

NCBI Bookshelf. A service of the National Library of Medicine, National Institutes of Health.
Lau J, Ioannidis JPA, Balk E, et al. Evaluation of Technologies for Identifying Acute Cardiac Ischemia in Emergency Departments. Rockville (MD): Agency for Healthcare Research and Quality (US); 2001 May. (Evidence Reports/Technology Assessments, No. 26.)
This publication is provided for historical reference only and the information may be out of date.

Evaluation of Technologies for Identifying Acute Cardiac Ischemia in Emergency Departments.
Show detailsThis evidence report on the evaluation of technologies for identifying ACI in the ED is based on a systematic review of the literature. Meetings and teleconferences of the EPC staff with technical experts representing the NHAAP Working Group were held to identify specific issues central to this report. A comprehensive search of the medical literature was conducted to identify studies addressing these technologies. Following the format of the original NHAAP report, we examined studies that assessed the diagnostic performance and the clinical impact of the technologies requested in this update.
For this evidence report, we compiled evidence tables of study features and results, appraised the methods of the studies, and summarized their results. When there was a sufficient number of studies with adequately reported data, we conducted meta-analyses to assess overall test performance and to estimate the clinical impact of the application of the technology. A decision and cost-effectiveness analysis was performed to gain insights into the tradeoffs between the clinical impact and costs of the technologies. Because of the complexity of the problem, the cost-effectiveness analysis should be viewed as a tool for decisionmaking and not as the definitive recommendation for diagnosing and managing ACI in the ED.
The NHAAP Working Group, which wrote the original report, served as the science partner of this updated report. The Working Group provided technical experts to work with the EPC staff to refine key questions and to identify important issues, helped find relevant studies, and provided critical input into the decision and cost-effectiveness analysis. Members of the NHAAP Working Group are listed in Appendix B.
Aim of the Evidence Report
The aim of this evidence report is to update the 1997 NHAAP Working Group report by examining the literature published since October 1994, to rigorously assess these technologies, to conduct meta-analyses when feasible, and to explore the application of these technologies with decision and cost-effectiveness analysis. However, the original 1997 report did not provide quantitative estimates of the test performance or clinical impact of the diagnostic technologies. To conduct meta-analyses, we re-examined all the studies reviewed in the original report, abstracted the necessary data, and combined these data with more recently published studies.
Literature Search
Studies for the literature review were identified primarily through a MEDLINE search of English language literature conducted between December 1998 and January 1999. In addition, we identified and retrieved all the studies under each of the technologies referenced in the 1997 report. We also consulted technical experts and examined references of published meta-analyses and selected review articles to identify additional studies. Several technical experts forwarded articles to us published in 1999, after our MEDLINE search was completed. Articles that met the inclusion criteria were incorporated in our evidence report.
Search Terms and Strategies
The literature search was conducted to identify clinical studies published from 1966 through December 1998. The MEDLINE search terms are listed in Table 2. Separate search strategies were developed for each of the diagnostic technologies and were based on three areas: setting, technology, and disease. The text words or MeSH headings for all technologies included "chest pain," "myocardial ischemia" or "infarction," "emergency," and "emergency service." The search was limited to studies on humans and published in English.
Table
Table 2. MEDLINE search strategies and terms (used in conjunction with OVID).
MEDLINE search results were printed and screened. Potential studies were identified for retrieval based on setting (if given), study question, population, and disease. Articles involving cost analysis, chest pain centers, minority and gender issues, and cocaine users (no relevant articles were found) were also retrieved. Studies with no clear reference to emergency department settings and populations with special comorbidities (e.g., patients with renal disease) were excluded. After retrieval, each paper was screened to verify that the setting and disease were appropriate and that the study question focused on diagnostic test performance, clinical impact, or both. Some studies compared two or more technologies with each other (e.g., sestamibi versus two-dimensional echocardiography [Kontos, Arrowood, Jesse, et al., 1998]).
A literature search was not performed for standard 12-lead ECG or thallium-201 scanning. The 12-lead ECG was not evaluated because it is a standard of care and is part of the WHO reference standard for diagnosing AMI. Thallium-201 scanning, as noted in the earlier Working Group report, is not feasible in the ED, and a better radioisotope (technetium-99m sestamibi) has superseded this technology.
