd:TIGR02168 961 nkieddeEEARRRLkrlenkikelgpvnlaaieeYEELKERYDFL----TAQKEDLTEAKETLEEAIEEIDREARERF 1034
|
|
| COG2433 |
COG2433 |
Possible nuclease of RNase H fold, RuvC/YqgF family [General function prediction only]; |
765-929 |
2.48e-03 |
|
Possible nuclease of RNase H fold, RuvC/YqgF family [General function prediction only];
Pssm-ID: 441980 [Multi-domain] Cd Length: 644 Bit Score: 41.77 E-value: 2.48e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 765 QQERERARQRFQQHLEQEQWALQQQRQRLYSEVaeerERLGQQAARQRAELEELRQQLEESSSALTRALRAEFEKGREEQ 844
Cdd:COG2433 390 LPEEEPEAEREKEHEERELTEEEEEIRRLEEQV----ERLEAEVEELEAELEEKDERIERLERELSEARSEERREIRKDR 465
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 845 E-RRHQMELNTLKQQLELERqaweagRTRKEEAWLLNREQELREEIRKGRD---KEIELV----IHRLEADMALAK---- 912
Cdd:COG2433 466 EiSRLDREIERLERELEEER------ERIEELKRKLERLKELWKLEHSGELvpvKVVEKFtkeaIRRLEEEYGLKEgdvv 539
|
170
....*....|....*....
gi 111955084 913 --EESEKAAESRIKRLRDK 929
Cdd:COG2433 540 ylRDASGAGRSTAELLAEA 558
|
|
| DR0291 |
COG1579 |
Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General ... |
922-1071 |
2.93e-03 |
|
Predicted nucleic acid-binding protein DR0291, contains C4-type Zn-ribbon domain [General function prediction only];
Pssm-ID: 441187 [Multi-domain] Cd Length: 236 Bit Score: 40.68 E-value: 2.93e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 922 RIKRLRDKYEAELSELEQSERKLQERCSELKGQLGEAEGENLRLQGLVRQKERALEDAQavnEQLSSERSNlaqvirqef 1001
Cdd:COG1579 21 RLEHRLKELPAELAELEDELAALEARLEAAKTELEDLEKEIKRLELEIEEVEARIKKYE---EQLGNVRNN--------- 88
|
90 100 110 120 130 140 150
....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 1002 edrlaaseEETRQAKAELATLQARQQlELEEVHRRVKTALARKEEAVSSLRTQHEAAVKRADHLEELLEQ 1071
Cdd:COG1579 89 --------KEYEALQKEIESLKRRIS-DLEDEILELMERIEELEEELAELEAELAELEAELEEKKAELDE 149
|
|
| ClpA |
COG0542 |
ATP-dependent Clp protease, ATP-binding subunit ClpA [Posttranslational modification, protein ... |
813-914 |
2.98e-03 |
|
ATP-dependent Clp protease, ATP-binding subunit ClpA [Posttranslational modification, protein turnover, chaperones];
Pssm-ID: 440308 [Multi-domain] Cd Length: 836 Bit Score: 41.61 E-value: 2.98e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 813 AELEELRQQLEEsssaLTR---ALRAEFEKGREEQERRHQMELNTLKQQLELERQAWEAGRTRKEEAWLLNREQELREEI 889
Cdd:COG0542 411 EELDELERRLEQ----LEIekeALKKEQDEASFERLAELRDELAELEEELEALKARWEAEKELIEEIQELKEELEQRYGK 486
|
90 100
....*....|....*....|....*
gi 111955084 890 RKGRDKEIELVIHRLEADMALAKEE 914
Cdd:COG0542 487 IPELEKELAELEEELAELAPLLREE 511
|
|
| CCDC158 |
pfam15921 |
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. ... |
789-974 |
3.16e-03 |
|
Coiled-coil domain-containing protein 158; CCDC158 is a family of proteins found in eukaryotes. The function is not known.
