

NCBI Bookshelf. A service of the National Library of Medicine, National Institutes of Health.
Balk EM, Moorthy D, Obadan NO, et al. Diagnosis and Treatment of Obstructive Sleep Apnea in Adults [Internet]. Rockville (MD): Agency for Healthcare Research and Quality (US); 2011 Jul. (Comparative Effectiveness Reviews, No. 32.)
This publication is provided for historical reference only and the information may be out of date.

The present Comparative Effectiveness Review (CER) evaluates various diagnostic and treatment modalities for the management of obstructive sleep apnea (OSA). The Tufts Evidence-based Practice Center (Tufts EPC) reviewed the existing body of evidence on the relative benefits and possible harms of different interventions used to diagnose and treat OSA. The comparisons are based on a systematic review of the published scientific literature using established methodologies as outlined in the Agency for Healthcare Research and Quality’s (AHRQ) Methods Guide for Comparative Effectiveness Reviews (Agency for Healthcare Research and Quality. Methods Guide for Comparative Effectiveness Reviews [posted November 2008]. Rockville, MD.), which is available at: http://effectivehealthcare.ahrq.gov/healthInfo.cfm?infotype=rr&ProcessID=60.
AHRQ Task Order Officer
The Task Order Officer (TOO) was responsible for overseeing all aspects of this project. The TOO facilitated a common understanding among all parties involved in the project, resolved ambiguities, and fielded all Tufts EPC queries regarding the scope and processes of the project. The TOO and other staff at AHRQ reviewed the report for consistency, clarity, and to ensure that it conforms to AHRQ standards.
External Expert Input
During a topic refinement phase, the initial questions were refined with input from a panel of Key Informants. Key Informants included experts in sleep medicine, general internal medicine and psychiatry, a representative from Oregon Division of Medical Assistance programs, an individual with OSA, a representative of a sleep apnea advocacy group, and the assigned TOO. After a public review of the proposed Key Questions, the clinical experts among the Key Informants were reconvened to form the TEP, which served to provide clinical and methodological expertise and input to help refine Key Questions, identify important issues, and define parameters for the review of evidence. Discussions among the Tufts EPC, TOO, and Key Informants, and, subsequently the TEP occurred during a series of teleconferences and via email. In addition, input from the TEP was sought during compilation of the report when questions arose about the scope of the review. See Preface for the list of Key Informants and members of the TEP, and title page for our local domain expert.
Key Questions
Key Questions, developed and refined in cooperation with the Key Informants and TEP, take into account the patient populations, interventions, comparators, outcomes, and study designs (PICOD) that are clinically relevant for diagnosis and treatment of OSA. Seven Key Questions are addressed in the present report. Three pertain to screening for and diagnosis of OSA (Key Questions 1–3), two address the comparative effectiveness of treatments for OSA (Key Questions 5 & 7), and two address associations between baseline patient characteristics and long-term outcomes and treatment compliance (Key Questions 4 & 6). The Key Questions are listed at the end of the Introduction.
Analytic Framework
To guide the development of the Key Questions for the diagnosis and treatment of OSA, we developed an analytic framework (Figure 1) that maps the specific linkages associating the populations and subgroups of interest, the interventions (for both diagnosis and treatment), and outcomes of interest (intermediate outcomes, health-related outcomes, compliance, and adverse effects). Specifically, this analytic framework depicts the chain of logic that evidence must support to link the interventions to improved health outcomes.
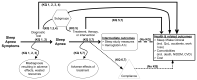
Figure 1
Analytic framework for the diagnosis and treatment of obstructive sleep apnea in adults. CVD = cardiovascular disease, KQ = Key Question, NIDDM = non-insulin-dependent diabetes mellitus, QoL = quality of life.
Literature Search
We conducted literature searches of studies in MEDLINE® (inception—September 2010) and both the Cochrane Central Trials Registry®, and Cochrane Database of Systematic Reviews® (through 3rd Quarter, 2010). All English language studies with adult human subjects were screened to identify articles relevant to each Key Question. The reference lists of related systematic reviews as well as selected narrative reviews and primary articles were also reviewed for relevant studies. Our search included terms for OSA, sleep apnea diagnostic tests, sleep apnea treatments, and relevant research designs (see Appendix A for complete search strings). In addition, with input from the TEP, a separate search was conducted for cohort studies addressing Key Question 4 (the assessment of the relationship between sleep indices or patient characteristics with outcomes) and Key Question 6 (associations of pretreatment patient-level characteristics with treatment compliance in nonsurgical treatments). This additional search was also conducted through September 2010. TEP members were also invited to provide additional citations. All articles suggested by TEP members were screened for eligibility using the same criteria as for the original articles. The consensus of the TEP was not to include unpublished data, based primarily on the balance between the large volume of trial data and limited time and resources.