Study Selection
A MEDLINE search for the years 1966 through 1998 identified 6,667 titles (Table 3). About one-third of the titles were published from 1994 onward, indicating increased research activities in this topic over the past 5 years compared with the previous 27 years. We screened the titles and abstracts of these citations and retrieved 407 full-length articles for further examination. Reports published only as abstracts in proceedings were rejected from further consideration. Several abstracts were used in the earlier Working Group report. Subsequently published, full articles based on these abstracts are used in the current evidence report. Specific inclusion criteria are discussed below.
Table
Table 3. Number of MEDLINE citations found for technologies used to diagnose acute cardiac ischemia in emergency departments.
Patient Populations and Settings Studied
We followed the general approach for selecting the study setting taken by the Working Group in their report: "In these evaluations of the clinical data, results were considered applicable to the aims of this report only if they came from work done in the ED setting; results coming from other settings (e.g., the CCU) were used only if no ED-based data were available. Data from non-ED settings were used with the understanding that they suggest potential utility but do not directly apply to the emergency setting."
We accepted prospective and retrospective studies that evaluated one or more of the technologies considered in this evidence report that included patients 18 years and older who presented to the ED with symptoms suggestive of ACI. We placed no restrictions on the patients' gender or ethnicity. In general, ED testing consists of either a single test that occurs within the initial 4-hour period from presentation to the ED or repeated testing that occurs up to 14 hours after the patient's initial presentation to the ED. We accepted studies with minor deviations from this standard. Retrospective studies were considered in the Data from Other Clinical Studies sections in Chapter 3, Results.
Outcomes Considered in This Evidence Report
Acute cardiac ischemia is the primary outcome of interest in this evidence report. This condition includes AMI and UAP. However, because some of the diagnostic technologies (e.g., CK-MB) are specific for the detection of AMI, we also used AMI as an outcome. We used the WHO definition for AMI, which is based on the presence of two of three criteria: a history and physical examination compatible with AMI; characteristic ECG changes, such as ST-segment elevation and evolution; and characteristic rise and fall of the cardiac enzymes. Although some studies used Braunwald's classification for UAP, this diagnosis was not clearly defined in many articles. We accepted the UAP diagnosis as reported by the authors of the articles.
Some studies also reported ischemic cardiac outcomes by procedures performed, such as coronary artery bypass graft (CABG) surgery and angioplasty, or as significant coronary artery disease diagnosed by coronary angiography. Because some of the patients who underwent cardiac procedures may indeed have UAP, we included these procedures or diagnoses into a broadened category of ACI when there was little or no other evidence available using the stricter ACI definition of AMI and UAP. The use of this broadened definition is noted in specific sections of the evidence summary. We acknowledge that this categorization is not ideal, but it reflects the designs of a large number of clinical studies.
Data Abstraction
Data for evidence tables were abstracted directly onto computer spreadsheets. Information abstracted for assessment of diagnostic performance included the study population characteristics, inclusion and exclusion criteria, the descriptions and the diagnostic criteria for the reference test and the test being evaluated, potential verification bias and test limitations, as well as the main results and the conclusions of the study. For clinical impact, additional information about the clinical outcomes was abstracted. In addition, data for quality assessment of individual studies were systematically abstracted (Appendix A). Reported test performance results, such as the summary sensitivity and specificity values, were verified against the data presented as outcomes using the discharge or final diagnosis. Data were abstracted for each of the technologies in studies that evaluated several tests simultaneously and where data for each test were available independently. Data were abstracted either independently by two members of the EPC staff or by one member and then verified by a second member. Discrepancies of abstracted data between two members were resolved by the EPC director.
Reporting the Results
The evidence we found for the technologies is summarized in three complementary forms. The evidence tables provide detailed information about key features of study design and results of all the studies reviewed. A narrative and tabular summary of the strength and quality of the evidence of each study are provided for each technology. When there was a sufficient number of studies for a specific technology, meta-analysis was performed to provide a quantitative summary of the test performance or clinical impact.
Evidence Tables
For each of the diagnostic technologies, separate evidence tables were constructed for diagnostic test performance and clinical impact studies. These tables are presented under the Evidence Tables section of this evidence report. The evidence tables list the clinical studies found for each of the technologies and that met the inclusion criteria. The specific pieces of information we included in the evidence tables are described above.
