This chapter considers questions surrounding the appropriateness of the statistical analyses. After a brief review of the relevant literature, 19 questions were explored. The results are summarised and discussed.
Introduction
Outcome reporting bias has been widely reported.10,11,27,80–87 However, only a few papers have reported on whether or not researchers adequately specify planned analyses in the protocol and, subsequently, whether or not they follow the prespecified analysis.88,89 This matters because failure to follow the prespecified analysis can result in bias. One study suggested that protocols were not sufficiently precise to identify deviations from planned analyses.89 Two reviewed whether or not sample size calculations were adequately specified.88–90 Another recently questioned whether or not the current method of sample size calculations was appropriate.91 These are summarised below.
The primary outcomes in protocols were compared with those in published reports for 102 trials approved by the scientific ethics committees for Copenhagen and Frederiksberg, Denmark, between 1994 and 1995.10 Selective reporting was revealed, with 62% of trials reviewed having at least one primary outcome added, omitted or changed.
A similar review of 48 trials funded by the Canadian Institutes for Health Research81 found that in 33% of trials, the outcome listed as primary in the publication differed from that in the protocol. They also found that outcome results were incompletely reported.
A pilot study conducted in 2000 reviewed 15 applications received by a single local research ethics committee in the 1990s and compared the outcomes, analysis and sample size in the protocol with that presented in the final study report.89 The authors found that six protocols (40%) stated the primary outcome and, of these, four (67%) matched that in the published report. Eight mentioned an analysis plan but only one (12%) followed its prescribed plan. The study concluded that selective reporting may be substantial but that bias could only be broadly identified as protocols were not sufficiently precise.
In 2008, Chan et al.88 compared the statistical analysis and sample size calculations specified in the protocol with those specified in the published paper. They found evidence of discrepancies in the sample size calculations (18/34 trials), the methods of handling protocol deviations (18/34 trials), methods of handling missing data (39/49 trials), primary outcome analyses (25/42 trials), subgroup analyses (25/25 trials) and adjusted analyses (23/28 trials). These discrepancies could affect the reliability of results, introduce bias and indicate selective reporting. They concluded that the reliability of trial reports cannot be assessed without access to the protocol.
A 2008 comparison of the sample size calculation specified in the protocol with that in the publication found that only 11 of the 62 trials reviewed adequately described the sample size calculation in both the protocol and published report.88
Charles et al.,90 in a review of the reporting of sample size calculations in 215 trials published between 2005 and 2006, found that 43% did not report all the required sample size calculation parameters.
A study of 18 trials that reported on traumatic brain injury reviewed the covariates adjusted for and subgroup analyses performed.92 Protocols could be obtained for 6 of the 18 trials and it found that all six trials reported subgroup effects which differed from those specified in their protocols.
In collaboration with journal editors, triallists, methodologists and ethicists, Chan et al.93,94 have launched the Standard Protocol Items for Randomised Trials (SPIRIT) initiative to establish evidence-based recommendations for the key content of trial protocols.
The above studies may not reflect current practice because either the number of trials reviewed was small or the studies reviewed were relatively old (1994–5 for Chan88 and similar for Hahn89). Practice may have improved since, following the introduction of CONSORT and other guidelines.
Our objective was to repeat these analyses on the cohort of all HTA published RCTs, assessing the extent of these discrepancies and whether or not they improved over time.
Questions addressed
The aim was to review the appropriateness of the statistical analyses for all published HTA clinical trials, including the sufficiency of the proposed statistical plan, handling of missing data and whether or not there were discrepancies between what was proposed and what was actually reported in the published monograph.
The questions posed (Box 6) fall under the following six subheadings:

The actual research questions answered under this theme Did the protocol specify the planned method of analysis for the primary outcome in sufficient detail? In relation to:
Did the protocol specify the planned method of analysis for the primary outcome in sufficient detail?
Was the analysis planned in the proposal/protocol for the primary outcome carried out?
How was the sample size estimated?
How adequate was the reporting of planned and actual subgroup analysis?
Other information: what graphical presentation of data was reported in HTA trials?
Were conclusions justified given the analysis results?
Methods
Nineteen questions were piloted as shown in Box 6. Four questions were considered but not proceeded with, regarding:
the number of statistical tests and number of primary statistical tests
whether or not authors measured more outcomes than they reported
adequate reporting of subgroup analyses
whether or not the conclusions were justified given the analysis results.