The literature search was supplemented by solicited Scientific Information Packets. A sister organization, also under contract with AHRQ, solicited industry stakeholders, professional societies, and other interested researchers for research relevant to the Key Questions. A Web site was also available for anyone to upload information. Studies from this source were screened using the same eligibility criteria as for the primary search.
Study Selection and Eligibility Criteria
The Tufts EPC has developed a computerized screening program, Abstrackr, to automate the screening of abstracts to include eligible articles for full-text screening.56 The program uses an active learning algorithm to screen for articles most relevant to the Key Questions. Relevance was established by manually double-screening 1,000 abstracts to train the program. Subsequently, abstracts selected by the program were screened by one researcher. The results of each group of abstracts that were manually screened (and classified as accept or reject) were iteratively fed into the program for further training prior to generation of the next group of abstracts to be manually screened. This process continued until the program was left with only abstracts it rejected. Using Abstrackr, we reduced by 50 percent the number of abstracts we needed to manually screen prior to starting the subsequent steps of the systematic review. While the review was subsequently being conducted, all abstracts rejected by the program were also manually screened. (All abstracts rejected by Abstrackr were also rejected by manual screening.) Full-text articles were retrieved for all potentially relevant articles. These were rescreened for eligibility. The reasons for excluding these articles were tabulated in Appendix B.
Eligible studies were further segregated using the following selection criteria: population and condition of interest; interventions, predictors, and comparators of interest; outcomes of interest; study designs; and duration of followup. Of note, where interventions are not discussed (either diagnostic tests or treatments), this does not imply that the interventions were excluded from analysis (unless explicitly stated); instead, no studies of these interventions met eligibility criteria.
Population and Condition of Interest
We included studies conducted only in adults (>16 years). By consensus with the TEP, we excluded studies in which more than 20 percent of the participants had neuromuscular disease, Down syndrome, Prader-Willi syndrome, major congenital skeletal abnormalities, narcolepsy, narcotic addiction, Alzheimer’s disease, epilepsy, or who had experienced a disabling stroke. This threshold (20 percent) was chosen arbitrarily to avoid excluding potentially relevant small studies that included some patients with conditions not of interest to the current report. This turned out to be a moot point since no eligible studies explicitly included patients with any of these conditions.
Diagnostic testing (Key Questions 1 & 2). We included studies of adults with symptoms, findings, history, and comorbidities that indicated an increased risk of sleep apnea. Studies conducted in only asymptomatic or healthy general-population participants, as well as those in patients with known sleep apnea, were excluded.
Preoperative screening (Key Question 3). We included studies of all preoperative patients, irrespective of the surgery to be performed, as long as they were scheduled to receive general anesthesia. We excluded studies in which all patients were known to have sleep apnea. There were no other restrictions based on patient symptoms or existing diagnoses.
Predictors of long-term outcomes (Key Question 4). We included studies of adults, regardless of health status, who had a baseline sleep study performed for any reason.
Treatment of OSA (Key Question 5) and treatment compliance (Key Questions 6 & 7). We included studies of adults with a confirmed diagnosis of OSA, whether associated with symptoms or not, and with formal sleep study testing demonstrating an apnea-hypopnea index (AHI) ≥5 events/hr. We excluded studies with >20 percent of study subjects without OSA, unless a subgroup analysis of OSA patients was reported. This restriction included patients with central sleep apnea or snoring without OSA.