Pssm-ID: 464943 [Multi-domain] Cd Length: 1112 Bit Score: 41.64 E-value: 3.16e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 789 QRQRLYSEVAEERERLGQQAARQRAELEELRQQLEesssaltrALRAEFEKGREEQE---RRHQMELNTLKQQLELERQA 865
Cdd:pfam15921 643 ERLRAVKDIKQERDQLLNEVKTSRNELNSLSEDYE--------VLKRNFRNKSEEMEtttNKLKMQLKSAQSELEQTRNT 714
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 866 WEAGRTRKEEAWLLNREQELREEIRKGRDKEIELVIHRLEADMALA-------KEESEKAAE--SRIKRLRDKYEAELSE 936
Cdd:pfam15921 715 LKSMEGSDGHAMKVAMGMQKQITAKRGQIDALQSKIQFLEEAMTNAnkekhflKEEKNKLSQelSTVATEKNKMAGELEV 794
|
170 180 190
....*....|....*....|....*....|....*...
gi 111955084 937 LEQSERKLQERCSELKGQLGEAEGENLRLQGLVRQKER 974
Cdd:pfam15921 795 LRSQERRLKEKVANMEVALDKASLQFAECQDIIQRQEQ 832
|
|
| mukB |
PRK04863 |
chromosome partition protein MukB; |
590-1075 |
3.39e-03 |
|
chromosome partition protein MukB;
Pssm-ID: 235316 [Multi-domain] Cd Length: 1486 Bit Score: 41.48 E-value: 3.39e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 590 ALAQQRDLTARRVkETEKALSRQLQRQREHYEATIQRHLAFidqliedkkVLSEKCEAVVAELKQEDQRCTERVAQAQA- 668
Cdd:PRK04863 790 QLRAEREELAERY-ATLSFDVQKLQRLHQAFSRFIGSHLAV---------AFEADPEAELRQLNRRRVELERALADHESq 859
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 669 --QHELEIKKLKELMSATEKARREKWISEKTKKIKEVtvRGLEPEIQKL------IARHKQEVRRLKSLheAELLQSDer 740
Cdd:PRK04863 860 eqQQRSQLEQAKEGLSALNRLLPRLNLLADETLADRV--EEIREQLDEAeeakrfVQQHGNALAQLEPI--VSVLQSD-- 933
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 741 asqrclrqaeelreqlerekealgQQERERARQRFQQhlEQEQWALQQQRQRLYSEVAEERERLGQQAARQR----AEL- 815
Cdd:PRK04863 934 ------------------------PEQFEQLKQDYQQ--AQQTQRDAKQQAFALTEVVQRRAHFSYEDAAEMlaknSDLn 987
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 816 EELRQQLEESSSALTRAlraefekgrEEQERRHQMELNTLKQQLelerQAWEAGRTRKEEawllnREQELREEIrkgrdk 895
Cdd:PRK04863 988 EKLRQRLEQAEQERTRA---------REQLRQAQAQLAQYNQVL----ASLKSSYDAKRQ-----MLQELKQEL------ 1043
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 896 eielvihrleADMAL-AKEESEKAAESRikrlRDKYEAELSEleqserkLQERCSELKGQLGEAEGEnlrLQGLVRQKER 974
Cdd:PRK04863 1044 ----------QDLGVpADSGAEERARAR----RDELHARLSA-------NRSRRNQLEKQLTFCEAE---MDNLTKKLRK 1099
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 975 ALEDAQAVNEQLSSERSNLAQVIRqefedRLAASEEETRQAKAELATLQARQqleleevhrrvktALARKEEAVSSLRTq 1054
Cdd:PRK04863 1100 LERDYHEMREQVVNAKAGWCAVLR-----LVKDNGVERRLHRRELAYLSADE-------------LRSMSDKALGALRL- 1160
|
490 500
....*....|....*....|....
