

NCBI Bookshelf. A service of the National Library of Medicine, National Institutes of Health.
National Guideline Alliance (UK). Faltering Growth – recognition and management. London: National Institute for Health and Care Excellence (NICE); 2017 Sep. (NICE Guideline, No. 75.)

This chapter sets out in detail the methods used to review the evidence and to generate the recommendations that are presented in subsequent chapters. This guidance was developed in accordance with the methods outlined in the NICE guidelines manual 2014.
3.1. Developing the review questions and protocols
The 14 review questions developed for this guideline were based on the key areas identified in the guideline scope. They were drafted by the NGA, and refined and validated by the Guideline Committee.
The review questions were based on the following frameworks:
- intervention reviews – using population, intervention, comparison and outcome (a PICO framework)
- reviews of diagnostic test or clinical prediction model accuracy – using population, diagnostic test (index tests), reference standard and target condition
- qualitative reviews – using population, area of interest and themes of interest
- prognostic reviews – using population, presence or absence of a risk factor, and outcome.
Full literature searches, critical appraisals and evidence reviews were completed for all review questions.
3.2. Searching for evidence
3.2.1. Clinical literature searches
Systematic literature searches were undertaken to identify all published clinical evidence relevant to each review question.
Databases were searched using medical subject headings, free-text terms and study type filters where appropriate. Special consideration was given to search terms relating to early weight loss following birth to ensure that relevant studies were captured. Relevant search terms such as hypernatremia and dehydration were used in the searches as well as figures for the percentage of weight change that might cause concern. Where possible, searches were restricted to retrieve articles published in English. All searches were conducted in the following databases: Medline, Embase, Health Technology Assessments (HTA), Cochrane Central Register of Controlled Trials (CCTR), Cochrane Database of Systematic Reviews (CDSR), and Database of Abstracts of Reviews of Effects (DARE). Where relevant to specific review questions the following additional databases were also searched: PsycInfo, AMED (Allied and Complementary Medicine) and CINAHL (Cumulative Index to Nursing and Allied Health Literature). All searches were updated on 20th January 2017. Any studies added to the databases after this date (including those published prior to this date but not yet indexed) were not considered relevant for inclusion.
Search strategies were quality assured by cross-checking reference lists of relevant papers, analysing search strategies from other systematic reviews and asking Guideline Committee members to highlight key studies. All search strategies were also quality assured by an Information Scientist who was not involved in the development of the search. Details of the search strategies, including study type filters that were applied and databases that were searched, can be found in Appendix E.
All references suggested by stakeholders at the time of the scope consultation were considered for inclusion. During the scoping stage, searches were conducted for guidelines, health technology assessments, systematic reviews, economic evaluations and reports on biomedical databases and websites of organisations relevant to the topic. Formal searching for grey literature, unpublished literature and electronic, ahead-of-print publications was not routinely undertaken.
3.2.2. Health economics literature searches
Systematic literature searches were also undertaken to identify relevant published health economic evidence. A broad search was conducted to identify health economic evidence relating to faltering growth in the following databases: NHS Economic Evaluation Database (NHS EED) and Health Technology Assessment (HTA). A broad search was also conducted to identify health economic evidence relating to faltering growth in the following databases with an economic search filter applied: Medline, Cochrane Central Register of Controlled Trials (CCTR) and Embase. Where possible, the search was restricted to articles published in English and studies published in languages other than English were not eligible for inclusion.
The search strategies for the health economic literature search are included in Appendix E. All searches were updated on 20th January 2017. Any studies added to the databases after this date (including those published prior to this date but not yet indexed) were not included unless specifically stated in the text.
3.3. Reviewing research evidence
3.3.1. Types of studies and inclusion and exclusion criteria
For most intervention reviews in this guideline, parallel randomised controlled trials (RCTs) were prioritised because they are considered the most robust type of study design that could produce an unbiased estimate of the intervention effects.
For diagnostic, clinical prediction rule or prevalence reviews, cross-sectional, retrospective or prospective cohort studies were considered for inclusion. For prognostic reviews, prospective and retrospective cohort and case-control studies were included.
