If we are to establish whether or not screening for mental health problems in young people who offend is of benefit, a first step is to establish how accurate available screening assessments are in this population. This chapter examines the available evidence for the accuracy of different screening methods for a range of mental health problems in young people who offend. It also provides a summary of the available information on the prevalence of mental health problems according to the screening instruments identified by the review and the gold standard methods of establishing a diagnosis of a mental health problem.
Methods to assess diagnostic test accuracy
As described in Chapter 2, sensitivity and specificity are central concepts in understanding diagnostic test accuracy and are described in detail in Appendix 1, along with further information on methods of quantifying diagnostic performance.
Assessing the validity of mental health needs measures
In recognition of the argument that the presence of a diagnosis does not necessarily equate with the level of need in young people who offend,28 we reviewed studies of screening measures designed to establish the presence of a mental health need. For these types of studies it is not possible to apply the standard strategies of assessing diagnostic accuracy because there is no gold standard of ‘mental health need’ against which the identification of the mental health need screening instrument can be assessed. It is impossible, therefore, to create a 2 × 2 table and summarise the performance of the screening instrument in terms of characteristics such as sensitivity and specificity.
For these studies we assessed the extent to which the assessments of mental health need had established criterion-related validity. Validity refers to the extent to which an instrument measures what it is intended to measure.32 As applied to the question here, validity refers to whether or not a measure of mental health need in young people who offend does in fact measure the mental health needs of this group. Criterion-related validity assesses the validity of a measure by examining the extent to which it relates in ways we would expect it to relate to other measures of the same or different constructs. For example, if a mental health needs assessment is in fact a valid measure, we would expect it to relate to other indicators of mental health need, such as subsequent use of mental health services.
Rather than exclude all studies of mental health needs assessments that did not report the agreement of the measure against a gold standard diagnosis, for instruments for which we could not identify diagnostic test accuracy data we sought to include reports of validation studies that established the criterion-related validity of the mental health needs assessments.
Methods
This first phase of the review sought to answer two main questions:
For those screening measures reporting diagnostic status, what is their diagnostic accuracy?
For those screening measures identifying level of need, what evidence is there that these measures are valid indicators of mental health need?
In addition, we summarised the prevalence of mental health problems as identified by the screening instruments in these studies.
Inclusion/exclusion criteria
Two reviewers screened the titles and abstracts identified in the literature search for studies that were potentially eligible to be included in this phase of the review. Disagreements were resolved by consensus or deferred to a third party if necessary.
The PICO criteria for this stage of the review were:
Population and setting: young people (aged 10–21 years) who have offended and who are in contact with the criminal justice system.
Intervention: screening measures designed to identify one or more mental health diagnoses (see Diagnostic categories). Also included were measures that reported the presence of a mental health need. These can be brief screening measures or longer instruments. These types of measures were not diagnosis specific.
Reference: for studies reporting diagnostic accuracy, a standardised diagnostic interview conducted to internationally recognised criteria [e.g.
ICD-10 Classification of Mental and Behavioural Disorders26 or
Diagnostic and Statistical Manual of Mental Disorders (DSM)
27]. For studies reporting the assessment of mental health needs, some form of validation needs to have been performed. This would typically take the form of examining the association or level of agreement between the assessment of mental health needs and one or more other indicators of mental health need.
Outcome: details of the prevalence of one of the specific mental health diagnoses or mental health needs, details of the diagnostic accuracy of the measure or details of validity data for those measures reporting mental health need rather than diagnosis.
Study design: cross-sectional, case–control and cohort studies and randomised controlled trials (when screening measure was used as a method of recruitment).
When citations met the inclusion criteria but reported data on samples that overlapped with those in other included studies, we examined the citations to establish whether different information on diagnostic test accuracy was reported. If so, more than one citation was included, although this was treated as a single data set. In cases in which no additional data were reported, we retained the citation reporting the largest sample size.
Diagnostic categories
For the diagnostic accuracy studies we sought evidence for a range of diagnoses, which we broadly grouped into mood disorders (e.g. major depression, bipolar disorder), anxiety disorders (e.g. generalised anxiety, panic disorder, PTSD), behavioural disruptive disorders [ADHD, conduct disorder, oppositional defiant disorder (ODD)] and a miscellaneous ‘other’ category that included psychotic disorder, autistic spectrum disorder and self-harm/suicide.
Although self-harm and suicidal behaviour are not diagnoses, we sought evidence of the accuracy of screening measures for these because they are important mental health outcomes with an increased prevalence in young people who offend. Unlike the diagnostic categories, for which the gold standard is typically a structured clinical interview to establish the presence of a diagnosis, for self-harm/suicide we included studies that provided details of the accuracy of the self-harm/suicide screen in terms of future self-harm or suicidal behaviour. Studies that assessed the screening instrument against other outcomes, such as suicidal intent, were therefore excluded.
As described earlier, we also included measures that reported the presence of a mental health need.
Although particular measures developed in the UK are recommended as screening measures, we did not presuppose that these should be prioritised in the review.