Interventions, Predictors, and Comparators of Interest
Diagnostic testing (Key Question 1). We evaluated two types of comparisons: portable monitoring devices (used at home or setting other than a sleep laboratory) versus facility-based polysomnography (PSG); and questionnaires or prediction models versus PSG or portable monitors. Generally, portable devices (and PSG) are categorized by the number and type of “channels” measured. Each channel separately monitors and measures indicators of the physiological status of organs. Combinations of these channels are used in different types of devices for the diagnosis of sleep apnea. For example, a sleep-facility-based PSG includes at least the following channels: electroencephalography, electrooculography, electromyography, heart rate or electrocardiography (ECG), airflow, breathing/respiratory effort, and arterial oxygen saturation. Some portable devices have four monitored channels with at least two channels measuring respiratory movement, or one measuring respiratory movement combined with a channel measuring airflow, in addition to heart rate or ECG, and oxygen saturation. Other portable devices measure one, two, or three physiological indicators.
We followed the construct of our 2007 technology assessment on PSG.26 With the TEP, we came to agreement that PSG is an accurate measure of AHI and other (obstructive and nonobstructive) apnea measures, but is not a definitive test for OSA (syndrome) since the definition of the syndrome includes clinical judgment and arbitrary thresholds.
We excluded studies with verification bias in which not everyone had PSG as the comparator.
We included all portable devices with any combination of two or more channels and those that measured the following single channels: pulse transit time, peripheral arterial tone, and pulse oximetry. We excluded studies on devices that used other single channel tests, specifically those that measured only heart rate, heart rate variability, or actigraphy alone. For the first analysis (portable versus PSG) we included only studies that performed an overnight PSG.
For the second analysis (questionnaires, etc. versus standard testing), we included studies that evaluated screening and other questionnaires, scales that included clinical criteria (e.g., signs, symptoms, history, and comorbidities), and other clinical decisionmaking tools. These tests could be compared to either overnight PSG or portable testing. We excluded studies that assessed only single patient characteristics or risk factors. We also excluded tests that were not validated in a group of participants separate from the sample used to develop the test. Accepted studies either validated their models in a separate subgroup of study participants or had their models evaluated in subsequent studies.
Phased testing (Key Question 2). We included any study that directly compared phased testing (a series of tests performed dependent on the results of initial tests) with full testing (overnight PSG) alone.
Preoperative screening (Key Question 3). We included studies that assessed any test or predictor of sleep apnea.
Predictors of long-term outcomes (Key Question 4). We included studies that assessed AHI (or similar sleep study measures) together with other potential predictors of long-term outcomes.
Treatment of OSA (Key Question 5) and treatment compliance (Key Questions 6 & 7). We included studies that assessed almost any proposed intervention or combination of interventions to treat (or manage) OSA or to improve compliance with OSA treatment (listed below). However, for nonsurgical interventions, the patients must have used the intervention at home (or equivalent). Thus studies in which the patients received the intervention only in the sleep laboratory (primarily studies of positive airway pressure devices) were excluded. The included interventions, alone or in combination, were:
- Positive airway pressure devices (continuous positive airway pressure [CPAP], bilevel positive airway pressure, autotitrating continuous positive airway pressure, other similar devices, and device modifications designed to improve comfort or compliance)
- Oral appliances and dental devices (mandibular advancement devices, tongue-retaining devices, and other similar devices)
- Devices designed to alter sleep positions (positional therapy)
- Weight loss interventions (where the goal was improvement of OSA)
- Physical therapy, training, or strengthening of the airway
- Surgical implants in the oropharynx
- Any surgery to the airway designed to reduce airway obstruction
- Medications of current interest for possible treatment of OSA
- Based on decisions of the TEP, we excluded drugs that treat sleepiness, sleep quality, or bruxism, but not OSA, drugs used only in highly selected patients with OSA (e.g., those with Alzheimer’s disease). The excluded drugs include: armodafinil, bromocriptine, donepezil, eszopiclone, and modafinil.
- Miscellaneous interventions (including, but not limited to, drugs, complementary and alternative medicine, and atrial overdrive pacing).
In studies relevant to Key Question 6, patients must have received a nonsurgical treatment (a treatment with which they would need to comply). In studies relevant to Key Question 7, patients must have received either CPAP (or a variation), an oral or dental device, or a positional therapy device, in addition to an intervention whose purpose was to improve the compliance with the device.
Outcomes of Interest
Diagnostic testing (Key Questions 1 & 2). We included all studies reporting concordance or agreement among tests, predictive value (sensitivity, specificity) for diagnosis, change in clinical management, and clinical outcomes.
