

NCBI Bookshelf. A service of the National Library of Medicine, National Institutes of Health.
West S, King V, Carey TS, et al. Systems to Rate the Strength Of Scientific Evidence. Rockville (MD): Agency for Healthcare Research and Quality (US); 2002 Apr. (Evidence Reports/Technology Assessments, No. 47.)
This publication is provided for historical reference only and the information may be out of date.

This project had numerous distinct tasks. We first solicited input and data from the Agency for Healthcare Research and Quality (AHRQ), its 12 Evidence-based Practice Centers (EPCs), and a group of international experts in this field. We then conducted an extensive literature search on relevant topics. From this information, we created tables to document important variables for rating and grading systems and matrices (hereafter denoted grids) to describe existing systems in terms of those variables. After analyzing and synthesizing all these data, we prepared this final report, which is intended to be appropriate for AHRQ to use in responding to the request from the Congress of the United States and in more broadly disseminating information about these systems and their uses in systematic reviews, evidence reports, and technology assessments.
As explained in Chapter 1, our ultimate goal was to create an integrated set of grids by which to describe and evaluate approaches and instruments for rating the quality of individual articles (referred to hereafter as Grids 1-4) and for grading the overall strength of a body of evidence (Grid 5). Here, we outline the project's overall methods, focusing on explicating the final set of grids. The completed grids can be found in Appendix B (Grids 1-4) and Appendix C (Grid 5).
Solicitation of Input and Data
Early in the project, we conducted a conference call with AHRQ to clarify outstanding questions about the project and to obtain additional background information. Enlisting the assistance and support of the other EPCs was a critical element of the effort. EPC directors or their designates participated in a second conference call in which we gave an overview of the project and discussed the information and documents we would need from them. We devised forms by which the EPCs could identify the methods they had used for rating the quality of the studies and grading the strength of the evidence in their AHRQ work or in similar activities for other sponsors (see Appendix A).
In addition, 10 experts served as a "technical expert advisory group" (TEAG; see Acknowledgments). We communicated with the TEAG through conference calls, occasional individual calls, and e-mail. Of particular importance were the TEAG members' efforts to clarify the conceptual model for the project, their identification of empirical work on study quality, and their review and critique of the grid structure. Eventually, several TEAG members also provided detailed reviews of a draft of this report.
Literature Search
Preliminary Steps
We carried out a multi-part effort to identify rating and grading systems and literature relevant to this question in several ways. First, we resurrected all documents acquired or generated in the original "grading project," including literature citations or other materials provided by the EPCs. 1 Second, as described in more detail below, we designed a supplemental literature search to identify articles that focused on generic instruments published in English (chiefly from 1995 through mid-2000). Third, we used information from the EPC directors documenting the rating scales and classification systems that they have used in evidence reports or other projects for AHRQ or other sponsors. Fourth, we examined rating schemes or similar materials forwarded by TEAG members.
In addition, we tracked activities of several other groups engaged in examining these same questions. These include The Cochrane Collaboration Methods Group (especially work on assessing observational studies), the third (current) U.S. Preventive Services Task Force, and the Scottish Intercollegiate Guidelines Network (SIGN).
Finally, we reviewed the following international web sites for groups
involved in evidence-based medicine or guideline development:
Canadian Task Force on Preventive Health Care (Canada), http://www.ctfphc.org/.
Centre for Evidence Based
Medicine, Oxford University (U.K.), http://cebm.jr2.ox.ac.uk/;
National Coordination Centre
for Health Technology Assessment (U.K.), http://www.ncchta.org/main.htm;
National Health and
Medical Research Council (Australia), http://www.nhmrc.health.gov.au/index.htm;
New
Zealand Guidelines Group (New Zealand), http://www.nzgg.org.nz/;
and
National Health Service (NHS) Centre for Reviews and
Dissemination (U.K.), http://www.york.ac.uk/inst/crd/;
Scottish
Intercollegiate Guidelines Network (SIGN) (U.K.), http://www.sign.ac.uk/;
The Cochrane Collaboration
(international), http://www.cochrane.org/;
Searches
We searched the MEDLINE® database for relevant articles published between 1995 and mid-2000 using the Medical Subject Heading (MeSH) terms shown in Tables 2 and 3 for Grids 1-4 (on rating the quality of individual studies) and Grid 5 (on grading a body of scientific evidence), respectively. For the Grid 5 search, we also had to use text words (indicated by an ".mp.") to make the search as inclusive as possible.
We compiled the results from all searches into a ProCite® bibliographic database, removing all duplicate records. We also used this bibliographic software to tag eligible articles and, for articles determined to be ineligible, to note the reason for their exclusion.