Data extraction
All data were extracted independently by two reviewers using an agreed data extraction sheet. As with the detailed PICO criteria, the data extraction sheet was first piloted on full papers and refined through an iterative process.
Quality assessment
The quality of the included studies was assessed using the QUADAS-2 tool (Quality Assessment of Diagnostic Accuracy Studies – version 2).33 This tool examines four domains: patient selection, index test, reference standard, and flow and timing. The risk of bias is assessed for each of these domains. The first three of these also examine concerns about the applicability of the study to the review question.
The developers of the QUADAS-2 tool recommend that it is tailored to a review through the development of review-specific guidance. This may involve removing questions that are not applicable, adding additional questions that may be important quality assessment criteria for the specific subject area and providing details of how each criterion should be assessed and coded. In line with these recommendations, we developed a detailed guidance document for this review, which is given in full in Appendix 5.
We retained all of the risk of bias signalling questions and applicability questions. For the signalling question ‘Is the reference standard likely to correctly classify the target condition?’, we operationalised this as whether or not the researchers who conducted the gold standard interview had received appropriate training, had had their performance satisfactorily benchmarked or had rated well on inter-rater reliability tests. For the signalling question ‘Was there an appropriate interval between the index test and the reference standard?’, we defined an appropriate interval as < 2 weeks, in keeping with how this item has been applied in the evaluation of diagnostic test accuracy studies of mental health outcomes in previous versions of the QUADAS tool.34
The risk of bias in each domain was assessed as ‘high’, ‘low’ or ‘unclear’. Concerns regarding applicability in the first three domains were also assessed as ‘high’, ‘low’ or ‘unclear’.
Two reviewers independently rated the quality of the studies using the review-specific guidance. Disagreement was resolved by consensus and deferred to a third party when necessary.
Data synthesis
We produced a narrative synthesis of both the diagnostic accuracy studies and the assessment of the extent to which mental health needs screening measures are valid indicators of mental health needs in this population.
We summarised the results of the diagnostic studies in a descriptive manner. For studies that reported sufficient details to calculate 2 × 2 tables, we calculated sensitivity, specificity, positive likelihood ratios, negative likelihood ratios and diagnostic odds ratios (DORs) and their associated 95% confidence intervals (CIs). Analyses were conducted using Stata version 12 (StataCorp LP, College Station, TX, USA), with the diagti user-written command. For studies that reported information on diagnostic accuracy but which provided insufficient information to calculate a 2 × 2 table, we relied on the reports of sensitivity and specificity given in the study. There was an insufficient number of studies using the same screening measure for the same class of mental health outcomes to conduct a bivariate diagnostic meta-analysis.
Results
A total of nine studies including eight independent samples met our inclusion criteria.35–43 Two of the included studies38,43 reported data on samples that had some although not complete overlap with each other. The smaller of the two studies38 reported additional details of diagnostic accuracy not reported in the larger study.43 Specifically, Hayes et al.38 reported data on the performance of a voice-administered MAYSI-2, whereas the larger study by Wasserman et al.43 study reported data on a paper and pencil version alone. We therefore report the results of both studies, the larger study because of its greater size and the smaller study because of the additional information it contains on the performance of the voice-administered version of the MAYSI-2. An additional citation44 provided a summary of the results of the included Wasserman et al. study.43 All of the information contained in it was also included in the original report and so this citation was excluded. A further citation45 reported data on a subset of a sample reported in the included Kerig et al. study.39 It did not contain additional information on diagnostic test accuracy and so was also excluded in favour of the larger data set reported in Kerig et al.39
Eight of the nine studies reported data on the diagnostic test accuracy of one or more screening instrument.35,36,38–43 The remaining study reported data on the validity of a mental health needs assessment, which will be discussed separately.37
Diagnostic test accuracy results
Characteristics of the included studies
A summary of the characteristics of the eight diagnostic accuracy studies is given in .
Characteristics of the included studies
Setting and sample
The majority of the studies were conducted in the USA; other studies were conducted in the UK (n = 136) and the Netherlands (n = 142). Studies took place in a range of criminal justice settings.
Although the inclusion criteria for the review permitted samples aged between 10 and 21 years, most of the studies had a mean age of between 15 and 16 years old, with a narrow standard deviation. There was, then, a lack of representation of the diagnostic accuracy of screening instruments in the younger age group. Three of the eight studies reported data on an entirely male sample,35,36,42 in two studies the male-to-female ratio was approximately even38,41 and in three studies the male-to-female ratio was approximately 3 : 1.39,40,43 Although two of the studies used overlapping samples,38,43 the male-to-female ratio was approximately 1 : 1 in one study38 and 3 : 1 in the other.43 In the US studies the majority of the samples were made up of young people from a Caucasian or African American background. Ethnicity was not reported in the UK study.36 In the Dutch study the sample was made up of those from a range of ethnic backgrounds.42
Screening measures used in included studies
Four studies, including three independent samples, used the MAYSI-2 as the screening instrument.38–40,43 Kuo et al.40 also examined the Mood and Feelings Questionnaire (MFQ) and a short version of the MFQ46 in addition to the MAYSI-2. The remaining four studies each used a different screening instrument. A brief description of the screening measures used in the included studies is given below:
MAYSI-2. The MAYSI-2 tool is a screening tool designed to assist juvenile justice staff in the identification of young people aged 12–17 years who may have mental health problems.