Preoperative screening (Key Question 3). We included studies reporting all intraoperative events, surgical recovery events, surgical recovery time, postsurgical events, length of intensive care or hospital stay, and intubation or extubation failures.
Predictors of long-term outcomes (Key Question 4). We included analyses of long-term clinical outcomes of interest, including all-cause mortality, cardiovascular death, nonfatal cardiovascular disease, incident hypertension, quality of life measures, incident stroke, and incident type 2 diabetes mellitus.
Treatment of OSA (Key Question 5). We included all studies reporting the following apnea-related outcomes of interest (see below for descriptions of selected OSA-related outcomes):
- Sleep/wakefulness clinical outcomes
- Quality of life outcomes, both disease specific (e.g., Functional Outcomes of Sleep Questionnaire [FOSQ], Calgary questionnaire) as well as general (e.g., Short Form survey instrument 36 [SF-36]).
- Sleepiness/somnolence measures, including validated subjective (e.g., Epworth Sleepiness Scale) and objective measures (e.g., Multiple Sleep Latency Test, Maintenance of Wakefulness Test).
- Neurocognitive tests, as reported by studies
- Accidents ascribed to somnolence (e.g., motor vehicle, home accidents)
- Productivity outcomes (e.g., work days lost)
- Objective clinical outcomes
- Mortality
- Cardiovascular events, including categorical changes in hypertension diagnosis or stage
- Non-insulin-dependent diabetes (diagnosis, resolution, start or end treatment)
- Depression events (diagnosis, recurrence, etc.).
- Intermediate or surrogate outcomes
- Sleep study measures (from a minimum of 6 hour sleep studies)
- Apnea-hypopnea index (AHI, continuous or categorical). If AHI not reported, we captured respiratory disturbance index or oxygen desaturation index
- Arousal index
- Time in deeper sleep stages (stages 3–4 and rapid eye movement sleep)
- Sleep efficiency (percent of time spent asleep)
- Minimum (nadir) oxygen saturation
- Comorbidities surrogate outcomes
- Hemoglobin A1c
- Blood pressure (systolic, diastolic, and mean arterial pressures)
- Compliance (adherence), either categorically (whether adhering or not) or quantitatively (time using device)
- Adverse events, complications, and harms
Description of OSA-related outcomes
- Epworth Sleepiness Scale (ESS): A self-administered questionnaire which asks the patients the chances of their dozing in eight situations often encountered in daily life. Each item is rated on a 4-point scale, with a total score that can range from 0 to 24.35 It measures “sleep propensity” as it asks about actual dozing, not “subjective sleepiness.” Based on a study of normal subjects, the reference range is defined as ≤10. 57,58 Domain experts consider a 1 point change in ESS to be clinically significant.
- Multiple sleep latency test (MSLT): A measurement of how quickly a subject falls asleep (when asked to) lying down in a quiet, darkened room. Sleep onset is monitored by electrodes and other wires.59 Though a reference range is not used in clinical practice, based on several studies of normal volunteers, a plausible reference range is 3.2 to 20 minutes.58
- Maintenance of wakefulness test (MWT): A measurement of how long a subject can stay awake (when asked to) sitting in bed, resting against pillows, in a quiet, dimly lit room. Sleep onset is monitored by electrodes and other wires.60 Using a 20 minute protocol, a plausible reference range is approximately 12 to 20 minutes (staying awake).58
- Apnea-hypopnea index (AHI): The number of episodes of apnea (complete airflow cessation) plus the number of hypopneas (reduced airflow) per hour of monitored sleep. Only PSG and portable monitors that measure airflow directly measure AHI. As noted above, the American Academy of Sleep Medicine uses a threshold of 15 events/hr (with or without OSA symptoms) or 5 events/hr with OSA symptoms to define OSA.31,32 Portable monitors that do not measure airflow may measure an oxygen desaturation index (ODI), the frequency of predefined oxygen desaturations (usually decreases of 3 or 4 percent). A related measure is the respiratory disturbance index (RDI), the frequency of respiratory events that disrupt sleep (in addition to apneas and hypopneas).
- Arousal index: The frequency per hour of arousals from sleep measured by electroencephalography as sudden shifts in brain wave activity.
- Slow wave sleep (stage 3 or 4 sleep): The percentage of time while asleep that the subject is in stage 3 or 4 sleep, measured by electroencephalography.