gi 111955084 1055 heaAVKRADHLEELL---EQHRRP 1075
Cdd:PRK04863 1161 ---AVADNEHLRDVLrlsEDPKRP 1181
|
|
| MukB |
COG3096 |
Chromosome condensin MukBEF, ATPase and DNA-binding subunit MukB [Cell cycle control, cell ... |
588-890 |
3.73e-03 |
|
Chromosome condensin MukBEF, ATPase and DNA-binding subunit MukB [Cell cycle control, cell division, chromosome partitioning];
Pssm-ID: 442330 [Multi-domain] Cd Length: 1470 Bit Score: 41.48 E-value: 3.73e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 588 QRALAQQRDLTARRVKE------TEKALSRQLQRQREHYE--ATIQRHLAFIDQLIEDKKVLSEKCEA---VVAELKQED 656
Cdd:COG3096 298 RRQLAEEQYRLVEMAREleelsaRESDLEQDYQAASDHLNlvQTALRQQEKIERYQEDLEELTERLEEqeeVVEEAAEQL 377
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 657 QRCTERVAQAQAQHE------------LEIKKLKEL-----MSATEKARR------------EKWISEKTKKIKEVTVRG 707
Cdd:COG3096 378 AEAEARLEAAEEEVDslksqladyqqaLDVQQTRAIqyqqaVQALEKARAlcglpdltpenaEDYLAAFRAKEQQATEEV 457
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 708 LEPEiQKL------IARHKQ----------EVRRLKSLHEAELLQSDERASQRCLRQAEELREQLEREKEALGQQER-ER 770
Cdd:COG3096 458 LELE-QKLsvadaaRRQFEKayelvckiagEVERSQAWQTARELLRRYRSQQALAQRLQQLRAQLAELEQRLRQQQNaER 536
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 771 ARQRFQQH----------LEQEQWALQQQRQRLYSEVAEERErlgqQAARQRAELEELRQQLEESSS------ALTRALR 834
Cdd:COG3096 537 LLEEFCQRigqqldaaeeLEELLAELEAQLEELEEQAAEAVE----QRSELRQQLEQLRARIKELAArapawlAAQDALE 612
|
330 340 350 360 370
....*....|....*....|....*....|....*....|....*....|....*.
gi 111955084 835 AEFEKGREEQERRHQMeLNTLKQQLELERQAweagrtRKEEAWLLNREQELREEIR 890
Cdd:COG3096 613 RLREQSGEALADSQEV-TAAMQQLLEREREA------TVERDELAARKQALESQIE 661
|
|
| PRK12704 |
PRK12704 |
phosphodiesterase; Provisional |
895-1063 |
3.78e-03 |
|
phosphodiesterase; Provisional
Pssm-ID: 237177 [Multi-domain] Cd Length: 520 Bit Score: 41.30 E-value: 3.78e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 895 KEIELVIHRLEADMALAKEESEKAAESRIKRLRDKYEAEL----SELEQSERKLQERCSELKGQLGEAEGENLRLQglvr 970
Cdd:PRK12704 38 EEAKRILEEAKKEAEAIKKEALLEAKEEIHKLRNEFEKELrerrNELQKLEKRLLQKEENLDRKLELLEKREEELE---- 113
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 971 QKERALEDAQAVNEQLSSERSNLAQVIRQEFEDRLAASEEEtrqakaelatlqARQQLeLEEVHRRVktalarKEEAVSS 1050
Cdd:PRK12704 114 KKEKELEQKQQELEKKEEELEELIEEQLQELERISGLTAEE------------AKEIL-LEKVEEEA------RHEAAVL 174
|
170
....*....|...
gi 111955084 1051 LRTQHEAAVKRAD 1063
Cdd:PRK12704 175 IKEIEEEAKEEAD 187
|
|
| GBP_C |
cd16269 |
Guanylate-binding protein, C-terminal domain; Guanylate-binding protein (GBP), C-terminal ... |
796-899 |
4.57e-03 |
|
Guanylate-binding protein, C-terminal domain; Guanylate-binding protein (GBP), C-terminal domain. Guanylate-binding proteins (GBPs) are synthesized after activation of the cell by interferons. The biochemical properties of GBPs are clearly different from those of Ras-like and heterotrimeric GTP-binding proteins. They bind guanine nucleotides with low affinity (micromolar range), are stable in their absence, and have a high turnover GTPase. In addition to binding GDP/GTP, they have the unique ability to bind GMP with equal affinity and hydrolyze GTP not only to GDP, but also to GMP. This C-terminal domain has been shown to mediate inhibition of endothelial cell proliferation by inflammatory cytokines.