Title and Abstract Review
The initial search for articles on systems for assessing study quality (Grids 1-4) generated 704 articles (Table 2). The search on strength of evidence (Grid 5) identified 679 papers (Table 3).
Table
Table 2. Systematic Search Strategy to Identify Instruments for Assessing Study Quality.
Table
Table 3. Systematic Search Strategy to Identify Systems for Grading the Strength of a Body of Evidence.
We developed a coding system for categorizing these publications (Table 4) through two independent reviews of the abstracts from the first 100 articles from each search with consensus discussions as to whether each article should be included or excluded from full review. When abstracts were not available from the literature databases, we obtained them from the original article. The Project Director and the Scientific Director then independently evaluated the remaining titles and abstracts for the 604 articles (704 minus the 100 for coding system development) for Grids 1-4 and the 579 articles (679 minus the 100 for coding system development) for Grid 5. Any disagreements were negotiated, erring on the side of inclusion as the most conservative approach.
Table
Table 4. Coding System Applied at the Abstract Stage for Articles Identified During the Focused Literature Search for Study Quality Grid and for Strength of Evidence Grid.
We identified an additional 219 publications from various sources other than the formal searches, including the previous project, 1 bibliographies of seminal articles, suggestions from TEAG members, and searches of the web pages of groups working on similar issues (listed above). In all, we reviewed the abstracts for a total of 1,602 publications for the project; after review of all retained articles, we retained 109 that dealt with systems (i.e., scales, checklists, or other types of instruments or guidance documents) that were included in one or more of the grids and 12 EPC systems, for a total of 121 systems. The two-stage selection process that yielded these 121 systems is available from the authors on request.
Development of Study Quality Grids
Number and Structure of Grids
We developed the four Study Quality Grids (Appendix B) to account for four different study designs -- systematic reviews and meta-analyses, randomized controlled trials (RCTs), observational studies, and diagnostic studies.
Each Study Quality Grid has two parts. The first depicts the quality constructs and domains that each rated instrument covers; the other describes the instrument in various ways. For both Grids 1-4 (and Grid 5), columns denote evaluation domains of interest, and the rows are the individual systems, checklists, scales, or instruments. Taking these parts together, the grids form "evidence tables" that document the characteristics (strengths and weaknesses) of these different systems.
Overview of Grid Development
Preliminary Steps
Previous work done by the RTI-UNC EPC had identified constructs believed to affect the quality of studies (Table 5). 1 Beginning with these constructs and an annotated bibliography of scales and checklists for assessing the quality of RCTs,101,107 we examined several of the more comprehensive systems of assessing study quality to settle on appropriate domains to use in the grids. These included approaches from groups such as the New Zealand Guidelines Group, 13 The Cochrane Collaboration, 11 the NHS Centre for Reviews and Dissemination, 85 and SIGN. 14 After three rounds of design, review, and testing, we settled on the domains and elements outlined in tables discussed below.
Table
Table 5. Study Constructs Believed to Affect Quality of Studies.
In addition to abstracting and assessing the content of quality rating instruments and systems, we gathered information on seven descriptive items for each article (Table 6). Definitions of key terms used in Table 6 appear in the glossary (Appendix G). These items, which were identical for all four study types, cover the following characteristics:
- Whether the instrument was designed to be generic or specific to a given clinical topic;
- The type of instrument (a scale, a checklist, or a guidance document);
- Whether the instrument developers defined quality;
- What method the instrument developers used to select items in the instrument;
- The rigor of the development process for this instrument;
- Inter-rater reliability; and
- Whether the developers had provided instructions for use of the instrument.
Table
Table 6. Items Used to Describe Instruments to Assess Study Quality.
Domains and Elements for Evaluating Instruments to Rate Quality of Studies
A "domain" of study methodology or execution reflects factors to be considered in assessing the extent to which the study's results are reliable or valid (i.e., study quality). Each domain has specific "elements" that one might use in determining whether a particular instrument assessed that domain; in some cases, only one element defines a domain. Tables 7-10 define domains and elements for the grids relevant to rating study quality. Although searching exhaustively for and cataloging evidence about key study design features and the risk of bias were steps beyond the scope of the present project, we present in Appendix D a reasonably comprehensive annotated bibliography of studies that relate methodology and study conduct to quality and risk of bias.
By definition, we considered all domains relevant for assessing study quality, but we made some distinctions among them. The majority of domains and their elements are based on generally accepted criteria -- that is, they are based on standard "good practice" epidemiologic methods for that particular study design. Some domains have elements with a demonstrable basis in empirical research; these are designated in Tables 7-10 by italics, and we generally placed more weight on domains that had at least one empirically based element.