For qualitative reviews, studies using focus groups, or structured or semi-structured interviews were considered for inclusion. Survey data or other types of questionnaires were only included if they provided analysis from open-ended questions, but not if they reported descriptive quantitative data only.
Where data from observational studies were included, the Committee agreed that the results for each outcome should be presented separately for each study and meta-analysis was not conducted.
The evidence was reviewed following the steps shown schematically in Figure 1:
- Potentially relevant studies were identified for each review question from the relevant search results by reviewing titles and abstracts. Full papers were then obtained.
- Full papers were reviewed against pre-specified inclusion and exclusion criteria to identify studies that addressed the review question in the appropriate population, as outlined in the review protocols (review protocols are included in Appendix D).
- Relevant studies were critically appraised using the appropriate checklist as specified in the NICE guidelines manual.
- Key information was extracted on the study’s methods, according to the factors specified in the protocols and results. These were presented in summary tables (in each review chapter) and evidence tables (in Appendix G).
- Summaries of evidence were generated by outcome (included in the relevant review chapters) and were presented in Committee meetings (details of how the evidence was appraised is described in Section 3.5 below):
- Randomised studies: meta-analysis was carried out where appropriate and results were reported in GRADE profiles (for intervention reviews).
- Observational studies of interventions: data were presented as a range of values in GRADE profiles.
- Prognostic studies: data were presented as a range of values, usually in terms of the relative effect as reported by the authors.
- Prevalence studies: data were presented as a range of values, in terms of the absolute prevalence as reported by the authors.
- Diagnostic or clinical prediction rule studies: data were presented as measures of diagnostic test accuracy (sensitivity and specificity) and were presented in modified GRADE profiles.
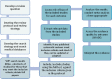
Figure 1
Step-by-step review of evidence in the guideline.
For quality assurance of study identification, a 10% sample of the study searches were double checked by a second reviewer for the following review questions: normal weight loss in the early days of life, weight loss in the early days of life associated with adverse outcomes, thresholds for faltering growth, risk factors for faltering growth, non-nutritional interventions, monitoring and referral.
Any disagreements in study selection were resolved by discussion between the two reviewers.
All drafts of reviews were checked by a second reviewer.
3.3.1.1. Specific inclusions and exclusions
The definitions of the faltering growth condition varied widely between studies. Often cases were only very loosely classified. The Committee therefore decided to include any study referring to a ‘faltering growth’ population of children even when it was unlikely that the definition would be specific enough to accurately identify all children generally considered to show faltering growth. The definitions were then extracted and the applicability of this was then taken into consideration when the evidence was discussed.
Infants showing early weight loss in the first days of life were treated as a separate group. For this group of infants the term ‘faltering growth’ would not usually be used. We therefore widened the search for this group to include terms such as ‘feeding problem’, ‘weight losses and others.
Throughout this guideline only evidence from high income countries (http://data.worldbank.org/income-level/high-income) was considered for inclusion. It was agreed that the reasons and interventions for faltering growth in middle and low income countries would not be generalisable to the NHS setting.
3.4. Method of combining clinical studies
When planning reviews (protocols), the following approaches for data synthesis were discussed and agreed with Committee.
3.4.1. Data synthesis for intervention reviews
It was planned to conduct meta-analyses where possible to combine the results of studies for each review question using Cochrane Review Manager (RevMan5) software.
Fixed-effects (Mantel–Haenszel 1959) techniques were used to calculate risk ratios (relative risk) for binary outcomes, such as rate of adverse events or rate of people with symptom improvements (Mantel–Haenszel 1959).