Pssm-ID: 293879 [Multi-domain] Cd Length: 291 Bit Score: 40.25 E-value: 4.57e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 796 EVAEERERlGQQAARQRAELEELRQQLEESssaltralraefekgREEQERRHQMELNTLKQQLELERQaweagRTRKEE 875
Cdd:cd16269 199 EIEAERAK-AEAAEQERKLLEEQQRELEQK---------------LEDQERSYEEHLRQLKEKMEEERE-----NLLKEQ 257
|
90 100
....*....|....*....|....*
gi 111955084 876 AWLL-NREQELREEIRKGRDKEIEL 899
Cdd:cd16269 258 ERALeSKLKEQEALLEEGFKEQAEL 282
|
|
| COG4913 |
COG4913 |
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown]; |
649-1021 |
4.77e-03 |
|
Uncharacterized conserved protein, contains a C-terminal ATPase domain [Function unknown];
Pssm-ID: 443941 [Multi-domain] Cd Length: 1089 Bit Score: 41.05 E-value: 4.77e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 649 VAELKQEDQRCTERVAQAQAQheleIKKLKELMSATEKaRREKWISEKTKKIKEVTVRGLEPEIQKLiarhKQEVRRLks 728
Cdd:COG4913 612 LAALEAELAELEEELAEAEER----LEALEAELDALQE-RREALQRLAEYSWDEIDVASAEREIAEL----EAELERL-- 680
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 729 lheaellqsdeRASQRCLRQAEELReqlEREKEALGQQERERARqrfqqhLEQEQWALQQQRQRLYSEVAEERERLGQ-- 806
Cdd:COG4913 681 -----------DASSDDLAALEEQL---EELEAELEELEEELDE------LKGEIGRLEKELEQAEEELDELQDRLEAae 740
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 807 --QAARQRAELEELRQQLEEssSALTRALRAEFEKGREEQERRhqmeLNTLKQQLELERQawEAGRTRKEEAWLLNREQE 884
Cdd:COG4913 741 dlARLELRALLEERFAAALG--DAVERELRENLEERIDALRAR----LNRAEEELERAMR--AFNREWPAETADLDADLE 812
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 885 LREEIRKGRDKEIELVIHRLEADMALAKEESEKAAESRIkrlrdkyeaeLSELEQSERKLQERCSELKGQLGEAE---GE 961
Cdd:COG4913 813 SLPEYLALLDRLEEDGLPEYEERFKELLNENSIEFVADL----------LSKLRRAIREIKERIDPLNDSLKRIPfgpGR 882
|
330 340 350 360 370 380
....*....|....*....|....*....|....*....|....*....|....*....|....*.
gi 111955084 962 NLRLQGLVRQKERALE---DAQAVNEQLSSERSNLAQ---VIRQEFEDRLAASEEETRQAKAELAT 1021
Cdd:COG4913 883 YLRLEARPRPDPEVREfrqELRAVTSGASLFDEELSEarfAALKRLIERLRSEEEESDRRWRARVL 948
|
|
| Mplasa_alph_rch |
TIGR04523 |
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of ... |
786-1054 |
4.90e-03 |
|
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of Mycoplasma species. Members average 750 amino acids in length, including signal peptide. Sequences are predicted (Jpred 3) to be almost entirely alpha-helical. These sequences show strong periodicity (consistent with long alpha helical structures) and low complexity rich in D,E,N,Q, and K. Genes encoding these proteins are often found in tandem. The function is unknown.
Pssm-ID: 275316 [Multi-domain] Cd Length: 745 Bit Score: 40.77 E-value: 4.90e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 786 LQQQRQRLYSEVAEERERLGQQaarqRAELEELRQQLEESSSALTRALRAEFEKGRE-EQERRHQMELNTLKQQLELERQ 864
Cdd:TIGR04523 223 LKKQNNQLKDNIEKKQQEINEK----TTEISNTQTQLNQLKDEQNKIKKQLSEKQKElEQNNKKIKELEKQLNQLKSEIS 298
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 865 AWEagrTRKEEAWLlnreQELREEIRKGRDKEIELvihrleadmalakeesekaaesrikrlrdkyEAELSELEQSERKL 944
Cdd:TIGR04523 299 DLN---NQKEQDWN----KELKSELKNQEKKLEEI-------------------------------QNQISQNNKIISQL 340
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 945 QERCSELKGQLGEAEGENLRLQGLVRQKERALEDAQAVNEQLSSERSNLAQVIrQEFEDRLAASEEETRQAKAELATLQA 1024
Cdd:TIGR04523 341 NEQISQLKKELTNSESENSEKQRELEEKQNEIEKLKKENQSYKQEIKNLESQI-NDLESKIQNQEKLNQQKDEQIKKLQQ 419
|
250 260 270
....*....|....*....|....*....|
gi 111955084 1025 RQQLeLEEVHRRVKTALARKEEAVSSLRTQ 1054
Cdd:TIGR04523 420 EKEL-LEKEIERLKETIIKNNSEIKDLTNQ 448
|
|
| PRK00409 |
PRK00409 |
recombination and DNA strand exchange inhibitor protein; Reviewed |
923-1048 |
4.95e-03 |
|
recombination and DNA strand exchange inhibitor protein; Reviewed
Pssm-ID: 234750 [Multi-domain] Cd Length: 782 Bit Score: 40.97 E-value: 4.95e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 923 IKRLRDKYEAELSELEQSERKLQErcselkgQLGEAEGENLRLQGLVRQKERALEDAQAVNEQLSSERSNLAQVIRQEFE 1002
Cdd:PRK00409 504 IEEAKKLIGEDKEKLNELIASLEE-------LERELEQKAEEAEALLKEAEKLKEELEEKKEKLQEEEDKLLEEAEKEAQ 576
|
90 100 110 120 130
....*....|....*....|....*....|....*....|....*....|.