Empirical studies exploring the relationship between design features and risk of bias have often considered only certain types of studies (e.g., RCTs or systematic reviews), particular types of medical problems (e.g., pain or pregnancy), or particular types of treatments (e.g., antithrombotic therapy or acupuncture). Not infrequently, evidence from multiple studies of the "same" design factor (e.g., reviewer masking) comes to contradictory conclusions. Nevertheless, in the absence of definitive universal findings that can be applied to all study designs, medical problems, and interventions, we assumed that, when empirical evidence of bias exists for one particular medical problem or intervention, we should consider it in assessing study quality until further research evidence refutes it.
For example, we included a domain on funding and sponsorship of systematic reviews based on empirical work that indicates that studies conducted with affiliation to or sponsorship from the tobacco industry 3 or pharmaceutical manufacturers 110 may have substantial biases. We judged this to be sufficient evidence to designate this domain as empirically derived. However, we are cognizant that when investigators have strongly held positions, whether they be financially motivated or not, biased studies may be published and results of studies contrary to their positions may not be published. The key concepts are whether bias is likely to exist, how extensive such potential bias might be, and the likely effect of such bias on the results and conclusions of the study.
Although some domains have only a single element, others have several. To be able to determine whether a given instrument covered that domain, we identified elements that we considered "essential." Essential elements are those that a given instrument had to include before we would rate that instrument as having fully covered that domain. In Tables 7-10, these elements are presented in bold.
Finally, for domains with multiple elements, we specified the elements that the instrument had to consider before we would judge that the instrument had dealt adequately with that domain. This specification involved either specific elements or, in some cases, a count (a simple majority) of the elements.
Defining Domains and Elements For Study Quality Grids
Systematic Reviews and Meta-Analyses (Grid 1)
Table 7 defines the 11 quality domains and elements appropriate for systematic reviews and meta-analyses; these domains constitute the columns for Grid 1 in Appendix B. The domains are study question, search strategy, inclusion and exclusion criteria, interventions, outcomes, data extraction, study quality and validity, data synthesis and analysis, results, discussion, and funding or sponsorship. Search strategy, study quality and validity, data synthesis and analysis, and funding or sponsorship have at least one empirically based element. The remaining domains are generally accepted criteria used by most experts in the field, and they apply most directly to systematic reviews of RCTs.
Table
Table 7. Domains and Elements for Systematic Reviews.
Randomized Controlled Trials (Grid 2)
Table 8 presents the 10 quality domains for RCTs: study question, study population, randomization, blinding, interventions, outcomes, statistical analysis, results, discussion, and funding or sponsorship. Of these domains, four have one or more empirically supported elements: randomization, blinding, statistical analysis, and funding or sponsorship. Every domain has at least one essential element.
Table
Table 8. Domains and Elements for Randomized Controlled Trials.
Observational Studies (Grid 3)
In observational studies, some factor other than randomization determines treatment assignment or exposure (see Figure 1 in Chapter 1 for clarification of the major types of observational studies). The two major types of observational studies are cohort and case-control studies. In a cohort study, a group is assembled and followed forward in time to evaluate an outcome of interest. The starting point for the follow-up may occur back in time (retrospective cohort) or at the present time (prospective cohort). In either situation, participants are followed to determine whether they develop the outcome of interest. Conversely, for a case-control study, the outcome itself is the basis for selection into the study. Previous interventions or exposures are then evaluated for possible association with the outcome of interest.
In all observational studies, selection of an appropriate comparison group of people without either the intervention/exposure or the outcome of interest is generally the most important and the most difficult design issue. Ensuring the comparability of the treatment groups in a study is what makes the RCT such a powerful research design. Observational studies are generally considered more liable to bias than RCTs, but certain questions can be answered only by using observational studies.
All nine domains and most of the elements for each domain apply generically to both cohort and case-control studies (Table 9). The domains are as follows: study question, study population, comparability of subjects, definition and measurement of the exposure or intervention, definition and measurement of outcomes, statistical analysis, results, discussion, and funding or sponsorship. Certain elements in the comparability-of-subjects domain are unique to case-control designs.
Table
Table 9. Domains and Elements for Observational Studies.
There are two empirically based elements for observational studies, use of concurrent controls and funding or sponsorship. However, a substantial body of accepted "best practices" exists with respect to design and conduct of observational studies, and we identified seven elements as essential.
Diagnostic Studies (Grid 4)
Assessment of diagnostic study quality is a topic of active current research. 78 We based the five domains in Table 10 for this grid on the work of the STARD (STAndards for Reporting Diagnostic Accuracy) group. The domains are study population, test description, appropriate reference standard, blinded comparison, and avoidance of verification bias. We designated five elements in Table 10 as essential, all of which are empirically derived.