For continuous outcomes, measures of central tendency (mean) and variation (standard deviation) are required for meta-analysis. Data for continuous outcomes (such as level of pain on a visual analogue scale [VAS]) were analysed using an inverse variance method for pooling weighted mean differences. A generic inverse variance option in RevMan5 is used if any studies reported solely the summary statistics and 95% confidence interval (95% CI) or standard error. However, in cases where standard deviations were not reported per intervention group, the standard error (SE) for the mean difference is calculated from other reported statistics (p values or 95% CIs): meta-analysis was then undertaken for the mean difference and SE using the generic inverse variance method in RevMan5. When the only evidence was based on studies summarising results by presenting medians (and interquartile ranges) or only p values were given, this information was assessed in terms of the study’s sample size and was included in the GRADE tables without calculating the relative or absolute effects. Consequently, aspects of quality assessment, such as imprecision of effect, could not be assessed for evidence of this type. However, the limited reporting of this outcome was classified as a risk of bias in study limitations.
Stratified analyses were predefined for some review questions at the protocol stage when the Committee identified that these strata are different in terms of biological and clinical characteristics and the interventions were expected to have a different effect.
Statistical heterogeneity was assessed by visually examining the forest plots, and by considering the chi-squared test for significance at p<0.1 or an I-squared inconsistency statistic (with an I-squared value of more than 50% indicating considerable heterogeneity). Where considerable heterogeneity was present, predefined subgroup analyses were performed.
Assessments of potential differences in effect between subgroups were based on the chi-squared tests for heterogeneity statistics between subgroups. If no sensitivity analysis was found to completely resolve statistical heterogeneity, then a random-effects (DerSimonian and Laird) model was employed to provide a more conservative estimate of the effect – (DerSimonian and Laird 1986).
3.4.2. Data synthesis for predictive accuracy reviews
Weight loss and length/height thresholds can be used as a clinical prediction rule to help identify whether an infant with weight loss in the early days of life or a child with faltering growth is at increased risk of adverse outcomes. For studies using weight or length thresholds as predictors of adverse outcomes, results were summarised as sensitivity, specificity and likelihood ratios. Predictive accuracy data were not pooled but presented as ranges.
3.4.3. Data synthesis for prognostic reviews
Identification of risk factors for faltering growth could aid early identification and management strategies. Odds ratios (ORs) or risk ratios (RRs) with their 95% confidence intervals (95% CIs) for the effect of the pre-specified thresholds on the adverse outcome of interest, were extracted from the papers when reported. For this topic, we looked for studies that took into account possible key confounders (such as age, duration of follow-up and interventions for faltering growth) as reported in multivariable analyses. These studies were typically cohort studies and for his reason the prognostic data were not pooled but ranges were reported.
3.4.4. Data synthesis for prevalence reviews
In rare cases faltering growth is associated with an undiagnosed new clinical symptoms order and the appropriate testing strategy will depend on the prevalence of such disorders. For this topic we sought studies which had investigated cohorts of children with faltering growth and reported the prevalence of undiagnosed underlying disorders. It was agreed with the Committee that any reported prevalence values for each underlying disorder would not be pooled but reported as a range of percentages. This was due to the possible heterogeneous nature of individual cohorts that may report such prevalence rates.
3.4.5. Data synthesis for normal weight loss in the early days of life
For the review of normal weight loss in the early days of life the 50th, 95th and 97.5th centiles of the maximum weight loss compared to birth weight were extracted from cohort studies. The commonest timing of this lowest weight point (nadir) was also noted for each cohort as well as time to return to birth weight. It was agreed with the Committee that these data would not be pooled but reported as a ranges. This was due to the possible heterogeneous nature of individual cohorts.
3.5. Appraising the quality of evidence
For intervention reviews, the evidence for outcomes from the included RCTs and observational studies were evaluated and presented using GRADE, which was developed by the international GRADE working group. For prognostic and prevalence reviews the quality of evidence was summarised on a per-study basis for each reported risk-factor or prevalence estimate.
The software developed by the GRADE working group (GRADEpro) was used to assess the quality of each outcome, taking into account individual study quality factors and the meta-analysis results. The clinical/economic evidence profile tables include details of the quality assessment and pooled outcome data, where appropriate, an absolute measure of intervention effect and the summary of quality of evidence for that outcome. In this table, the columns for intervention and control indicate summary measures of effect and measures of dispersion (such as mean and standard deviation or median and range) for continuous outcomes and frequency of events (n/N: the sum across studies of the number of patients with events divided by sum of the number of completers) for binary outcomes. Reporting or publication bias was only taken into consideration in the quality assessment and included in the clinical evidence profile tables if it was apparent.