gi 111955084 1003 DRLAASEEETRQAKAELATLQARQQL-----ELEEVHRRVKTALARKEEAV 1048
Cdd:PRK00409 577 QAIKEAKKEADEIIKELRQLQKGGYAsvkahELIEARKRLNKANEKKEKKK 627
|
|
| Mplasa_alph_rch |
TIGR04523 |
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of ... |
631-986 |
5.38e-03 |
|
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of Mycoplasma species. Members average 750 amino acids in length, including signal peptide. Sequences are predicted (Jpred 3) to be almost entirely alpha-helical. These sequences show strong periodicity (consistent with long alpha helical structures) and low complexity rich in D,E,N,Q, and K. Genes encoding these proteins are often found in tandem. The function is unknown.
Pssm-ID: 275316 [Multi-domain] Cd Length: 745 Bit Score: 40.77 E-value: 5.38e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 631 IDQLIEDKKVLSEKceavVAELKQEDQRCTERVAQaqaqheleIKKLKELMSATEKARREKWISEKTKKIKEV--TVRGL 708
Cdd:TIGR04523 259 KDEQNKIKKQLSEK----QKELEQNNKKIKELEKQ--------LNQLKSEISDLNNQKEQDWNKELKSELKNQekKLEEI 326
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 709 EPEI---QKLIARHKQEVRRLKSlhEAELLQSDERASQRCLRQAEELREQLEREKEALGQQ------ERERARQRFQQHL 779
Cdd:TIGR04523 327 QNQIsqnNKIISQLNEQISQLKK--ELTNSESENSEKQRELEEKQNEIEKLKKENQSYKQEiknlesQINDLESKIQNQE 404
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 780 EQEQwALQQQRQRL---YSEVAEERERLGQQAARQRAELEEL-----------------RQQLEESSSALTRA---LRAE 836
Cdd:TIGR04523 405 KLNQ-QKDEQIKKLqqeKELLEKEIERLKETIIKNNSEIKDLtnqdsvkeliiknldntRESLETQLKVLSRSinkIKQN 483
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 837 FEKGREEQERRHQM--ELNTLKQQLELERQAWEagrtrKEEAWLLNREQELREEIRKGRDKEIELVIHRLEADMALAKEE 914
Cdd:TIGR04523 484 LEQKQKELKSKEKElkKLNEEKKELEEKVKDLT-----KKISSLKEKIEKLESEKKEKESKISDLEDELNKDDFELKKEN 558
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 915 SEK--------------------AAESRIKRLRDKYEAELSELEQSERKLQERCSELKGQLGEAEGENLRLQGLVR---- 970
Cdd:TIGR04523 559 LEKeideknkeieelkqtqkslkKKQEEKQELIDQKEKEKKDLIKEIEEKEKKISSLEKELEKAKKENEKLSSIIKniks 638
|
410
....*....|....*.
gi 111955084 971 QKERALEDAQAVNEQL 986
Cdd:TIGR04523 639 KKNKLKQEVKQIKETI 654
|
|
| rad50 |
TIGR00606 |
rad50; All proteins in this family for which functions are known are involvedin recombination, ... |
665-1051 |
5.50e-03 |
|
rad50; All proteins in this family for which functions are known are involvedin recombination, recombinational repair, and/or non-homologous end joining.They are components of an exonuclease complex with MRE11 homologs. This family is distantly related to the SbcC family of bacterial proteins.This family is based on the phylogenomic analysis of JA Eisen (1999, Ph.D. Thesis, Stanford University).