Table
Table 10. Domains and Elements for Diagnostic Studies.
The domains for diagnostic tests are designed to be used with the domains (and grids) for RCTs or observational studies because these are the basic study designs used to evaluate diagnostic tests. The domains for diagnostic tests can, in theory, also be applied to questions involving screening tests.
Assessing and Describing Quality Rating Instruments
Evaluating Systems According to Key Domains and Elements
To describe and evaluate systems for rating the quality of individual
studies (Grids
1-4),
we applied a tripartite evaluation scheme for the domains just
described. Specifically, in the first part of each grid in Appendix B, we indicate with
closed or partially closed circles whether the instrument fully or
partially covered (respectively) the domain in question; an open circle
denotes that the instrument did not deal with that domain. In the
discussion that follows and in Chapter
3, we use the shorthand of "Yes," "Partial," and No" to
convey these evaluations; in the grids they are shown as  ,
, 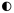 ,
,  , respectively.
, respectively.
Yes evaluations mean that the instrument considered all or most of the elements for that domain and that it did not omit any element we defined as essential. A Partial rating meant that some elements in the domain were present but that at least one essential element was missing for that domain. No indicated that the instrument included few if any of the elements for a particular domain and that it did not assess any essential element.
Describing System Characteristics
Table 6 listed and defined the descriptive items that appear in the second part of each quality grid. We often had to infer certain pieces of information from the publications, as not all articles specified these descriptors directly. To say that a system had been "rigorously developed," we determined whether the authors indicated that they used typical instrument development techniques. We gave a Partial rating to systems that used some type of consensus panel approach for development.
Development of Evidence Strength Grid
The Strength of Evidence Grid (Grid 5, Appendix C) describes generic schemes for grading the strength of entire bodies of scientific knowledge -- that is, more than one study evaluating the same or a similar relationship or clinical question about a health intervention or technology -- rather than simply assessing the quality of individual articles. As discussed elsewhere, we have attempted to use criteria relevant to assessing a body of evidence without incorporating factors that are intended primarily to formulate, characterize, and support formal recommendations and clinical practice guidelines.
We defined three domains for rating the overall strength of evidence: quality, quantity, and consistency (Table 11). As with the Study Quality Grids, we have two versions. Grid 5A summarizes the more descriptive information from Grid 5B. In Grid 5A, we assigned a rating of Yes, Partial, or No (and applied the same symbols), depending on the extent to which the grading system incorporated elements of quality, quantity, and consistency.
Table
Table 11. Domains for Rating the Overall Strength of a Body of Evidence.
Quality
Overall quality of a body of scientific studies is influenced by all the factors mentioned in our discussion of the quality of individual studies above. Grading systems that considered at least two of the following criteria -- study design, conduct, analysis, or methodologic rigor -- merited a Yes on quality. Systems that based their evidence grading on the hierarchy of research design without mention of methodologic rigor received a Partial rating.
Quantity
We use the construct "quantity" to refer to the extent to which there is a relationship between the technology (or exposure) being evaluated and outcome as well as to the amount of information supporting that relationship. Three main factors contribute to quantity:
- The magnitude of effect (i.e., estimated effects such as mean differences, odds ratio, relative risk, or other comparative measure);
- The number of studies performed on the topic in question (e.g., only a few versus perhaps a dozen or more); and
- The number of individuals studied, aggregated over all the relevant and comparable investigations, which provides the width of the confidence limits for the effect estimates.
The magnitude of effect is evaluated both within individual studies and across studies, with a larger effect indicative of a stronger relationship between the technology (or exposure) under consideration and the outcome. The finding that patients receiving a treatment are 5 times more likely to recover from an illness than those who do not receive the treatment is considered stronger evidence of efficacy than a finding that patients receiving a treatment are 1.3 times more likely to recover. However, absent any form of systematic bias or error in study design, and assuming equally narrow confidence intervals, there is no reason to consider this assertion (i.e., that the former is stronger evidence) to be the case. Rather, this illustrates the fact that one is simply measuring different sizes (magnitudes) of treatment effect. Nevertheless, no study is free from some element of potential unmeasured bias. The impact of such bias can overestimate or underestimate the treatment effect. Therefore, a large treatment effect partially protects an investigation against the threat that such bias will undermine the study's findings.
With respect to numbers of studies and individuals studied, common sense suggests that the greater the number of studies (assuming they are of good quality), the more confident analysts can be of the robustness of the body of evidence. Thus, we assume that systems for grading bodies of evidence ought to take account of the sheer size of that body of evidence.