The selection of outcomes for each review question was decided when each review protocol was discussed with the Guideline Committee. However, given the nature of most of the review questions included in this guideline many of which were not intervention reviews the categorisation of outcomes as critical and important did not follow the standard GRADE approach but could be related to which particular risk factor was important, whether sensitivity or specificity would be given more weight, or the outcome maximal weight loss in the early days was divided into three critical outcomes (what percentage of weight loss, when it occurred and when weight would be regained). The outcomes were selected by the Committee for a review question as critical for decision-making in a specific context and recorded in the relevant review protocol.
The evidence for each outcome in interventional reviews was examined separately for the quality elements listed and defined in Table 3. Each element was graded using the quality levels listed in Table 4.
Table 3
Description of quality elements in GRADE (see details in sections 3.5.1.1 to 3.5.1.4).
Table 4
Levels of quality elements in GRADE level.
The main criteria considered in the rating of these elements are discussed below. Footnotes were used to describe reasons for grading a quality element as having serious or very serious limitations. The ratings for each component were summed to obtain an overall assessment for each outcome (Table 5).
Table 5
Overall quality of outcome evidence in GRADE level.
The GRADE toolbox is designed for intervention reviews of RCTs and observational studies. For diagnostic accuracy, prognostic and prevalence reviews the evidence was assessed per study level.
3.5.1. Grading the quality of clinical evidence
After results were pooled, the overall quality of evidence for each outcome was considered. The following procedure was adopted when using the GRADE approach:
- A quality rating was assigned based on the study design. For intervention reviews RCTs start as high, observational studies as moderate and uncontrolled case series as low or very low.
- The rating was then downgraded for the specified criteria: risk of bias (study limitations); inconsistency; indirectness; imprecision; and publication bias. These criteria are detailed below. Evidence from observational studies (which had not previously been downgraded) was upgraded if there was a large magnitude of effect or a dose-response gradient, and if all plausible confounding would reduce a demonstrated effect or suggest a spurious effect when results showed no effect. Each quality element considered to have ‘serious’ or ‘very serious’ risk of bias was rated down by 1 or 2 points respectively.
- The downgraded/upgraded ratings were then summed and the overall quality rating was revised. For example, all RCTs started as high and the overall quality became moderate, low or very low if 1, 2 or 3 points were deducted respectively.
- The reasons or criteria used for downgrading were specified in the footnotes.
The details of the criteria used for each of the main quality elements are discussed further in section 3.5.1.1 below.
GRADE quality assessment was not performed for the reviews of prevalence, normal weight loss in the early days of life or for prognostic reviews not involving predictive accuracy. In these cases the quality of evidence was informed by the assessment of risk of bias.
3.5.1.1. Risk of bias
3.5.1.1.1. Intervention studies
Bias can be defined as anything that causes a consistent deviation from the truth. Bias can be perceived as a systematic error that could lead to over or underestimation of the effect.
The risk of bias for a given study and outcome is associated with the risk of over- or under-estimation of the true effect.
The sources of risk of bias are listed in Table 6.
Table 6
Risk of bias in randomised controlled trials.
A study with a poor methodological design would lead to high risk of bias. However, the bias is considered individually for each outcomes and subjectively reported outcomes will be more prone to be affect by risk of bias than objective outcomes.
3.5.1.1.2. Prognostic and clinical prediction rule studies
For prognostic and clinical prediction rule studies, quality was assessed using the Critical Appraisal Skills Programme (CASP) Clinical Prediction Tool Checklist. This checklist consists of 11 questions spread across 3 different sections – ‘are the results valid?’; ‘what are the results?’ and ‘will the results help locally/are the findings applicable to the scenario?’.