- Sleep efficiency: The percentage of time that a subject is asleep while in bed.
- Minimum oxygen saturation: The minimum oxygen saturation measured during sleep.
Treatment compliance (Key Questions 6 & 7). We included studies reporting adherence or compliance outcomes that were measured categorically as well as continuously (time spent using device per each time period).
Study Designs
We included only English-language, published, peer-reviewed articles. We did not include abstracts, conference proceedings, or other unpublished “grey” literature. Sample size thresholds were chosen based primarily on practical consideration of available resources and time balanced with the likely amount of available literature.
Diagnostic testing and screening (Key Questions 1–3). We included all prospective cross-sectional or longitudinal studies of any followup duration. At least 10 study participants had to be analyzed with each test of interest. For studies pertaining to Key Question 1, we did not reevaluate studies included in the 2007 Technology Assessment of Home Diagnosis of Obstructive Sleep Apnea-Hypopnea Syndrome, also written by the Tufts EPC.26 The findings of relevant studies from the previous report are summarized briefly in the appropriate sections of the Results section. These studies were also included in relevant figures; however, they are not presented in the summary tables of the present review.
Predictors of long-term outcomes (Key Question 4). We included longitudinal studies enrolling ≥500 participants with a followup ≥1 year. Included studies had to report a multivariable analysis.
Treatment of Sleep Apnea (Key Question 5) and treatment compliance (Key Question 7). We included longitudinal studies that analyzed ≥10 patients per intervention. Nonsurgical studies were restricted to randomized controlled trials (RCTs). We also included retrospective and nonrandomized prospective studies that compared surgery (including bariatric surgery) to other modes of intervention. Furthermore, we included prospective or retrospective noncomparative cohort studies of surgical interventions. However, these studies were restricted to those with at least 100 patients who received a given type of surgery. From these surgical cohort studies we evaluated only adverse events (complications). For Key Question 5, studies of any duration were accepted as long as the interventions were used in the home setting (or equivalent). Studies for Key Question 7 were restricted to those with ≥2 weeks followup.
Treatment compliance (Key Question 6). We included longitudinal studies that analyzed ≥100 patients who were followed for ≥1 month. For analyses of compliance with CPAP, we included only prospective studies that reported multivariable analyses. We included any analysis of compliance with other devices.
Data Extraction and Summaries
Two articles were extracted simultaneously by all researchers for training, after which approximately a dozen articles were double data extracted for further training. Subsequently, each study was extracted by one experienced methodologist. Each extraction was reviewed and confirmed by at least one other methodologist. Data were extracted into customized forms in Microsoft Word, designed to capture all elements relevant to the Key Questions. Separate forms were used for questions related to diagnosis (Key Questions 1–3), treatment (Key Questions 5 & 7), surgical cohort treatment studies (Key Question 5), and predictors (Key Questions 4 & 6) (see Appendix C for the data extraction forms). The forms were tested on several studies and revised before commencement of full data extraction.
Items common to the diagnosis and treatment forms included first author, year, country, sampling population, recruitment method, whether multicenter or not, enrollment years, funding source, study design, inclusion, and exclusion criteria, specific population characteristics including demographics such as age and sex, blood pressure, and baseline severity of OSA as measured by PSG and subjective scales like ESS.
For Key Questions related to diagnosis, information extracted about the test included the setting, the scoring system, the definitions of apnea and hypopnea, time period of the test, whether total sleep time or the total recording time was used as the denominator for calculation of the indices, and cutoffs used in comparisons. If the index test was a device, then additional details on the type of device, channels, and the synchronicity with polysomnographic testing were also extracted. Data used to develop the questionnaire were ignored; only data from validation samples were extracted.
For the Key Questions related to treatment, details regarding the interventions, including type of positive airway pressure device, surgical techniques, dental or oral devices were also extracted, as well as those of adjunct interventions. Extracted information included definitions, followup time periods, and type of outcome (sleep/wakefulness clinical outcomes; general and disease-specific quality of life outcomes; sleepiness/somnolence measures; general symptom scales; psychological, cognitive, or executive function, and physical function scales; somnolence-related accidents; sleep quality; objective clinical outcomes; and intermediate or surrogate outcomes like sleep study or clinical measures). Compliance was also recorded as an outcome.