10 The tool consists of a self-report inventory of 52 questions and produces seven separate scales that focus on different areas of concern (e.g. depressed, anxious, suicidal ideation). Youths circle ‘yes’ or ‘no’ concerning whether or not each item has been true for them ‘within the past few months’ on six of the scales and ‘ever in your whole life’ on one scale. Youths can read the items themselves (the tool has a fifth-grade reading level) and circle the answers or questions can be read aloud by juvenile justice staff. A further method of administration is via a CD-ROM on a computer; youths listen to the questions using headphones and answer the questions using the keyboard or a mouse. Administration and scoring takes about 10–15 minutes.
Diagnostic Interview Schedule for Children (DISC) Predictive Scales (DPS). The DPS are brief self-report measures designed to identify young people who are at increased risk of meeting diagnostic criteria for mental health difficulties.
47 The scales are derived from the DISC,
48 described in more detail in the following section, which is based on DSM criteria.
27 The scales consist of 56 items and enquire about difficulties over the last 12 months.
Minnesota Multiphasic Personality Inventory – Adolescent version (MMPI-A). The MMPI-A is a self-report measure derived from the MMPI designed for adults.
49 The objective of the measure is to identify psychopathology in adolescents. The adolescent version consists of 478 items and takes approximately 90 minutes to complete. The number of items and time taken for completion mean that such a measure is unlikely to be used as a screening instrument. However, we retained the study here for two reasons. First, we did not specify a maximum completion time as part of the inclusion criteria. Second, the MMPI consists of a number of subscales, which in principle could be used as screening instruments.
MFQ. The MFQ is a 33-item self-report measure based on DSM criteria
27 and designed to assess depressive symptoms in children and adolescents.
46 Items concern symptoms over the last 2 weeks and are rated as ‘not true’, ‘sometimes true’ and ‘true’. The short form of the questionnaire (Short MFQ) consists of 13 items from the full scale.
46 Prison Reception Health Screen. The Prison Reception Health Screen is a 15-item measure designed to be used at intake to detect physical health, mental health and substance use disorders.
36 Slightly different versions of the scale are used for males and females, and for young people an additional item is added to identify whether or not they have experienced a recent bereavement. The instrument is designed to be administered by prison health-care staff.
Youth Self-Report scale (YSR). The YSR is a standardised self-report measure for adolescents that is part of the family of measures developed by Achenbach,
50 with other measures designed for completion by parents and teachers. The scale was developed for completion by adolescents aged between 12 and 18 years. It is scored on scale from 0 (‘not true’) to 2 (‘very true’) and provides a summary of a young person’s emotional and behavioural problems over the last 6 months. The scale has eight syndrome scales (e.g. anxiety and depression, somatic complaints, social problems), with a ninth scale (self-destructive/identity problems) scored for boys only and three broad problem scales (internalising, externalising, total problem score).
Gold standard instruments used in included studies
The DISC48 was used as the gold standard in five studies, including four independent samples.38,40–43 Two studies35,36 used a version of the Schedule for Affective Disorders and Schizophrenia (SADS)51 and one study39 used the University of California at Los Angeles Post-Traumatic Stress Disorder Reaction Index (UCLA PTSD RI) – Adolescent version.52 These three diagnostic instruments are described in more detail below:
DISC. The DISC is a structured diagnostic interview to establish diagnoses for a range of mental health difficulties.
48 The interview uses a probe and follow-up format so that, if a young person answers positively to a probe question, further questions are asked to establish whether or not the person meets diagnostic criteria. The diagnoses identified by the DISC can be grouped into clusters (e.g. mood disorders, anxiety disorders, disruptive disorders). The interview takes approximately 60 minutes to complete but can be longer depending on the number of symptoms endorsed.
The interview can be delivered in a number of formats. In the standard format the interview is administered by a trained interviewer, a delivery format used in one of the included studies.
42 An alternative format is the Voice DISC in which the young person listens to pre-recorded questions on a headphone and gives his or her response to the spoken questions using a computer keyboard. Non-clinicians, with training in the interview and computer literacy, are able to administer the Voice DISC. Four of the included studies, including three independent samples, used this format.
38,40,41,43In the included studies, the accuracy of the screening instruments was typically assessed against clusters of diagnoses as determined by the DISC, including mood disorders, anxiety disorders and disruptive behavioural disorders (including ADHD).
SADS. The SADS
51 is a semistructured diagnostic interview for the diagnosis of affective and psychotic disorders in adults. Responses are rated on either a 4-point scale ranging from 1 (‘not at all’) to 4 (‘severe’) or a 6-point scale ranging from 1 (‘not at all’) to 6 (‘extreme’). It was developed before the development of DSM-III criteria and is instead based on Research Diagnostic Criteria (RDC); however, the degree of convergence between RDC and DSM diagnoses is high. The standard version asks about current mental health symptoms and the lifetime version (SADS-L) asks about previous episodes. The K-SADS-III-R (Schedule for Affective Disorders and Schizophrenia for School-Age Children) is a modified version of the SADS designed for use with children and adolescents (aged 6–18 years) and provides DSM-consistent diagnoses.