More details about the quality assessment for prognostic studies are shown in Table 7:
Table 7
Risk of bias for prognostic factor studies.
For prognostic reviews not involving predictive accuracy the CASP Clinical Prediction Tool Checklist was used instead of GRADE to derive an overall quality for each study (low, moderate or high) which was recorded in the summary of included studies table for each review. A study with 9 to 11 positive answers on the checklist was rated high quality, 6–8 answers moderate quality and 0 to 5 low quality.
3.5.1.1.3. Prevalence studies
For prevalence studies the risk of bias was assessed using the Joanna Briggs Institute Prevalence Critical Appraisal Tool (Munn 2014) which includes the critical issues of internal and external validity for prevalence studies as shown in Table 8.
Table 8
Risk of bias for prevalence studies.
For prevalence reviews the Joanna Briggs Institute Prevalence Critical Appraisal Tool was used instead of GRADE to derive an overall quality for each study (very low, low, moderate or high) which was recorded in the summary of included studies table for each review. A study with 10 positive answers on the checklist was rated high quality, 6–9 answers moderate quality and 0 to 5 low quality.
3.5.1.1.4. Studies of normal weight loss in the early days of life
For studies of normal weight loss in the early days of life, risk of bias was assessed using the Joanna Briggs Institute Prevalence Critical Appraisal Tool (Munn 2014) as shown in Table 8. This checklist was chosen because relevant studies report the prevalence of weight loss above various thresholds.
3.5.1.1.5. Studies to identify differences in feeding and eating behaviour and practices between infants and children with or without faltering growth
For case control studies quality was assessed using the checklist for case-control studies (Appendix H in the NICE guidelines manual 2012). The checklist assesses internal validity of the study – selection of participants, assessment, confounding factors, and statistical analysis-. The different domains are rated from well covered to not applicable. See Table 9 for a summary of the different domains.
Table 9
Risk of bias for case-control studies.
This checklist was used instead of GRADE to derive an overall quality for each study (very low, low, moderate or high) which was recorded in the summary of included studies table for each review, and used in the evidence statements.
3.5.1.2. Inconsistency
Inconsistency refers to unexplained heterogeneity of effect estimates. When estimates of the treatment effect, prognostic risk factor or diagnostic accuracy measures vary more widely between studies than would be expected due to random error alone (that is, there is heterogeneity or variability in results), this suggests true differences in underlying effects.
Heterogeneity in meta-analyses was examined; if present, sensitivity and subgroup analyses were performed as pre-specified in the protocols (appendix D).
When heterogeneity existed (chi-squared probability less than 0.1, I-squared inconsistency statistic of greater than 50%, or from visually examining forest plots), but no plausible explanation could be found (for example duration of intervention or different follow-up periods), the quality of the evidence was downgraded in GRADE by 1 or 2 levels, depending on the extent of inconsistency in the results. When outcomes are derived from a single trial, inconsistency is not an issue for downgrading the quality of evidence. However, ‘no inconsistency’ is nevertheless used to describe this quality assessment in the GRADE tables. In addition to the I-squared and chi-squared values and examination of forest plots, the decision for downgrading was dependent on factors such as whether the uncertainty about the magnitude of benefit (or harm) of the outcome showing heterogeneity would influence the overall judgment about net benefit or harm (across all outcomes).
For diagnostic, clinical prediction rule and prognostic evidence, this was assessed visually according to the differences in point estimates and overlap in confidence intervals. For prognostic evidence this could be related to inconsistent findings across different studies for the same risk factor or on the sensitivity / specificity forest plots (looking at the overlap of confidence intervals) or the variability of study results in the summary ROC curve.
3.5.1.3. Indirectness
For quantitative reviews, directness refers to the extent to which the populations, intervention/risk factor/index test, comparisons and outcome measures are similar to those defined in the inclusion criteria for the reviews. Indirectness is important when these differences are expected to contribute to a difference in effect size, or may affect the balance of harms and benefits considered for an intervention, affect the accuracy estimate of the index test or has an impact on the prognostic effect of a risk factor.