Pssm-ID: 129694 [Multi-domain] Cd Length: 1311 Bit Score: 40.80 E-value: 5.50e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 665 QAQAQHELEIKKLKELMSATEKARREKWISEKTKKIKEVTVRGLEPEIQKLIARHKQEVRRLKSLHEAE----LLQSDER 740
Cdd:TIGR00606 200 QKVQEHQMELKYLKQYKEKACEIRDQITSKEAQLESSREIVKSYENELDPLKNRLKEIEHNLSKIMKLDneikALKSRKK 279
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 741 ASQRCLRQAEELREQLEREKE------------ALGQQERERAR-QRFQQHLEQEQWALQQQRQRLYSEVAE---ERERL 804
Cdd:TIGR00606 280 QMEKDNSELELKMEKVFQGTDeqlndlyhnhqrTVREKERELVDcQRELEKLNKERRLLNQEKTELLVEQGRlqlQADRH 359
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 805 GQQAARQRAELEELRQQLE----ESSSALTRALRAEFEKGREEQERRHQMELNTLKQQLELERQAWEAGRTRKEEAWLLN 880
Cdd:TIGR00606 360 QEHIRARDSLIQSLATRLEldgfERGPFSERQIKNFHTLVIERQEDEAKTAAQLCADLQSKERLKQEQADEIRDEKKGLG 439
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 881 REQELREEIRKGRDKEIELVIHR-----------LEADMALAKEES-----EKAAESRIKRLRDKY-EAELSELEQSERK 943
Cdd:TIGR00606 440 RTIELKKEILEKKQEELKFVIKElqqlegssdriLELDQELRKAERelskaEKNSLTETLKKEVKSlQNEKADLDRKLRK 519
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 944 LQERCSELkgqlgEAEGENL-RLQGLVRQKERALEDAQAVNEQLSSERSNLAQVI--RQEFEDRLAASEEETRQAKAELA 1020
Cdd:TIGR00606 520 LDQEMEQL-----NHHTTTRtQMEMLTKDKMDKDEQIRKIKSRHSDELTSLLGYFpnKKQLEDWLHSKSKEINQTRDRLA 594
|
410 420 430
....*....|....*....|....*....|.
gi 111955084 1021 TLQARQQlELEEVHRRVKTALARKEEAVSSL 1051
Cdd:TIGR00606 595 KLNKELA-SLEQNKNHINNELESKEEQLSSY 624
|
|
| PRK00409 |
PRK00409 |
recombination and DNA strand exchange inhibitor protein; Reviewed |
608-702 |
5.72e-03 |
|
recombination and DNA strand exchange inhibitor protein; Reviewed
Pssm-ID: 234750 [Multi-domain] Cd Length: 782 Bit Score: 40.58 E-value: 5.72e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 608 ALSRQLQRQREHYEATIQRHLAFIDQLIEDKKVLSEKCEAVVAELKQEDQrctERVAQAQAQHELEIKKLKELMSATEKA 687
Cdd:PRK00409 527 ELERELEQKAEEAEALLKEAEKLKEELEEKKEKLQEEEDKLLEEAEKEAQ---QAIKEAKKEADEIIKELRQLQKGGYAS 603
|
90
....*....|....*
gi 111955084 688 RREKWISEKTKKIKE 702
Cdd:PRK00409 604 VKAHELIEARKRLNK 618
|
|
| Myosin_tail_1 |
pfam01576 |
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and ... |
632-993 |
8.38e-03 |
|
Myosin tail; The myosin molecule is a multi-subunit complex made up of two heavy chains and four light chains it is a fundamental contractile protein found in all eukaryote cell types. This family consists of the coiled-coil myosin heavy chain tail region. The coiled-coil is composed of the tail from two molecules of myosin. These can then assemble into the macromolecular thick filament. The coiled-coil region provides the structural backbone the thick filament.