53 It uses the same 4-point and 6-point response format as the adult SADS.
UCLA PTSD RI – Adolescent version. The UCLA PTSD RI – Adolescent is a 48-item measure designed to assess DSM criteria for PTSD.
52 A DSM diagnosis of PTSD requires criterion A (presence of real or perceived threat to physical integrity), criterion B (re-experiencing of traumatic event), criterion C (avoidance) and criterion D (hyper-arousal) to be met. The UCLA PTSD RI follows this structure. The instrument can be used to determine whether a full or partial diagnosis of PTSD is likely; a full diagnosis requires each of criterion A, B, C and D to be met; a partial diagnosis requires criterion A to be met along with two out of three of criteria B, C and D. Although the UCLA PTSD RI does not provide a formal diagnosis, we included this as a gold standard measure because it maps closely onto a recognised diagnostic system (DSM) and has convergent validity with other established gold standard diagnostic systems such as the SADS.
Quality assessment of the included studies
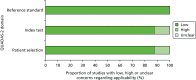
summarises the risk of bias individually for the eight included studies according to QUADAS-2 criteria and summarises the applicability criteria individually for the eight studies. and provide an overall summary of the risk of bias and applicability respectively.
Quality assessment of the included diagnostic test accuracy studies: risk of bias
Quality assessment of the included diagnostic test accuracy studies: applicability criteria
Overall risk of bias across QUADAS-2 domains for the included diagnostic test accuracy studies (n = 8).
The QUADAS-2 applicability criteria for the included diagnostic test accuracy studies (n = 8).
Patient selection
The patient selection domain assesses if the way in which participants were selected may have introduced a bias. Four studies, consisting of three independent samples, were rated as being at high risk of bias for this domain;38,40,42,43 the risk of bias was rated as low for two studies39,41 and unclear for the remaining two studies.35,36
Although all studies avoided a case–control design, some studies did not use random or consecutive sampling for recruiting participants and others were judged to have a high number of inappropriate exclusions. The absence of random or consecutive sampling could artificially either increase or decrease the observed performance of a screening instrument against a gold standard; the direction of the influence would be determined by the exact nature of the sampling procedure used. The same is true of the high number of inappropriate exclusions from the sample. Therefore, although there is some evidence of bias for the patient selection domain, it is unclear what effect this had on the observed diagnostic accuracy in the included studies.
Index test
The index test domain asks whether the conduct or interpretation of the screening test may have introduced a bias. The overall risk of bias for this domain was rated as high for two studies,39,40 unclear for three studies,35,36,42 and low for three studies, consisting of two independent samples.38,41,43
For some studies it was unclear if the index test was interpreted blind to the reference standard. Blinding is essential to ensure that knowledge of the results does not influence the scoring of the reference standard, which may artificially inflate the observed diagnostic test accuracy of the screening test. Some studies also failed to use a prespecified cut-off point on the index test. The post hoc selection of the cut-off point can capitalise on a chance finding and artificially inflate observed diagnostic test accuracy.
Reference standard
The reference standard domain assesses whether the gold standard used or the conduct or interpretation of the gold standard test may have introduced bias. The overall risk of bias for the reference standard domain was considered low for five studies,35,36,38,41,43 consisting of four independent samples, and unclear for three studies.39,40,42 The unclear ratings resulted from a lack of clear evidence that the diagnostic gold standard was conducted blind to the results of the index test. As with lack of blinding for the index test, this can also distort the observed diagnostic performance of the screening test.
Flow and timing
Six out of the eight studies,36,38,40–43 consisting of five independent samples, were rated as being at high risk of bias in terms of the flow and timing domain, which assesses whether or not the participant flow through a study and the timing of measurement may have introduced bias. The reasons for the rating of high risk for many of the studies were that not all participants received the reference standard and not all participants were included in the analysis. Participants included in the diagnostic test accuracy analysis may have differed in systematic ways from participants who were not included and this may distort the test accuracy.
Applicability criteria
summarises by individual study the extent to which the QUADAS-2 applicability criteria are met and provides an overall summary. The applicability criteria were broadly met for the patient selection and index test domains and entirely met for the reference standard domain. One study did not meet the criterion for index test applicability.35 As we describe earlier, this was because the study used the MMPI-A, a 458-item measure taking approximately 90 minutes to complete, which makes it unsuitable as a screening measure, although one or more subscales could feasibly be used to screen. One study did not meet the applicability criterion for patient selection.36 This was because the study recruited from a variety of adult and young offender institutions, although it was possible to extract some data for the young offender population and the results discussed later for that study are based solely on the young offender subgroup.