For each outcome of interest, baseline, followup, and change from baseline data were extracted, including information of statistical significance. For most outcomes, only data from the last reported time point was included. When outcome data were reported as overall outcomes, without a specific time point, the mean or median time of followup was used. All adverse event data were extracted.
For studies that reported analyses of predictors of outcomes (related to Key Question s 4 & 6), full data were extracted for each predictor of interest when analyses were performed from the perspective of the predictor (i.e., baseline age as a predictor of death, not the mean age of those who lived and died). Multivariable analyses that included the most pretreatment predictors were preferred over other reported analyses.
Quality Assessment
We assessed the methodological quality of studies based on predefined criteria. We used a three-category grading system (A, B, or C) to denote the methodological quality of each study as described in the AHRQ methods guide (see this chapter’s introductory paragraph). This grading system has been used in most of the previous evidence reports generated by the Tufts EPC. This system defines a generic grading scheme that is applicable to varying study designs including RCTs, nonrandomized comparative trials, cohort, and case-control studies. For RCTs, we primarily considered the methods used for randomization, allocation concealment, and blinding as well as the use of intention-to-treat analysis, the report of dropout rate, and the extent to which valid primary outcomes were described as well as clearly reported. For treatment studies, only RCTs could receive an A grade. Nonrandomized studies and prospective and retrospective cohort studies could be graded either B or C. For all studies, we used (as applicable): the report of eligibility criteria, the similarity of the comparative groups in terms of baseline characteristics and prognostic factors, the report of intention-to-treat analysis, crossovers between interventions, important differential loss to followup between the comparative groups or overall high loss to followup, and the validity and adequacy of the description of outcomes and results.
A (good). Quality A studies have the least bias, and their results are considered valid. They generally possess the following: a clear description of the population, setting, interventions, and comparison groups; appropriate measurement of outcomes; appropriate statistical and analytic methods and reporting; no reporting errors; clear reporting of dropouts and a dropout rate less than 20 percent dropout; and no obvious bias. For treatment studies, only RCTs may receive a grade of A.
B (fair/moderate). Quality B studies are susceptible to some bias, but not sufficiently to invalidate results. They do not meet all the criteria in category A due to some deficiencies, but none likely to introduce major bias. Quality B studies may be missing information, making it difficult to assess limitations and potential problems.
C (poor). Quality C studies have been adjudged to carry a substantial risk of bias that may invalidate the reported findings. These studies have serious errors in design, analysis, or reporting and contain discrepancies in reporting or have large amounts of missing information.
Data Synthesis
We summarized all included studies in narrative form as well as in summary tables (see below) that condense the important features of the study populations, design, intervention, outcomes, and results. For questions regarding comparisons of diagnostic tests (Key Questions 1–3), we used Bland-Altman plots, which graph the differences in measurements against their average.61,62 This approach is recommended for analyses in which neither test can be considered a reference (gold) standard, as is the case with sleep apnea diagnostic tests. For each study with available information (either reported in the paper or after figure digitizing), we visually depicted the average difference between the two measurements and the spread of the 95 percent limits of agreement the boundaries that include 95 percent of the differences between the two measurements). We conducted analyses of sensitivity and specificity in studies that did not report Bland-Altman plots. Briefly, the sensitivity and specificity were derived and visually depicted in receiver operating characteristics space. Studies that yielded high positive likelihood ratio and/or low negative likelihood ratio were identified. For operational cutoffs for a high positive likelihood ratio and a low negative likelihood ratio we used the values 10 and 0.1, respectively.63 We did not attempt to meta-analyze the diagnostic test studies.
For Key Questions 5 & 7 that evaluate the effect of an intervention on intermediate and clinical outcomes, we performed DerSimonian & Laird64 random effects model meta-analyses of differences of continuous variables between interventions where there were at least three unique studies that were deemed to be sufficiently similar in population and had the same comparison of interventions and the same outcomes. Based on available data and clinical importance, we performed meta-analyses for AHI, ESS, arousal index, minimum oxygen saturation, multiple sleep latency test, the quality of life measure FOSQ, and compliance.