Pssm-ID: 460256 [Multi-domain] Cd Length: 1081 Bit Score: 40.16 E-value: 8.38e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 632 DQLIEDKKVLSEKCEAVVAELKQEDQRCTERVAqAQAQHELEIKKLKELMSATEKARRE--KWISEKTKKIKEVtVRGLE 709
Cdd:pfam01576 738 EQGEEKRRQLVKQVRELEAELEDERKQRAQAVA-AKKKLELDLKELEAQIDAANKGREEavKQLKKLQAQMKDL-QRELE 815
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 710 PEIQ---KLIARHKQEVRRLKSLhEAELLQSDER--ASQRCLRQAeelreqlerekealgQQERERARQRFQQHLEQEqw 784
Cdd:pfam01576 816 EARAsrdEILAQSKESEKKLKNL-EAELLQLQEDlaASERARRQA---------------QQERDELADEIASGASGK-- 877
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 785 alqqqrqrlySEVAEERERLGQQAARQRAELEELRQQLEESSsaltralraefekgreEQERRHQMELNTLKQQLELERQ 864
Cdd:pfam01576 878 ----------SALQDEKRRLEARIAQLEEELEEEQSNTELLN----------------DRLRKSTLQVEQLTTELAAERS 931
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 865 AWEAGRTRKEEAWLLNREQELR-EEIRKGRDKEIELVIHRLEADMA-----LAKEESEKAAESRIKRLRDKYEAELSELE 938
Cdd:pfam01576 932 TSQKSESARQQLERQNKELKAKlQEMEGTVKSKFKSSIAALEAKIAqleeqLEQESRERQAANKLVRRTEKKLKEVLLQV 1011
|
330 340 350 360 370 380
....*....|....*....|....*....|....*....|....*....|....*....|....*.
gi 111955084 939 QSER-----------KLQERCSELKGQLGEAEGENLRLQGLVRQKERALEDAQAVNEQLSSERSNL 993
Cdd:pfam01576 1012 EDERrhadqykdqaeKGNSRMKQLKRQLEEAEEEASRANAARRKLQRELDDATESNESMNREVSTL 1077
|
|
| CALCOCO1 |
pfam07888 |
Calcium binding and coiled-coil domain (CALCOCO1) like; Proteins found in this family are ... |
636-977 |
8.84e-03 |
|
Calcium binding and coiled-coil domain (CALCOCO1) like; Proteins found in this family are similar to the coiled-coil transcriptional coactivator protein coexpressed by Mus musculus (CoCoA/CALCOCO1). This protein binds to a highly conserved N-terminal domain of p160 coactivators, such as GRIP1, and thus enhances transcriptional activation by a number of nuclear receptors. CALCOCO1 has a central coiled-coil region with three leucine zipper motifs, which is required for its interaction with GRIP1 and may regulate the autonomous transcriptional activation activity of the C-terminal region.
Pssm-ID: 462303 [Multi-domain] Cd Length: 488 Bit Score: 39.88 E-value: 8.84e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 636 EDKKVLSEKCEAVVAELKQEDQRCTERVAQAQAQHELEIKKLKELMSATEKARREKWISEKTKKIKEVTVRGLEPEIQKL 715
Cdd:pfam07888 62 ERYKRDREQWERQRRELESRVAELKEELRQSREKHEELEEKYKELSASSEELSEEKDALLAQRAAHEARIRELEEDIKTL 141
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 716 IARhkqevrrlKSLHEAELLQSDERAsQRCLRQAEELREQLEREKEALGQQERE-RARQRFQQHLEQEQWALQQQRQRLY 794
Cdd:pfam07888 142 TQR--------VLERETELERMKERA-KKAGAQRKEEEAERKQLQAKLQQTEEElRSLSKEFQELRNSLAQRDTQVLQLQ 212
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 795 SEVAEERERLGqQAARQRAELEELRQQLE------ESSSALTRALRAEFEKGREEQERRH------QMELNTLKQQLELE 862
Cdd:pfam07888 213 DTITTLTQKLT-TAHRKEAENEALLEELRslqerlNASERKVEGLGEELSSMAAQRDRTQaelhqaRLQAAQLTLQLADA 291
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 863 RQAWEAGRTRkeeaWLLNReQELREEIRKGRDKEIELVIHRLEADMALAKEESEK-AAESRIKRLRDKYEAELSEleqSE 941
Cdd:pfam07888 292 SLALREGRAR----WAQER-ETLQQSAEADKDRIEKLSAELQRLEERLQEERMEReKLEVELGREKDCNRVQLSE---SR 363
|
330 340 350
....*....|....*....|....*....|....*....
gi 111955084 942 RKLQERCSELKGQLGEAEGENLRLQGL---VRQKERALE 977
Cdd:pfam07888 364 RELQELKASLRVAQKEKEQLQAEKQELleyIRQLEQRLE 402
|
|
| rad50 |
TIGR00606 |
rad50; All proteins in this family for which functions are known are involvedin recombination, ... |
597-1068 |
9.21e-03 |
|
rad50; All proteins in this family for which functions are known are involvedin recombination, recombinational repair, and/or non-homologous end joining.They are components of an exonuclease complex with MRE11 homologs. This family is distantly related to the SbcC family of bacterial proteins.This family is based on the phylogenomic analysis of JA Eisen (1999, Ph.D. Thesis, Stanford University).