Summarizing the Evidence of Individual Studies
Grading of the evidence can be useful by indicating the overall "quality" of studies for a technology. Although a simple evidence grading system using a single metric may be desirable, the "quality" of evidence is multidimensional, and a single metric cannot fully capture information needed to interpret a clinical study (Ioannidis and Lau, 1998; Juni, Witschi, Bloch, et al., 1999; Lijmer, Mol, Heisterkamp, et al., 1999; Lohr and Carey, 1999). We believe that information on individual components of a study contributes more to the evaluation of evidence by deliberating bodies than a single summary score. The evidence-grading scheme we used here assesses the following four dimensions that are important for the proper interpretation of the evidence:
- Size of the study.
- Applicability (patient category and prevalence of disease).
- Diagnostic performance or the magnitude of the clinical impact.
- Internal validity.
Study Size
The study (sample) size is used as a measure of the weight of the evidence. In general, a large study provides a more precise estimate of the treatment effect or test performance. Size alone, however, does not guarantee generalizability. A study that enrolled a large number of selected patients may be less generalizable than several smaller studies that included a broad spectrum of patient populations.
Applicability (population categories)
Applicability, or generalizability or external validity, addresses the issue of whether the study population is sufficiently broad to be generalizable to the population at large. The study population is typically defined by the inclusion and exclusion criteria. We developed four categories based on the included populations in the studies (Figure 2). This categorization provides a simple way to group these diverse studies as well as a way to understand the effect of the diversity of the criteria on test performance or clinical impact.
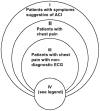
Category I -- studies that included all patients with symptoms and signs suggestive of ACI, such as chest pain, shortness of breath, jaw pain, acute pulmonary edema, and so on. This is the most inclusive category. Few studies met category I criteria.
Category II -- studies that included possible ACI patients with a chief complaint of chest pain. Most studies belong to this group. Category II is a subset of category I.
Category III -- studies that included patients with chest pain but that excluded those with clinical or ECG findings of AMI. Many studies, especially studies of stress cardiac imaging or testing, belong to this group. The subjects in these studies were considered to be at "low risk" for AMI or ACI. Category III is a subset of category II.
Category IV -- studies in which all patients were admitted to the CCU or used additional criteria that enrolled highly selected subpopulations. Category IV may be a subset of category I, II, or III, or it may not be a subset as shown in Figure 2. Retrospective studies fall into this category.
Applicability (disease prevalence)
The prevalence of AMI or ACI is the most objective measure of the similarity of the study populations among the studies. Because different prevalence rates of the diagnoses may reflect the actual enrollment of different distributions of the disease spectrum, varying prevalence rates reported among studies may be related to the variability of reported diagnostic performance and clinical impact results. We recorded this information to assist the interpretation of the results.
Estimates of Diagnostic Test Performance
We used three complementary methods for assessing diagnostic test performance: SROC analysis, independently combined sensitivity and specificity values, and diagnostic odds ratios. Details about these methods are provided in the meta-analysis section later in this chapter.
Estimates of Clinical Impact
Several types of clinical outcomes were reported by the studies. Dichotomous data include overall mortality, number of ACI cases missed, and number of unnecessary hospital or CCU admissions avoided. Continuous data include the mean time to thrombolysis and the mean ejection fractions of intervention and control groups. As was the case for the earlier Working Group report, there is still a paucity of clinical impact studies. When clinical impact information is available, we summarized each of the clinical outcomes independently. Details of these methods are also provided in the meta-analysis section.
Quality Assessment of Internal Validity of Diagnostic Performance Studies
Internal validity refers to the design, conduct, and reporting of the clinical study. Proposals for evaluating the methodological quality of diagnostic test evaluation have been developed (Mulrow, Linn, Gual, et al., 1989; Irwig, Tosteson, Gatsonis, et al., 1994), but they have not been empirically evaluated. A recent article (Lijmer, Mol, Heisterkamp, et al., 1999) found that some of the traditional items of quality (e.g., unmasked interpretation, patient verification) did not have a large influence on the relative diagnostic odds ratio. The results of several other studies that evaluated quality scales also call into question the value of a single quality scale, including scales that may have been "validated" (Juni, Witschi, Bloch, et al., 1999; Clark, Wells, Huet, et al., 1999). Clearly, much more research is needed in quality assessment before a reliable tool becomes available. For the purpose of this evidence report, given the above caveats, we used a three-category scale to provide some indication of the methodological quality of the studies summarized:
Grade A (least bias) -- a study that mostly adheres to the traditionally held concepts of high quality diagnostic evaluation, including: clear description of the population and setting; clear description of the reference standard, the test under investigation, and the diagnostic criteria; masked interpretation of the reference test and the test under investigation; verification of the diagnoses in all or most of the patients with negative results; and no reporting errors that might hide substantial bias.