3.5.1.4. Imprecision
For intervention reviews, imprecision in guidelines concerns whether the uncertainty (confidence interval) around the effect estimate means that it is not clear whether there is a clinically important difference between interventions or not. This uncertainty is reflected in the width of the confidence interval. Imprecision occurs when this confidence interval crosses a clinical decision threshold that dictates recommending versus not recommending an intervention
The 95% confidence interval (95% CI) is defined as the range within which we can be 95% certain that the true effect lies. The larger the trial, the smaller the 95% CI and the more certain the effect estimate.
Imprecision in the evidence reviews was assessed by considering whether the width of the 95% CI of the effect estimate was relevant to decision-making, considering each outcome in isolation. This is explained in Figure 2, which considers a positive outcome for the comparison of treatment A versus treatment B. Three decision-making zones can be identified, bounded by the thresholds for clinical importance (minimal important difference, MID) for benefit and for harm. The MID for harm for a positive outcome means the threshold at which drug A is less effective than drug B by an amount that is clinically important to patients (favours B).
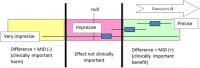
Figure 2
Illustration of precise and imprecise outcomes based on the confidence interval of outcomes in a forest plot.
When the confidence interval of the effect estimate is wholly contained in 1 of the 3 zones (for example clinically important benefit), we are not uncertain about the size and direction of effect (whether there is a clinically important benefit, or the effect is not clinically important, or there is a clinically important harm), so there is no imprecision.
When a wide confidence interval lies partly in each of 2 zones, it is uncertain in which zone the true value of effect estimate lies, and therefore there is uncertainty over which decision to make (based on this outcome alone). The confidence interval is consistent with 2 possible decisions and so this is considered to be imprecise in the GRADE analysis and the evidence is downgraded by 1 level (‘serious imprecision’).
If the confidence interval of the effect estimate crosses into 3 zones, this is considered to be very imprecise evidence because the confidence interval is consistent with 3 possible clinical decisions, and there is therefore a considerable lack of confidence in the results. The evidence is therefore downgraded by 2 levels in the GRADE analysis (‘very serious imprecision’).
Implicitly, assessing whether the confidence interval is in, or partially in, a clinically important zone, requires the Committee to estimate an MID or to say whether they would make different decisions for the 2 confidence limits.
The literature was searched for established MIDs for the selected outcomes in the evidence reviews, such as symptom measurement tools. In the absence of published MIDs, the Committee was asked whether they were aware of any acceptable MIDs in the clinical community. Finally, the Committee considered whether it was clinically acceptable to use the GRADE default MID to assess imprecision: for binary outcomes a 25% relative risk increase and the related relative risk reduction was used, which corresponds to clinically important thresholds for a risk ratio of 0.8 and 1.25 respectively (due to the statistical characteristic of this measure this means that this is not a symmetrical interval). This default MID for relative effect was used for all the binary outcomes in intervention reviews unless the Committee suggested a more appropriate value, such as an absolute risk difference criterion. For continuous outcomes default MIDs were also used. These use half of the median standard deviation of the control group.
For clinical prediction models (such as weight loss thresholds for concern) the Committee first considered whether sensitivity or specificity would be given more weight in the decision-making process. If one measure was given more importance than the other, then imprecision was rated on this measure. If the Committee could not agree clinically relevant thresholds of sensitivity or specificity then default values were used: less than 75% being low, 75% to 90% moderate and above 90% high sensitivity or specificity.
MIDs for prognostic factors were derived through Committee discussion of the size of the association between risk factor and outcome taking into account whether possible important confounding factors were considered in the analysis.
3.5.2. Assessing clinical significance (of intervention effects)
The Committee assessed the evidence by outcome in order to determine if there was, or potentially was, a clinically important benefit, a clinically important harm or no clinically important difference between interventions. To facilitate this, where possible, binary outcomes were converted into absolute risk differences (ARDs) using GRADEpro software: the median control group risk across studies was used to calculate the ARD and its 95% CI from the pooled risk ratio. For continuous outcomes, the mean difference between the intervention and control arm of the trial was calculated. This was then assessed in relation to the default MID (0.5 times the median control group standard deviation).