Summary
With the exception of the reference standard domain, for which a majority of studies had a low risk of bias, the risk of bias was either high or unclear for the majority of studies in the other three QUADAS-2 domains. No study was rated as being at low risk for all four domains. In contrast, applicability criteria were broadly met across all studies. The identified studies are therefore largely relevant to the diagnostic test accuracy question that this review seeks to answer but some caution is needed in relying on the diagnostic accuracy data reported by these studies because the level of potential bias across many QUADAS-2 domains was often unclear or high.
Results by diagnostic clusters
This section presents the diagnostic test accuracy of the included studies organised by broad diagnostic clusters. It also provides detail on the prevalence of the mental health problems as established by the screening instruments and gold standards in those samples reporting data for both types of assessment. There was an insufficient number of studies to conduct a diagnostic meta-analysis of the results for any of the broad diagnostic clusters; a narrative summary is instead given for all clusters.
When studies reported diagnostic accuracy data for multiple subscales of a measure, we report here those subscales that measure the same or a similar construct as that assessed by the gold standard. For example, Hayes et al.38 report diagnostic test accuracy data for a large number of subscales of the MAYSI-2 (alcohol/drug use, angry–irritable, depressed–anxious, somatic complaints, suicidal ideation, thought disturbance), each against mood, anxiety and disruptive clusters of the DISC. Rather than report each of the subscales against the mood disorder cluster, we report the depression–anxiety subscale because of its conceptual link with the gold standard diagnosis.
Mood disorders
Five studies, consisting of four independent samples, reported information on the diagnostic test accuracy of one or more screening instrument assessed against a gold standard diagnosis of a single mood disorder or a cluster of mood disorders.35,38,40,41,43
Prevalence
Kuo et al.40 used the MFQ and Short MFQ as a depression screen. The MFQ, using the literature standard cut-off point of 27, suggested a prevalence estimate of 24%; for the Short MFQ the figure was 42%. This compares with a prevalence figure of 14% for depression using the gold standard (Voice DISC).
McReynolds et al.41 reported data on the DPS. The prevalence of any affective disorder using the DPS was 20%. A young person was classified as having an affective disorder if he or she scored positive on any of the affective predictive subscales. The prevalence for the gold standard (Voice DISC) was 11.8% for any affective disorder.
The MAYSI-2 subscales group mood and anxiety difficulties into a single subscale (depression–anxiety); therefore, it is not possible to estimate the prevalence of solely mood disorders according to standard literature cut-off points on this instrument. The figures for the depression–anxiety subscale, using the ‘caution’ cut-off point, are 39% for the voice-administered MAYSI-238 and 35.0% for the paper and pencil-administered version of the test.43 The gold standard estimate of the prevalence of mood disorders according to the DISC affective disorder classification was 12.0% in Hayes et al.38 and 10.5% in Wasserman et al.43 Kuo et al.40 provide data on the prevalence of depression according to what they report as the MAYSI-2 depression scale, although it is unclear if this in fact refers to the depression–anxiety subscale of the MAYSI-2.
Prevalence figures according to the MMPI used in Cashel et al.35 are not given because of insufficient detail reported in that study.
Diagnostic test accuracy for mood disorders
Two studies reported diagnostic test accuracy data for major depression.35,40
summarises the performance of the screening measures in these studies. Limited data are presented in and subsequent tables for Cashel et al.35 because there was insufficient information reported in that study to calculate the 2 × 2 tables needed for the additional diagnostic test accuracy statistics.
Diagnostic test accuracy of screening measures against a gold standard for major depression
Kuo et al.40 reported literature standard cut-off points for the three screening measures examined in that study (MAYSI-2: 3; MFQ: 27; Short MFQ: 8) as well as a single alternative cut-off point for each measure. Some caution is needed in interpreting the alternative cut-off points because, unlike the literature standards that are predetermined, it is possible that the selection of these post hoc may capitalise on chance.
The sensitivity at the literature standard cut-off points for two of the instruments was in the range of 0.7–0.8, which may be unacceptably low for screening instruments because it would lead to a high proportion of people with major depression being missed. The results for the short form of the MFQ were more impressive, with a sensitivity of 1 and a specificity of approximately 0.7 at the two reported cut-off points. However, caution is needed in interpreting these results because of the small sample size and the low number of people with major depression, which means that any estimate of sensitivity is likely to be imprecise.
It is of note that, on the basis of the limited evidence presented here, the MAYSI-2, a measure designed specifically for use with young people who have offended, did not appear to have greater performance characteristics than more general measures. Although the cut-off point could be altered to increase sensitivity, this would further reduce specificity, which may lead to a high proportion of false positives. This would be problematic for the MAYSI-2, which already has low specificity at the ‘caution’ cut-off point; increasing sensitivity for this would further lower specificity and lead to a very high false positive rate.
Three studies, consisting of two independent samples, reported data on the diagnostic accuracy of screening instruments compared with a gold standard diagnosis of any affective disorder.38,41,43 All three used the DISC affective disorder cluster as the gold standard. summarises the results for these studies. The level of sensitivity for the MAYSI-2 at the literature standard cut-off of 3 (the ‘caution’ cut-off) was again not as high as would be ideal for use as a screening measure. The sensitivity of the DPS was even lower at the reported cut-off point, although this was paired with a higher specificity. It is unclear if altering the cut-off point to increase the sensitivity of the DPS would retain a sufficiently high specificity to limit the number of false positives.