Grade B (susceptible to some bias) -- a study that does not meet all the criteria in category A. It has some deficiencies but none likely to cause major bias.
Grade C (likely to have significant bias) -- a study with significant design or reporting errors that cannot preclude major bias. This category includes studies in which verification bias could be a large issue and studies that have large amounts of missing information or discrepancies in reporting.
Quality Assessment of Internal Validity of Clinical Impact Studies
The internal validity of clinical impact studies refers to the soundness of the design, conduct, and reporting of the clinical trial. Some of the features of this dimension have been widely used in various "quality" scales, which usually include items such as concealment of random allocation, treatment masking, and the handling of dropouts. Clinical impact studies encountered in our report consist of both randomized trials and nonrandomized prospective studies. In this evidence report, we defined three categories of quality as follows:
Grade A (least bias) -- a controlled clinical trial (randomized or quasi-randomized) with only minor methodological problems and no reporting errors likely to hide substantial bias.
Grade B (susceptible to some bias) -- a well-designed and conducted prospective nonexperimental study design or a controlled trial with some methodological and reporting problems that may hide moderate bias.
Grade C (likely to have large bias) -- a study with major methodological or reporting problems that are likely to hide significant bias. This category includes studies with large amounts of missing information.
Summarizing the Evidence for Each Technology
In addition to the grading of individual studies, we summarized each diagnostic technology. Recent studies suggest that discrete information is more consistent and useful than a single summary score (Juni, Witschi, Bloch, et al., 1999). Therefore, for each technology, we summarized the following dimensions:
- The weight of the evidence, expressed as the total number of studies and patients.
- The applicability of the study results, as determined by the range of populations studied and by the prevalence of ACI.
- The methodological quality (internal validity) of the individual studies.
The number of studies and the number of patients included in each study are summarized for each technology to provide a sense of the quantity of evidence available to assess a technology. The applicability of the studies to the ED setting is assessed by the range of study population categories represented and by the prevalence of ACI or AMI reported by the individual studies. When meta-analyses of diagnostic performance and clinical impact were performed, the overall estimates are reported. If meta-analyses were not possible, the range of results reported by the individual studies is provided. The composite study methodological quality is derived using the following rule: The quality score of the majority of the studies providing the evidence, taking into account the study size as well, is used to determine the overall quality of evidence for the technology examined. We acknowledge that this grading is arbitrary, but given the recent publications on the issues with quality scoring, it is unclear whether there is a more reliable method.
Presentation of Results for Each of the Technologies
In Chapter 3, the evidence for each of the technologies is presented in the format described below. We followed the structure of the NHAAP Working Group report and presented results of the prospective studies on test performance, then studies of clinical impact, and then data from other studies (such as those conducted in the CCU). When results are available, appropriate summary tables are included in each section. The summary table is preceded by a narrative description of the included studies. The tables list the qualifying studies, the number of patients, the study population category (as defined earlier), the prevalence of AMI or ACI in each study, the test performance (sensitivity and specificity) or clinical impact, and the methodological quality of the study. The overall results of test performance or clinical impact derived from meta-analyses are also shown. Data used for specific meta-analyses are described in the meta-analysis section of the evidence report. Studies conducted in other settings (e.g., the CCU) are described and summarized in the Data From Other Clinical Studies section.
Supplemental Analyses
Meta-analyses were performed to quantify the diagnostic performance and clinical impact of several diagnostic technologies where the data were sufficient. A decision and cost-effectiveness analysis was performed to compare the cost and effectiveness of each technology.
Meta-Analysis
Diagnostic Test Performance
We used three different methods to summarize the test performance of the diagnostic technologies: SROC curve analysis, separately averaged sensitivity and specificity values across studies, and the diagnostic odds ratio.