Pssm-ID: 129694 [Multi-domain] Cd Length: 1311 Bit Score: 40.03 E-value: 9.21e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 597 LTARRVKETEKALSRQLQRQREHYEATIQRHLAFIDQLIEDKKVL---SEKCEAVVAELKQEDQRCTERVAQAQAQHELE 673
Cdd:TIGR00606 354 LQADRHQEHIRARDSLIQSLATRLELDGFERGPFSERQIKNFHTLvieRQEDEAKTAAQLCADLQSKERLKQEQADEIRD 433
|
90 100 110 120 130 140 150 160
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 674 IKKLKELMSATEKARREKWISEKTKKIKEVtvRGLEPEIQKLIARhKQEVRRlkslHEAELLQSDERASQRCLRQaeeLR 753
Cdd:TIGR00606 434 EKKGLGRTIELKKEILEKKQEELKFVIKEL--QQLEGSSDRILEL-DQELRK----AERELSKAEKNSLTETLKK---EV 503
|
170 180 190 200 210 220 230 240
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 754 EQLEREKEALGQQERERARQRFQQHLEQEQwalQQQRQRLYSEVAEERERLGQQAARQRAELEEL------RQQLEESSS 827
Cdd:TIGR00606 504 KSLQNEKADLDRKLRKLDQEMEQLNHHTTT---RTQMEMLTKDKMDKDEQIRKIKSRHSDELTSLlgyfpnKKQLEDWLH 580
|
250 260 270 280 290 300 310 320
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 828 ALT----------RALRAEFEKGREEQERRHQMELNTLKQQLELERQAWEAGRTRKEEAWLLNreqeLREEIRKGR---- 893
Cdd:TIGR00606 581 SKSkeinqtrdrlAKLNKELASLEQNKNHINNELESKEEQLSSYEDKLFDVCGSQDEESDLER----LKEEIEKSSkqra 656
|
330 340 350 360 370 380 390 400
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 894 ---------DKEIELVIHRLEADMALAKE--ESEKAAESRIKRLRDKYEAELSELEQSERKLQERCSELKGQLGEAEGEN 962
Cdd:TIGR00606 657 mlagatavySQFITQLTDENQSCCPVCQRvfQTEAELQEFISDLQSKLRLAPDKLKSTESELKKKEKRRDEMLGLAPGRQ 736
|
410 420 430 440 450 460 470 480
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 963 LRLQGLVRQKERALEDAQAVNEQLSSERSNLAQvirQEFEDRLAASEEETRQAKAELATLQARQQLELEEVHRRVKTaLA 1042
Cdd:TIGR00606 737 SIIDLKEKEIPELRNKLQKVNRDIQRLKNDIEE---QETLLGTIMPEEESAKVCLTDVTIMERFQMELKDVERKIAQ-QA 812
|
490 500
....*....|....*....|....*.
gi 111955084 1043 RKEEAVSSLRTQHEAAVKRADHLEEL 1068
Cdd:TIGR00606 813 AKLQGSDLDRTVQQVNQEKQEKQHEL 838
|
|
| PHA03252 |
PHA03252 |
DNA packaging tegument protein UL25; Provisional |
898-1009 |
9.96e-03 |
|
DNA packaging tegument protein UL25; Provisional
Pssm-ID: 223024 Cd Length: 589 Bit Score: 39.70 E-value: 9.96e-03
10 20 30 40 50 60 70 80
....*....|....*....|....*....|....*....|....*....|....*....|....*....|....*....|
gi 111955084 898 ELVIHRLEADMALA-KEESEKAAESRIKRLRDKyeaelSELEQSERKLQERCSELKGQLGEAegENLRLQGLVRQKERAL 976
Cdd:PHA03252 28 EEDLRRLRDDSALRlRRYREDLLRDRLLRRRLG-----EELDDLQKRLQTECEDLRSRVSEA--EALLLHDASGGEGGGA 100
|
90 100 110
....*....|....*....|....*....|...
gi 111955084 977 EDAQAVNEQLSSERSNLAQVIRQEFEDRLAASE 1009
Cdd:PHA03252 101 TNGGEVNVDGGADRTWLAQSPERPADGGPSGER 133
|
|
| |