Diagnostic test accuracy of screening measures against a gold standard for any depressive disorder
Summary
It is difficult to make any firm conclusions about the accuracy of screening instruments in identifying major depression or more broad affective disorder clusters as there were not enough studies estimating the accuracy of the same measures using the same cut-off points. However, on the basis of the available evidence, there is no clear indication that the performance of a measure designed specifically for use by young people who offend (MAYSI-2) is superior to that of more generic screening measures.
Anxiety disorders
Five studies, consisting of four independent samples, reported diagnostic test accuracy data on a single anxiety disorder or a cluster of anxiety disorders.35,38,39,41,43
Prevalence
In terms of single anxiety disorders, Kerig et al.39 report a range of cut-off points on the traumatic experience subscale of the MAYSI-2 separately for males and females. There is no established cut-off point on this scale but a score of ≥ 3 has been used for research purposes. The prevalence of PTSD symptoms according to a positive screen on the MAYSI-2 using this cut-off point was 34.4% for males and 39.1% for females. According to the UCLA PTSD RI – Adolescent scale, which is treated here as the gold standard, the prevalence was in fact higher (males 49.8%; females 59.6%). There were insufficient data reported in Cashel et al.35 to calculate prevalence estimates for generalised anxiety disorder according to the screening instrument or the gold standard instrument.
In the study by McReynolds et al.,41 the prevalence of anxiety disorders according to a positive score on any of the anxiety DPS was 65.6%. For the gold standard measure (DISC), the prevalence of any anxiety disorder ranged from 21.2% to 27.6% (see ).
Diagnostic test accuracy of screening measures against a gold standard for any anxiety disorder
Diagnostic test accuracy for anxiety disorders
Two studies reported data on the diagnostic performance of screening measures for a single anxiety disorder as established by a gold standard. Cashel et al.35 report data for generalised anxiety and Kerig et al.39 report data for full or partial PTSD. summarises the results of these two studies. Cashel et al.35 examined a number of MMPI-A scales as a screen for generalised anxiety disorder and reported a sensitivity of 0.73 and a specificity of 0.84. There were insufficient data reported in this study to extract a 2 × 2 table and so CIs and other diagnostic performance characteristics could not be calculated. As described earlier, there is no agreed cut-off point for the MAYSI-2 traumatic experience subscales, as used in Kerig et al.39 At the cut-off point of 3, which has been used for research purposes, the MAYSI-2 traumatic experience subscale had modest sensitivity and good specificity for both the males and females in the sample (see ).
Diagnostic test accuracy of screening measures against a gold standard for a single anxiety disorder
The same three studies that reported data on the diagnostic accuracy of screening measures for any depressive disorder (including two independent samples) also assessed their accuracy against a gold standard measure of ‘any anxiety disorder’.38,41,43 All three used the DISC anxiety disorder cluster as the gold standard. summarises the results for these studies. The Hayes et al.38 and Wasserman et al.43 studies, which had overlapping samples, reported modest sensitivity for the MAYSI-2 at the literature standard cut-off points, combined with modest specificity. The McReynolds et al.41 study used the DPS as the screening measure. Participants were scored positively if they scored above the cut-off on any of the anxiety scales. Sensitivity was very high (0.97, 95% CI 0.88 to 0.99) but this was combined with low specificity (0.44, 95% CI 0.36 to 0.52).
Summary
There were too few studies to conduct a diagnostic meta-analysis or make firm conclusions about the diagnostic performance of any of the instruments in the identification of anxiety disorders among young people who offend. As with the results for depressive disorders, there is not a clear indication that the MAYSI-2, a test specifically designed for young people who have offended, has superior operating characteristics relative to other more general screening instruments.
Disruptive disorders
Five studies,35,38,41–43 consisting of four independent samples, reported data on the diagnostic accuracy of screening instruments for disruptive disorders.
Prevalence
In terms of specific disruptive disorders, prevalence estimates could not be calculated for the Cashel et al.35 study because insufficient information was reported to carry out the calculations. The prevalence of ADHD according to the acceptable sensitivity cut-off point of the attention deficit hyperactivity (ADH) subscale of the YSR was 53.1% in Vreugdenhil et al.;42 the prevalence according to the gold standard (DISC) was 8%. Vreugdenhil et al.42 also report data on ODD. If the aggressive subscale of the YSR is used to estimate the prevalence of ODD it suggests a figure of 85.7%; when the externalising subscale is used the figure is 53.1%. The gold standard suggests a figure of 14%.
The prevalence of any disruptive disorder according to the angry–irritable subscale (cut-off 5) of the MAYSI-2 (voice version) was 44.7% according to Hayes et al.38 For the paper and pencil version, the figure was 38.5%.43 McReynolds et al.41 used the DPS as the screening instrument; a positive score on any of the disruptive scales gave a prevalence estimate of any disruptive disorder of 51.3%. Gold standard estimates for the three studies, all of which used the DISC as the gold standard, ranged from 28.6%43 to 39%,38 although these two studies had overlapping samples.
