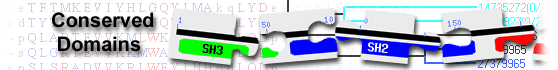


cell division cycle and apoptosis regulator protein 1 isoform a [Homo sapiens]
Protein Classification

List of domain hits
| Name | Accession | Description | Interval | E-value | |||
| DBC1 | pfam14443 | DBC1; DBC1 and it homologs from diverse eukaryotes are a catalytically inactive version of the ... |
479-604 | 1.39e-64 | |||
DBC1; DBC1 and it homologs from diverse eukaryotes are a catalytically inactive version of the Nudix hydrolase (MutT) domain. DBC1 is predicted to bind NAD metabolites and regulate the activity of SIRT1 or related deacetylases by sensing the soluble products or substrates of the NAD-dependent deacetylation reaction. : Pssm-ID: 464175 Cd Length: 123 Bit Score: 214.13 E-value: 1.39e-64
|
|||||||
| S1-like | pfam14444 | S1-like; S1-like RNA binding domain found in DBC1 |
148-204 | 7.83e-37 | |||
S1-like; S1-like RNA binding domain found in DBC1 : Pssm-ID: 464176 Cd Length: 58 Bit Score: 132.49 E-value: 7.83e-37
|
|||||||
| LAIKA | pfam19256 | LAIKA domain; This presumed domain is found exclusively in the CCAR1 protein. |
723-790 | 3.40e-33 | |||
LAIKA domain; This presumed domain is found exclusively in the CCAR1 protein. : Pssm-ID: 466012 [Multi-domain] Cd Length: 68 Bit Score: 122.35 E-value: 3.40e-33
|
|||||||
| BURAN | pfam19257 | BURAN domain; This presumed domain is found exclusively in the CCAR1 protein. |
372-454 | 3.50e-28 | |||
BURAN domain; This presumed domain is found exclusively in the CCAR1 protein. : Pssm-ID: 466013 Cd Length: 82 Bit Score: 108.56 E-value: 3.50e-28
|
|||||||
| SAP | smart00513 | Putative DNA-binding (bihelical) motif predicted to be involved in chromosomal organisation; |
637-670 | 2.96e-07 | |||
Putative DNA-binding (bihelical) motif predicted to be involved in chromosomal organisation; : Pssm-ID: 128789 [Multi-domain] Cd Length: 35 Bit Score: 47.48 E-value: 2.96e-07
|
|||||||
| SMC_prok_B super family | cl37069 | chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
1010-1145 | 2.36e-05 | |||
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins] The actual alignment was detected with superfamily member TIGR02168: Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 48.90 E-value: 2.36e-05
|
|||||||
| Name | Accession | Description | Interval | E-value | |||
| DBC1 | pfam14443 | DBC1; DBC1 and it homologs from diverse eukaryotes are a catalytically inactive version of the ... |
479-604 | 1.39e-64 | |||
DBC1; DBC1 and it homologs from diverse eukaryotes are a catalytically inactive version of the Nudix hydrolase (MutT) domain. DBC1 is predicted to bind NAD metabolites and regulate the activity of SIRT1 or related deacetylases by sensing the soluble products or substrates of the NAD-dependent deacetylation reaction. Pssm-ID: 464175 Cd Length: 123 Bit Score: 214.13 E-value: 1.39e-64
|
|||||||
| S1-like | pfam14444 | S1-like; S1-like RNA binding domain found in DBC1 |
148-204 | 7.83e-37 | |||
S1-like; S1-like RNA binding domain found in DBC1 Pssm-ID: 464176 Cd Length: 58 Bit Score: 132.49 E-value: 7.83e-37
|
|||||||
| LAIKA | pfam19256 | LAIKA domain; This presumed domain is found exclusively in the CCAR1 protein. |
723-790 | 3.40e-33 | |||
LAIKA domain; This presumed domain is found exclusively in the CCAR1 protein. Pssm-ID: 466012 [Multi-domain] Cd Length: 68 Bit Score: 122.35 E-value: 3.40e-33
|
|||||||
| BURAN | pfam19257 | BURAN domain; This presumed domain is found exclusively in the CCAR1 protein. |
372-454 | 3.50e-28 | |||
BURAN domain; This presumed domain is found exclusively in the CCAR1 protein. Pssm-ID: 466013 Cd Length: 82 Bit Score: 108.56 E-value: 3.50e-28
|
|||||||
| SAP | smart00513 | Putative DNA-binding (bihelical) motif predicted to be involved in chromosomal organisation; |
637-670 | 2.96e-07 | |||
Putative DNA-binding (bihelical) motif predicted to be involved in chromosomal organisation; Pssm-ID: 128789 [Multi-domain] Cd Length: 35 Bit Score: 47.48 E-value: 2.96e-07
|
|||||||
| SAP | pfam02037 | SAP domain; The SAP (after SAF-A/B, Acinus and PIAS) motif is a putative DNA/RNA binding ... |
637-670 | 3.37e-07 | |||
SAP domain; The SAP (after SAF-A/B, Acinus and PIAS) motif is a putative DNA/RNA binding domain found in diverse nuclear and cytoplasmic proteins. Pssm-ID: 460424 [Multi-domain] Cd Length: 35 Bit Score: 47.40 E-value: 3.37e-07
|
|||||||
| SMC_prok_B | TIGR02168 | chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
1010-1145 | 2.36e-05 | |||
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins] Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 48.90 E-value: 2.36e-05
|
|||||||
| HMMR_N | pfam15905 | Hyaluronan mediated motility receptor N-terminal; HMMR_N is the N-terminal region of ... |
1041-1146 | 2.41e-03 | |||