The SROC method assumes that the variability in the reported sensitivity and specificity values from different studies is due to different cutoff values being applied (Moses, Shapiro, and Littenberg, 1993). Each study provides a pair of sensitivity and specificity values to the analysis. It uses a regression method to fit a curve that best describes the data in the ROC space. We used the unweighted SROC method because it is probably less biased than the weighted regression method (Irwig, MacAskill, Glasziou, et al., 1995). If multiple thresholds are available for individual diagnostic test studies, ROC curves can be constructed and the areas under the curves can be estimated. The area under the curve provides an assessment of the overall accuracy of the test and allows comparisons with other tests. However, few studies provided results using multiple cutpoints.
The areas under different SROC curves can also be calculated and compared across technologies. However, the range of sensitivity and specificity values from studies in a meta-analysis of diagnostic tests is often limited, and extrapolation of the SROC analysis beyond the values of actual data is not reliable. For example, the specificity values reported by the CK-MB studies are typically between 90 and 100 percent. Thus, the SROC curve that can be constructed with actual data is limited to about the first 10 percent of the SROC space, and extrapolating the SROC curve to the entire SROC space to calculate the area under the curve would not be reasonable. Most of the technologies we examined have narrow reported ranges of sensitivity or specificity values. Therefore, we did not calculate the area under the SROC curve for any of the technologies.
When there is little variability in the test results -- studies appeared to be operating at similar thresholds and reported similar results -- SROC analysis provided little additional information. In this case, separately averaged sensitivity and specificity values across studies will give similarly useful summary information.
We combined the sensitivity and specificity values of the tests across studies using a random effects model to estimate the average values. A random effects model incorporates both the within-study variation (sampling error) and between-study variation (true treatment-effect differences) into the overall treatment estimate. It gives a wider confidence interval than the fixed effects model (which considers only within-study variability) when estimates are based on heterogeneous results.
When each is combined separately, sensitivity and specificity tend to underestimate the true test sensitivity and specificity. They are nonetheless useful estimates of the average test performance and provide an indication of the approximate test operating point for most of the studies. The appropriateness of this method can be verified by inspecting the location of the combined estimates and noting the distance of the estimates from the SROC curve. In our experience, the random effects-averaged sensitivity and specificity results are close to the unweighted SROC curve and well within the confidence intervals of each other. Average sensitivity and specificity results also serve as useful baseline test performance values for the decision and cost-effectiveness analysis.
The diagnostic odds ratio for a diagnostic test is defined as: [sensitivity/(1 - sensitivity)/(1 - specificity)/specificity] (Irwig, MacAskill, Glasziou, et al., 1995). A high diagnostic odds ratio typically has either a high sensitivity or a high specificity value, or both. The higher the odds ratio, in general, the greater the test accuracy. The summary diagnostic odds ratio obtained by combining the odds ratios of individual studies using a random effects model can provide a single summary value that is useful (with other summary information about the test) for comparing technologies. The diagnostic odds ratio is equivalent to the intercept coefficient of the SROC method assuming a zero slope.
Statistical analyses using the SROC curve method and combining sensitivity and specificity using the random effects model was performed using "Meta-Test" version 0.6. Summary diagnostic odds ratios were calculated using "Meta-Analyst" version 0.991. Both of these computer programs were developed by the EPC director (Dr. Lau) and are available to the public. Where necessary, statistical analysis algorithms implemented in MathCAD 7.0™ were also used. We report 95 percent confidence intervals (CIs) along with all estimates.
Clinical Impact Studies
Studies included in meta-analyses of clinical impact outcomes were combined using a random effects model (Laird and Mosteller, 1990). The risk ratio of the outcome was used to combine dichotomous outcome data, such as mortality. A random effects model was also used to combine continuous outcomes, such as differences in the mean time to thrombolysis. Summary risk ratios were calculated using "Meta-Analyst" version 0.991. Continuous outcomes were combined using the random effects model implemented in MathCAD 7.0.™ We report 95 percent CIs with all estimates.
Decision and Cost-Effectiveness Analysis
A decision and cost-effectiveness analysis was conducted to examine the tradeoff between test performance and their costs. Details of these analyses are presented in the decision analysis section in this evidence report. Again, we recognized the difficulties and limitations of such analyses for a clinical situation as complex as diagnosing ACI in the ED. These analyses should be viewed not for the purpose of making specific clinical recommendations but for understanding the interactions among the variables studied.
- Methods - Evaluation of Technologies for Identifying Acute Cardiac Ischemia in E...Methods - Evaluation of Technologies for Identifying Acute Cardiac Ischemia in Emergency Departments
Your browsing activity is empty.
Activity recording is turned off.
See more...