Moreover, apart from the number of studies per se is the aggregate size of the samples included in those studies. All other things equal, a larger total number of patients studied can be expected to provide more solid evidence on the clinical or health technology question than a smaller number of patients. The line of reasoning is that hundreds (or thousands) of individuals included in numerous studies that evaluate the same issue give decisionmakers reason to believe that that the topic has been thoroughly researched. In technical terms, the power of the studies to detect both statistically and clinically significant differences is enhanced when the size of the patient populations studied is larger.
However, a small improvement or difference between study patients and controls or comparisons must still be considered in light of the potential public health implications of the association under study. A minimal net benefit for study patients relative to comparison may seem insignificant except if it applies to very large numbers of individuals or can be projected to yield meaningful savings in health care costs. Thus, when using magnitude of an effect for judging the strength of a body of evidence, one must consider the size of the population that may be affected by the finding in addition to the effect size and whether it is statistically significant. Magnitude of effect interacts with number and aggregate size of the study groups to affect the confidence analysts can have in how well a health technology or procedure will perform. In technical terms, summary effect measures calculated from studies with many individuals will have narrower confidence limits than effect measures developed from smaller studies. Narrower confidence limits are desirable because they indicate that relatively little uncertainty attends the computed effect measure. In other words: a 95-percent confidence interval indicates that decisionmakers and clinicians can, with comfort, believe that 95 percent of the time the confidence interval will include (or cover) the true effect size.
A Yes for quantity meant that the system incorporated at least two of the three elements listed above. For example, if a system considered both the magnitude of effect and a measure of its precision (i.e., the width of the confidence intervals around that effect, which as noted is related to size of the studies), we assigned it a Yes. Rating systems that considered only one of these three elements merited a grade of Partial.
Consistency
Consistency is the degree to which a body of scientific evidence is in agreement with itself and with outside information. More specifically, a body of evidence is said to be consistent when numerous studies done in different populations using different study designs to measure the same relationship produce essentially similar or compatible results. This essentially means that the studies have produced reasonably reproducible results. In addition, consistency addresses whether a body of evidence agrees with externally available information about the natural history of disease in patient populations or about the performance of other or related health interventions and technologies. For example, information about older drugs can predict reactions to newer entities that have related chemical structures, and animal studies of a new drug can be used to predict similar outcomes in humans.
For evaluating schemes for grading strength of evidence, we treated the construct of consistency as a dichotomous variable. That is, we gave the instrument a Yes rating if it considered the concept of consistency and a No if it did not. No Partial score was given. Consistency is related to the concept of generalizability, but the two ideas differ in important ways. Generalizability (sometimes referred to as external validity) is the extent to which the results of studies conducted in particular populations or settings can be applied to different populations or settings. An intervention that is seen to work across varied populations and settings not only shows strong consistency but is likely to be generalizable as well. However, we chose to use consistency rather than generalizability in this work because we considered generalizability to be more pertinent to the further development of clinical practice guidelines (as indicated in Figure 2, Chapter 1). That is, generalizability asks the question "Do the results of this study apply to my patient or my practice?" Thus, in assessing the strength of a body of literature, we de-emphasized the population perspective because of its link to guideline development and, instead, focused on the reproducibility of the results across studies.
Abstraction of Data
To abstract data on systems for grading articles or rating strength of evidence, we created an electronic data abstraction tool that could be used either in paper form (Appendix F) or as direct data entry. Two persons (Project Director, Scientific Director) independently reviewed all the quality rating studies, compared their abstractions, and adjudicated disagreements by discussion, additional review of disputed articles, and referral to another member of the study team as needed. For the strength of evidence work, the two principal reviewers each entered approximately half of the studies directly onto a template of the grid (Grid 5) and then checked each other's abstractions; again, disagreements were settled by discussion or additional review of the article(s) in question.
Preparation of Final Report
The authors of this report prepared two earlier versions. A partial "interim report" was submitted to AHRQ in the fall of 2000 for internal Agency use. More important, a draft final report was completed and submitted for wide external review early in 2001. A total of 22 experts and interested parties participated in this review; they included some members of the TEAG and additional experts invited by the RTI-UNC EPC team to serve in this capacity (see Acknowledgments) as well as several members of the AHRQ staff. This final report reflects substantive and editorial comments from this external peer review.
- Methods - Systems to Rate the Strength Of Scientific EvidenceMethods - Systems to Rate the Strength Of Scientific Evidence
- Focal segmental glomerulosclerosis 6Focal segmental glomerulosclerosis 6MedGen
Your browsing activity is empty.
Activity recording is turned off.
See more...