During data extraction we found that about half of the RCTs had a parallel design (separate groups of patients received separate interventions for the duration of the trial) and half had a crossover design (where all patients received all interventions for a given duration, in random order). For parallel trials, we evaluated the net change (the difference between the change from baseline between the intervention of interest and the control intervention). Almost all crossover studies analyze the difference in final values after treatment with the different interventions. The concept is that, by definition, there is only one set of baseline values for the cohort of patients, and these, thus, cancel out. Therefore, for crossover studies, differences of final values are evaluated.
However, a large number of studies did not report full statistical analyses of the net change or difference of final values. Where sufficient data were reported, we calculated these values and estimated their confidence intervals (CI). These estimates were included in the summary tables and were used for meta-analyses. In the summary tables we include only the P values reported by the studies (not estimated P values). If a study reported an exact P value for the difference, we calculated the CI based on the P value. When necessary, standard errors of the differences were estimated from reported standard deviations (or standard errors) of baseline and/or final values. For parallel trials, we assumed a 50 percent correlation of baseline and final values in patients receiving a given intervention. Likewise for crossover trials, we assumed a 50 percent correlation between final values after interventions (among the single cohort of patients). Thus in both cases we used the following equation to estimate the standard error (SE):
where r=0.5 and A & B are the correlated values.
For our primary meta-analyses, we combined the net changes from the parallel trials and the difference of final values from the crossover trials. However, we also performed (and include in the figures) subgroup analyses based on study design.
For Key Questions 4 & 6, the reported associations are presented in summary tables and described and discussed in narrative form. We did not attempt any metaregression for these studies.
Summary Tables
All summary tables are located in Appendix D. Summary tables succinctly report measures of the main outcomes evaluated. The decision about which data to include in the summary tables was made in consultation with the TEP. We included information regarding sampling population, country, study design, interventions, demographic information on age and sex, body mass index, the study setting, information on severity of sleep apnea (based on AHI and ESS), number of subjects analyzed, mean study duration and range, years of intervention, dropout rate, and study quality. For continuous outcomes, we included the baseline values, the within-group changes (or final values for crossover studies), the net difference (or difference between final values) and its 95 percent CI and P value. For categorical (dichotomous) outcomes, we report the number of events and total number of patients for each intervention and (usually) the risk difference and its 95 percent CI and P value. After consideration of the reported data across studies, and with the agreement of the TEP, we entered results for quality of life outcomes (except FOSQ) and for all neurocognitive test outcomes into a highly summarized table which does not provide all reported data. In these tables, for each test (or scale or subscale, etc.) we report which intervention statistically significantly favored the patient (e.g., resulted in better quality of life). If neither intervention was favored, we report no further data. If one intervention was statistically significantly better than another, we report the net (or final) difference for the test (or subscale), its estimated 95 percent CI and P value, and the “worst” and “best” possible scores for the test.
Each set of tables includes a study and patient characteristics table (which is organized in alphabetical order by first author). Results are presented in separate summary tables for each outcome. Within these tables, the studies are ordered by quality (A to C), then number of patients analyzed for that outcome (largest to smallest). It should be noted that the P value column includes the P value reported in the articles for the difference in effect between the two interventions of interest. The table also includes the 95 percent CI about the net difference (or difference in final values, from crossover studies); however, in the large majority of cases, these numbers were estimated by the Tufts EPC based on reported standard deviations, standard errors, and P values. This is noted in each table.
Grading a Body of Evidence for Each Key Question
We graded the strength of the body of evidence for each analysis within each Key Question as per the AHRQ methods guide,65 with modifications as described below. Risk of bias was defined as low, medium, or high based on the study design and methodological quality. We assessed the consistency of the data as either “no inconsistency” or “inconsistency present” (or not applicable if only one study). The direction, magnitude, and statistical significance of all studies were evaluated in assessing consistency, and logical explanations were provided in the presence of equivocal results. We also assessed the relevance of evidence. Studies with limited relevance either included populations which related poorly to the general population of adults with OSA or that contained substantial problems with the measurement of the outcome(s) of interest. We also assessed the precision of the evidence based on the degree of certainty surrounding an effect estimate. A precise estimate was considered an estimate that would allow a clinically useful conclusion. An imprecise estimate was one for which the CI is wide enough to preclude a conclusion.