The assessment of clinical benefit or harm, or no benefit or harm, was based on the agreed MID of the effect, taking into consideration the precision around the effect estimate.
This assessment was carried out by the Committee for each critical outcome, and an evidence summary table (used in the Committee meetings, but not presented in this guideline) was produced to compile the Committee’s assessments of clinical importance per outcome, alongside the evidence quality and the uncertainty in the effect estimate (imprecision).
3.5.3. Assessing clinical significance (of prognostic effects or clinical prediction models)
Absolute risk differences were not calculated for prognostic findings in this guideline. The Committee considered the size of the relative effects and whether this was large enough to constitute a sign or symptom predicting the outcome of interest. The usefulness of clinical prediction models, such as weight loss thresholds for concern, was judged by combining evidence about their accuracy with baseline risk to estimate the proportion who would be misclassified, taking into consideration the consequences of false positive or false negative classification.
3.5.4. Evidence statements
Evidence statements summarise the key features of the clinical evidence. The wording of the evidence statements reflects the certainty or uncertainty in the estimate of effect.
The evidence statements for intervention reviews are presented by outcome, and encompass the following key features:
- the quality of the evidence (GRADE rating)
- the number of studies and the number of participants for a particular outcome
- an indication of the direction of effect (for example, if a treatment is clinically significant [beneficial or harmful] compared with another, or whether there is no difference between the tested treatments).
The evidence statements for prognostic, prediction model or prevalence reviews include the following
- the quality of the evidence (using modified GRADE rating for prediction models, or otherwise based on the study level risk of bias)
- the number of studies and the number of participants for a particular risk factor, prediction model or prevalence estimate
- a summary of the effect size of the prognostic factor, magnitude of the prevalence estimate or accuracy of the prediction model.
3.6. Evidence of cost effectiveness
The aims of the health economic input to the guideline were to inform the Guideline Committee of potential economic issues related to the management of faltering growth to ensure that recommendations represented a cost-effective use of healthcare resources. Health economic evaluations aim to integrate data on healthcare benefits (ideally in terms of quality-adjusted life-years (QALYs)) with the costs of different care options. In addition, the health economic input aimed to identify areas of high resource impact; recommendations which – while nevertheless cost-effective – might have a large impact on CCG or Trust finances and so need special attention.
The Committee prioritised a single economic model on service delivery where it was thought that economic considerations would be particularly important in formulating recommendations and a review of the health economic literature was undertaken. There were concerns in the Committee that their recommendations might represent a high resource impact, but the economic model suggested that savings in the healthcare system offset a large part of this impact. For economic evaluations, no standard system of grading the quality of evidence exists and included papers were assessed using the economic evaluations checklist as specified in the NICE guidelines manual.
Economic modelling was undertaken for a review question on monitoring suspected faltering growth. This was because it was thought that the Committee may want to make recommendations which were high resource impact, although the clinical evidence base did not support such recommendations. The Committee did not prioritise the health economic mode for this question as a lack of input data meant it could only function as a ‘what if’ analysis.
No economic analysis was undertaken for a question on interventions (nutritional or nonnutritional). While such an economic model might be valuable in deciding on the allocation of scarce NHS resources, no evidence was uncovered which might populate an economic model which meant that no model could be constructed.
No economic evaluation was undertaken for questions on risk factors, information and support, assessment, thresholds, differences between faltering growth and non-faltering growth or prevalence as it was agreed with the Committee that these reviews would focus primarily on the content and quality of information which is given to patients and clinicians respectively rather than whether the provision of such information represented a cost-effective use of NHS resources, which was thought to be clinically uncontroversial. Therefore these questions were not primarily about competing alternative uses for NHS resources and therefore were not considered suitable for economic analysis.