Diagnostic test accuracy for disruptive disorders
Two studies report separate accuracy estimates for specific disruptive disorders: Cashel et al.35 provide data for ADHD and conduct disorder; Vreugdenhil et al.42 report data for ADHD and ODD (). For the study by Cashel et al.,35 as with the description of the results for anxiety and depressive disorders, the reported diagnostic information for disruptive disorders is limited to that given in the paper, because there was insufficient information to extract 2 × 2 tables. Cashel et al.35 used various MMPI scales to screen for ADHD and conduct disorder against the gold standard K-SADS-III-R. Although the results for conduct disorder suggested a combination of modest sensitivity and specificity, the results for ADHD were somewhat higher (sensitivity 0.77; specificity 0.84) (see ).
Diagnostic test accuracy of screening measures against a gold standard for specific disruptive disorders
The same three studies that reported data on the diagnostic accuracy of screening measures for any depressive disorder and any anxiety disorder (consisting of two independent samples) also assessed their accuracy against a DISC diagnosis of any disruptive disorder.38,41,43
summarises the results for these studies. As with the results for anxiety and depression, the MAYSI-2 reported modest sensitivity and specificity for the prediction of any disruptive disorder. The McReynolds et al.41 study reported good sensitivity (0.89, 95% CI 0.79 to 0.96) and modest specificity (0.67, 95% CI 0.58 to 0.75) for the DPS. In this study, participants were scored positively if they scored above the cut-off on any of the disruptive scales.
Diagnostic test accuracy of screening measures against a gold standard for any disruptive disorder
Summary
The results for disruptive disorders are similar to those for anxiety and depressive disorders. There were too few studies to make firm conclusions about the diagnostic test accuracy of any screening measure, and the results for the MAYSI-2 indicated a combination of modest sensitivity and modest specificity.
Other mental health problems
In addition to mood disorders, anxiety disorders and disruptive disorders, we searched for evidence on the diagnostic accuracy of screening measures for a number of additional mental health problems, including psychosis and autistic spectrum disorders. We also searched for studies examining the capacity of screening measures to identify subsequent self-harm and suicidal behaviour. We found no studies that met inclusion criteria for these mental health problems.
The study by Grubin et al.36 met inclusion criteria but has not been discussed so far because the outcome of interest was ‘any mental health condition’, rather than a specific disorder or cluster of disorders as used in this chapter to group studies.
Grubin et al.36 examined the effectiveness of ‘new prison reception health screening arrangements’ in identifying physical and mental health needs at 10 prisons in the UK, of which two were young offenders institutions housing young men aged 18–21 years. Young women aged 16–21 years were also included in the study; however, it was not possible to extract data separately for the young women and so data reported here are for the sample of young men only.
The health screening instrument contained 15 basic screening questions and was administered on reception to the facility. At each prison diagnostic interviews were carried out with a random sample of 15 prisoners using the SADS-L. Validation data were therefore available for 30 young male offenders from the two young offender institutions. Although the study report contains sufficient data to extract a 2 × 2 table, data are not reported here on sensitivity and specificity because only two young people met criteria for a mental health problem, which makes it difficult to provide a meaningful estimate of sensitivity.
Validity of the mental health needs assessment results
Some screening measures for mental health problems in young people who offend do not provide sensitivity and specificity against a gold standard diagnosis; instead, they aim to identify a ‘mental health need’. For any screening measure described as a mental health needs assessment and for which there were no diagnostic test accuracy data available, we sought validation studies of that screen as a measure of mental health need. As described in more detail earlier, for inclusion studies had to provide evidence of some form of criterion-related validity for a mental health need.
Although there are a number of screening measures that are designed to identify mental health needs in young people who offend, including a number developed in the UK, we identified only one study that met inclusion criteria.37
Haapanen and Steiner37 assessed the performance of a battery of tools termed the Mental Health and Substance Abuse Treatment Needs Assessment. Although this battery of tests includes some measures for which there exist diagnostic test accuracy data, such as the MAYSI-2, we included this study because it was the entire battery of tests that was designed to assess mental health needs. The full battery consisted of the Achenbach Child Behavior Checklist – YSR, the MAYSI-2, the Weinberger Adjustment Inventory and the Drug Experience Questionnaire. Paper and pencil versions of the test were used.
The sample consisted of 836 young people who were all committed to the California Youth Authority, which deals with young people who have committed very serious crimes, who have a substantial criminal history or who have failed at local interventions. In total, 79.4% of the sample was male. The average age of the sample was described as 16–17 years and the ethnicity of the sample was described as predominantly Hispanic or African American. Further details about ethnicity were not given. Validation of this combined mental health assessment was based on a case-note review, which was used to establish whether the young people were offered mental health treatment, were offered psychopharmacological treatments or were identified as requiring treatment but treatment was not provided. The level of reporting of the results is limited and the results are largely descriptive. In general, however, the authors state that elevated scores on instruments such as the MAYSI-2 and YSR were related to an increased use of mental health services or need for such services, at least for the male sample.