We rated the strength of evidence with one of the following four strengths (as per the AHRQ methods guide): High, Moderate, Low, and Insufficient. Ratings were assigned based on our level of confidence that the evidence reflected the true effect for the major comparisons of interest. Ratings were defined as follows:
High. There is high confidence that the evidence reflects the true effect. Further research is very unlikely to change our confidence in the estimate of effect.
No important scientific disagreement exists across studies. At least two quality A studies are required for this rating. In addition, there must be evidence regarding objective clinical outcomes.
Moderate. There is moderate confidence that the evidence reflects the true effect. Further research may change our confidence in the estimate of effect and may change the estimate.
Little disagreement exists across studies. Moderately rated bodies of evidence contain fewer than two quality A studies or such studies lack long-term outcomes of relevant populations. Upon reviewing the evidence, we decided that when there was no or weak evidence for clinical outcomes but sufficient evidence (see further below on this page) of a large clinical and highly statistically significant effect on the relatively important sleep study and sleepiness measures (i.e., AHI, arousal index, minimum oxygen saturation, ESS, and FOSQ), we would rate the overall strength of evidence as moderate, despite the weak evidence on clinical outcomes.
Low. There is low confidence that the evidence reflects the true effect. Further research is likely to change the confidence in the estimate of effect and is likely to change the estimate.
Underlying studies may report conflicting results. Low rated bodies of evidence could contain either quality B or C studies.
Insufficient. Evidence is either unavailable or does not permit a conclusion.
There are sparse or no data. In general, when only one study has been published, the evidence was considered insufficient, unless the study was particularly large, robust, and of good quality.
These ratings provide a shorthand description of the strength of evidence supporting the major questions we addressed. However, they by necessity may oversimplify the many complex issues involved in appraising a body of evidence. The individual studies involved in formulating the composite rating differed in their design, reporting, and quality. The strengths and weaknesses of the individual reports, as described in detail in the text and tables, should also be considered.
When there were disagreements on effect estimates across different outcomes within the same comparison or when a large amount of evidence existed for only an important surrogate outcome (e.g., AHI), we also rated the strength of evidence for particular outcomes within a comparison. Similar rating categories and criteria were used; however, the descriptors were altered to delineate between rating the comparison and rating the individual outcomes within a comparison. These descriptors are modifications of the standard AHRQ approach:
Sufficient. There is sufficient assurance that the findings of the literature are valid with respect to the outcome of interest within a comparison. No important scientific disagreement exists across studies. Further research is unlikely to change our confidence in the estimate of effect for this outcome.
Fair. There is fair assurance that the findings of the literature are valid with respect to the outcome of interest within a comparison. Little disagreement exists across studies. Further research may change our confidence in the estimate of effect and may change the estimate for this outcome.
Weak. There is weak assurance that the findings of the literature are valid with respect to the outcome of interest within a comparison. Underlying studies may report conflicting results. Further research is likely to change our confidence in the estimate of effect and may change the estimate for this outcome.
Limited or no evidence. Evidence is either unavailable or does not permit estimation of an effect due to lacking or sparse data for the outcome of interest within a comparison.
Overall Summary Table
To aid discussion, we summarized all studies and findings into one table in the Summary and Discussion. Separate cells were constructed for each Key Question and subquestion. The table also includes the strength of evidence to support each conclusion.
Peer Review and Public Commentary
As part of a newly instituted process at AHRQ, the initial draft report was prereviewed by the TOO and an AHRQ Associate Editor (a senior member of a sister EPC). Following revisions, the draft report was sent to invited peer reviewers and was simultaneously uploaded to the AHRQ Website where it was available for public comment for 30 days. All reviewer comments (both invited and from the public) were collated and individually addressed. The authors of the report had final discretion as to how the report was revised based on the reviewer comments, with oversight by the TOO and Associate Editor.
- AHRQ Task Order Officer
- External Expert Input
- Key Questions
- Analytic Framework
- Literature Search
- Study Selection and Eligibility Criteria
- Data Extraction and Summaries
- Quality Assessment
- Data Synthesis
- Summary Tables
- Grading a Body of Evidence for Each Key Question
- Overall Summary Table
- Peer Review and Public Commentary
- Methods - Diagnosis and Treatment of Obstructive Sleep Apnea in AdultsMethods - Diagnosis and Treatment of Obstructive Sleep Apnea in Adults
Your browsing activity is empty.
Activity recording is turned off.
See more...