No economic analysis was undertaken for a question on referral to secondary care. This question was of a high health economic importance as the potential quality of life impact for misdiagnosing faltering growth and exposing a child to the potential harms of hospital is high, and potentially lifelong. However in order to perform a reasonable economic analysis on this question it would have been necessary to consider the cost-effectiveness of the treatment pathway for each possible reason to refer, some of which would be sensible referrals but – on further assessment – not turn out to be faltering growth. Some of these pathways have existing NICE guidance but some do not, which would have required de novo modelling (taking away resources from the main health economic guideline). For this question it was agreed with the Committee that health economic input would be limited to resource impact and analysis, with a full health economic evaluation being left until all possible referral pathways had been costed in other NICE Guidelines.
3.7. Developing recommendations
Over the course of the guideline development process, the Guideline Committee was presented with:
- evidence tables of the clinical and economic evidence reviewed from the literature: all evidence tables are in Appendix H
- summary of clinical and economic evidence and quality assessment (as presented in Chapters 4 to 11)
- forest plots (Appendix J)
- a description of the methods and results of the cost-effectiveness analysis undertaken for the guideline (Appendix L).
Recommendations were drafted on the basis of the group’s interpretation of the available evidence, taking into account the balance of benefits, harms and costs between different courses of action. This was either done formally, in an economic model, or informally. Firstly, the net benefit over harm (clinical effectiveness) was considered, focusing on the critical outcomes, although most of the reviews in the guideline were outcome driven. When this was done informally, the group took into account the clinical benefits and harms when one intervention was compared with another. The assessment of net benefit was moderated by the importance placed on the outcomes (the group’s values and preferences), and the confidence the group had in the evidence (evidence quality). Secondly, the group assessed whether the net benefit justified any differences in costs.
When clinical and economic evidence was of poor quality, conflicting or absent, the group drafted recommendations based on their expert opinion. The considerations for making consensus-based recommendations include the balance between potential harms and benefits, the economic costs or implications compared with the economic benefits, current practices, recommendations made in other relevant guidelines, patient preferences and equality issues. The group also considered whether the uncertainty was sufficient to justify delaying making a recommendation to await further research, taking into account the potential harm of failing to make a clear recommendation.
The wording of recommendations was agreed by the group and focused on the following factors:
- the actions healthcare professionals need to take
- the information readers need to know
- the strength of the recommendation (for example the word ‘offer’ was used for strong recommendations and ‘consider’ for weak recommendations)
- the involvement of patients (and their carers if needed) in decisions about treatment and care
- consistency with NICE’s standard advice on recommendations about drugs, waiting times and ineffective intervention.
The main considerations specific to each recommendation are outlined in the ‘Recommendations and link to evidence’ sections within each chapter.
3.7.1. Research recommendations
When areas were identified for which evidence was lacking, the group considered making recommendations for future research according to the NICE process and methods guide for research recommendations. Decisions about inclusion were based on factors such as:
- the importance to patients or the population
- national priorities
- potential impact on the NHS and future NICE guidance
- ethical and technical feasibility.
3.7.2. Validation process
This guidance is subject to a 6-week public consultation and feedback as part of the quality assurance and peer review of the document. All comments received from registered stakeholders are responded to in turn and posted on the NICE website when the pre-publication check of the full guideline occurs.
3.7.3. Updating the guideline
Following publication, and in accordance with the NICE guidelines manual, NICE will undertake a review of whether the evidence base has progressed significantly to alter the guideline recommendations and warrant an update.
- Guideline development methodology - Faltering Growth – recognition and managemen...Guideline development methodology - Faltering Growth – recognition and management
- Glossary and abbreviations - Faltering Growth – recognition and managementGlossary and abbreviations - Faltering Growth – recognition and management
- Neonatal jaundiceNeonatal jaundice
- SRP161717 (1)SRA
- T-cell receptor gamma, partial [Danio rerio]T-cell receptor gamma, partial [Danio rerio]gi|65333957|gb|AAY42318.1|Protein
Your browsing activity is empty.
Activity recording is turned off.
See more...