Although the search identified a number of studies reporting data on measures used as part of the Asset screening pathway in the UK [e.g. Asset, Screening Questionnaire Interview for Adolescents (SQiFA), SIfA], none of the studies met our inclusion criteria for establishing the criterion validity of the screening measure against other measures of mental health need. For example, validity data are reported for the Asset instrument54 but, as this instrument is designed primarily to identify the factors contributing to a young person’s offending, the validation was against indices of reoffending rather than mental health need.
Another report described a number of studies, one of which examined the use of the Salford Needs Assessment Scale for Adolescents (SNASA) in 301 young people who had offended and also interviewed the case managers of the sample to enquire about needs.4 However, after discussion we concluded that this comparator – the views of case managers – did not constitute adequate evidence of criterion-related validity. A further citation reported data on the reliability of the SNASA but did not report data directly relevant to assessing criterion-related validity.55
It should be recognised, however, that our search strategy may have missed important studies in this respect. For a study to be identified, it had to mention the measure in the title or abstract along with information about validity. It is possible that studies may contain information relevant to establishing the validity of a measure without the measure being referred to in the title and abstract. For example, studies that used one of the mental health needs assessments as the outcome measure in a trial would provide evidence relevant to establishing criterion-related validity, but such studies would not necessarily be identified as part of the search if the measure was not referred to in the abstract. For example, the SNASA was used as an outcome measure in a trial identified as part of the clinical effectiveness review.56 Full details of this study are given in Chapter 6. In brief, the SNASA was used in a trial of cognitive–behavioural therapy (CBT) compared with treatment as usual, with the intervention designed to improve a range of mental health outcomes, including depression and anxiety symptoms. Outcome was assessed at 11 months’ follow-up. The two groups appeared to be broadly comparable at follow-up on the SNASA [CBT group (n = 18): mean 10.5, standard deviation (SD) 3.54)]; treatment as usual group (n = 20): mean 10.75, SD 4.0]. Evidence for criterion-related validity would have required lower scores at follow-up in the CBT group. However, the absence of such a relationship and its implications for understanding the validity of the SNASA should be treated with caution given the small sample size.
Summary
There were too few studies to make any firm conclusions about the diagnostic test accuracy of any of the screening measures examined in this review. Ideally, a conclusion about a particular screening measure would require a large number of studies reporting diagnostic performance at a range of cut-off points. This would allow the calculation of pooled estimates of sensitivity, specificity and other indices of test accuracy. It would also allow the examination of potential sources of heterogeneity in observed test accuracy across studies.
It is also difficult to draw conclusions about the comparative performance of different screening methods, even though some studies examined the performance of more than one measure in the same sample. Studies did not typically compare the performance of the measures across the full range of potential cut-off points. In some cases the reported performance of one measure had a particular balance between sensitivity and specificity whereas another measure had a different balance. It is unclear how the two measures would compare at cut-off points that attempted to give broadly the same balance (e.g. reasonably high sensitivity combined with acceptable specificity).
As discussed in Chapter 2, in which the decision problem was outlined, one of the aims of screening may be to detect previously unidentified cases. The diagnostic test accuracy data reported by the studies included in this review did not appear to differentiate between previously identified and unidentified cases. It is unclear, therefore, how the reported accuracy would be altered if the analysis was restricted to previously unidentified cases.
Any conclusions about the diagnostic performance of screening measures in populations of young people who have offended are, therefore, necessarily tentative. One potential conclusion is that there is no clear evidence that the MAYSI-2, a test specifically designed for use in this population, has superior operating characteristics to those of other general measures. More generally, the reported literature standard cut-off points for the MAYSI-2 and other instruments suggest a combination of both moderate sensitivity and moderate specificity, and so altering the cut-off point to increase sensitivity may lead to unacceptably low specificity.
One of the objectives of the review was to establish in which groups of young offenders screening may be of use. There were too few studies to make any firm conclusions about such groups, for example community compared with incarcerated settings or particular diagnostic subgroups. However, data were identified on screening accuracy for some mental health problems, including depression, PTSD, ADHD, conduct disorder and ODD. These disorders are therefore candidates for use as exemplars in the decision model.
Reflections on policy and practice
Although current UK policy recommends screening for mental health problems in young people who offend, there is currently a limited evidence base examining the diagnostic test accuracy of available screening measures.
There also appears to be limited validation of mental health needs assessments. Although this information would be useful, it is not immediately clear how it could be used to inform decision-making in terms of the clinical effectiveness and cost-effectiveness of a screening strategy, because this typically requires sufficient data to calculate sensitivity and specificity against a gold standard.
The majority of the diagnostic test accuracy studies were conducted in the USA; only one was conducted in the UK. Furthermore, many of the studies were conducted in incarcerated settings. In the UK, in contrast, most young people who offend are managed in the community. The existing literature – already limited in terms of the number and quality of studies – may therefore be further limited by the extent to which the findings can be generalised to UK settings.