Hyaluronan mediated motility receptor N-terminal; HMMR_N is the N-terminal region of eukaryotic hyaluronan-mediated motility receptor proteins. The protein is functionally associated with BRCA1 and thus predicted to be a common, low-penetrance breast cancer candidate. Pssm-ID: 464932 [Multi-domain] Cd Length: 329 Bit Score: 41.34 E-value: 2.41e-03
|
|||||||
| secA | PRK12903 | preprotein translocase subunit SecA; Reviewed |
1037-1146 | 5.68e-03 | |||
preprotein translocase subunit SecA; Reviewed Pssm-ID: 237258 [Multi-domain] Cd Length: 925 Bit Score: 40.81 E-value: 5.68e-03
|
|||||||
| Name | Accession | Description | Interval | E-value | ||||
| DBC1 | pfam14443 | DBC1; DBC1 and it homologs from diverse eukaryotes are a catalytically inactive version of the ... |
479-604 | 1.39e-64 | ||||
DBC1; DBC1 and it homologs from diverse eukaryotes are a catalytically inactive version of the Nudix hydrolase (MutT) domain. DBC1 is predicted to bind NAD metabolites and regulate the activity of SIRT1 or related deacetylases by sensing the soluble products or substrates of the NAD-dependent deacetylation reaction. Pssm-ID: 464175 Cd Length: 123 Bit Score: 214.13 E-value: 1.39e-64
|
||||||||
| S1-like | pfam14444 | S1-like; S1-like RNA binding domain found in DBC1 |
148-204 | 7.83e-37 | ||||
S1-like; S1-like RNA binding domain found in DBC1 Pssm-ID: 464176 Cd Length: 58 Bit Score: 132.49 E-value: 7.83e-37
|
||||||||
| LAIKA | pfam19256 | LAIKA domain; This presumed domain is found exclusively in the CCAR1 protein. |
723-790 | 3.40e-33 | ||||
LAIKA domain; This presumed domain is found exclusively in the CCAR1 protein. Pssm-ID: 466012 [Multi-domain] Cd Length: 68 Bit Score: 122.35 E-value: 3.40e-33
|
||||||||
| BURAN | pfam19257 | BURAN domain; This presumed domain is found exclusively in the CCAR1 protein. |
372-454 | 3.50e-28 | ||||
BURAN domain; This presumed domain is found exclusively in the CCAR1 protein. Pssm-ID: 466013 Cd Length: 82 Bit Score: 108.56 E-value: 3.50e-28
|
||||||||
| SAP | smart00513 | Putative DNA-binding (bihelical) motif predicted to be involved in chromosomal organisation; |
637-670 | 2.96e-07 | ||||
Putative DNA-binding (bihelical) motif predicted to be involved in chromosomal organisation; Pssm-ID: 128789 [Multi-domain] Cd Length: 35 Bit Score: 47.48 E-value: 2.96e-07
|
||||||||
| SAP | pfam02037 | SAP domain; The SAP (after SAF-A/B, Acinus and PIAS) motif is a putative DNA/RNA binding ... |
637-670 | 3.37e-07 | ||||
SAP domain; The SAP (after SAF-A/B, Acinus and PIAS) motif is a putative DNA/RNA binding domain found in diverse nuclear and cytoplasmic proteins. Pssm-ID: 460424 [Multi-domain] Cd Length: 35 Bit Score: 47.40 E-value: 3.37e-07
|
||||||||
| SMC_prok_B | TIGR02168 | chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of ... |
1010-1145 | 2.36e-05 | ||||
chromosome segregation protein SMC, common bacterial type; SMC (structural maintenance of chromosomes) proteins bind DNA and act in organizing and segregating chromosomes for partition. SMC proteins are found in bacteria, archaea, and eukaryotes. This family represents the SMC protein of most bacteria. The smc gene is often associated with scpB (TIGR00281) and scpA genes, where scp stands for segregation and condensation protein. SMC was shown (in Caulobacter crescentus) to be induced early in S phase but present and bound to DNA throughout the cell cycle. [Cellular processes, Cell division, DNA metabolism, Chromosome-associated proteins] Pssm-ID: 274008 [Multi-domain] Cd Length: 1179 Bit Score: 48.90 E-value: 2.36e-05
|
||||||||
| Mplasa_alph_rch | TIGR04523 | helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of ... |
986-1145 | 3.83e-05 | ||||
helix-rich Mycoplasma protein; Members of this family occur strictly within a subset of Mycoplasma species. Members average 750 amino acids in length, including signal peptide. Sequences are predicted (Jpred 3) to be almost entirely alpha-helical. These sequences show strong periodicity (consistent with long alpha helical structures) and low complexity rich in D,E,N,Q, and K. Genes encoding these proteins are often found in tandem. The function is unknown. Pssm-ID: 275316 [Multi-domain] Cd Length: 745 Bit Score: 48.09 E-value: 3.83e-05
|
||||||||
| HMMR_N | pfam15905 | Hyaluronan mediated motility receptor N-terminal; HMMR_N is the N-terminal region of ... |
1041-1146 | 2.41e-03 | ||||
Hyaluronan mediated motility receptor N-terminal; HMMR_N is the N-terminal region of eukaryotic hyaluronan-mediated motility receptor proteins. The protein is functionally associated with BRCA1 and thus predicted to be a common, low-penetrance breast cancer candidate. Pssm-ID: 464932 [Multi-domain] Cd Length: 329 Bit Score: 41.34 E-value: 2.41e-03
|
||||||||
| secA | PRK12903 | preprotein translocase subunit SecA; Reviewed |
1037-1146 | 5.68e-03 | ||||
preprotein translocase subunit SecA; Reviewed Pssm-ID: 237258 [Multi-domain] Cd Length: 925 Bit Score: 40.81 E-value: 5.68e-03
|
||||||||
| Blast search parameters | ||||
|