Difficulties arose with each of these questions. Firstly, results were not presented in a standard format in the monographs. Secondly, as the monographs were lengthy, data extraction meant searching and reading through many pages. Thirdly, as the HTA trials are pragmatic, they include a large number of outcomes measured at multiple time points, which increased the number of tables/amount of text to be reviewed. Fourthly, extracting information on subgroup analyses planned and carried out was difficult because authors seldomly labelled analyses as subgroup analyses. Lastly, we found it difficult to specify data that could answer the question regarding the conclusions being justified by the analyses.
For the 19 questions explored, the methods used in the literature reviewed above were used as a framework to detail the questions. For example, the paper by Chan et al.88 provided the key components of data that needed to be extracted on the sample size calculation. Data on these components were expanded to include other types of outcome measures and study designs (e.g. time-to-event data, non-inferiority and cluster randomised trials). We extracted these data from the protocol or project proposal (if a protocol was not available) and monograph, and analysed the data in a similar way.
Denominators
All trials were included (n = 125). The unit of analysis for questions T4.1–T4.15 was each trial’s primary outcome with complete analysis (n = 164 planned and n = 161 reported). The unit of analysis for T4.16–T4.18 was the individual trial.
Results
Questions T4.1–T4.10: did the protocol specify the planned method of analysis for the primary outcome in sufficient detail?
Question T4.1: how many specified a method of analysis for the primary outcome?
The 125 trials included 206 planned primary outcomes and reported on 232 primary outcomes. Of these, 164 and 161, respectively, were ‘complete for analysis’ (these are the denominators for questions T4.1–T4.10).
The method of analysis was prespecified for 111 out of 164 planned primary outcomes (67.7%), with little difference between those that did and did not have protocols (65.9%, 54/82 from the proposal and 69.5%, 57/82 from the protocol) ().
Planned primary outcome analysis specified in the protocol/proposal by whether or not a protocol was available
Question T4.2: has this improved over time?
There is a slight indication that the specification of the primary outcome analyses has improved over time. This could be due to the increasing number of protocols available ( and ) but the low numbers preclude strong conclusions.
Planned primary outcome analysis specified in protocol/proposal by year
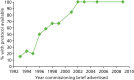
Proportion of trials with a protocol available by year of commissioning brief.
Question T4.3: statistical test applied
Of the 111 planned primary outcomes with a prespecified method, the proposed statistical test/choice of model was described in 108 (96.4%). The most frequently reported planned methods of analysis were logistic regression (23.4%, 26/111) and analysis of covariance (ANCOVA)/linear regression (17.1%, 19/111), followed by t-test (14.4%, 16/111) ().
Components of the analysis of the primary outcome reported in the protocol/proposal and monograph
Question T4.4: significance level
Of the 111 primary outcomes with a specified method of analysis, the significance level/confidence interval level to be used was specified in 39 (35.1%). shows that the most commonly used level of statistical significance was 5%.
Question T4.5: hypothesis testing
The majority did not specify whether one-sided or two-sided analysis would be performed (87.4%, 97/111) (see ).
Question T4.6: adjustment for covariates
Sixty-eight of the 111 (61.3%) planned primary outcomes specified the covariates that they planned to adjust for in the final analysis.
Question T4.7: analysis population
The planned population for the primary analysis was not specified by 41.4% (46/111). This appears to have improved over time (apart from anomalies in 1998 and 2003), with a big increase in 1996, the year in which CONSORT was published.
Question T4.8: adjustment for multiple testing
Almost all studies failed to specify a method of adjustment for multiple testing (93.7%, 104/111). As HTA trials are pragmatic as opposed to licensing trials, looking at a range of outcomes over short- and long-term periods, adjustment for multiple testing may matter less than transparency.
Question T4.9: missing data
Most studies did not specify a method for handling missing data (74.8%, 83/111). Of those that did, the methods used varied (see ).
Question T4.10: is sufficient detail including all of the above seven elements recorded in the protocol?
The number of protocols meeting all seven criteria was low, at 1.8% (2/111). When we limited the criteria to three (model/test, significance level and analysis population), of the 111 primary outcomes for which a method of analysis was specified in the protocol/proposal, 30 primary outcomes qualified (27%, 30/111). This increased slightly over time, from 22.7% before 1998 to 35.6% after.
Questions T4.11–T4.15: was the analysis planned in the protocol/proposal for the primary outcome carried out?
Question T4.11: statistical test/model used
Of the 82 trials whose primary outcome was as planned, the authors changed the planned method of statistical analysis (model/test) in 20 (24.4%). Some changed to more complex methods (t-test changed to linear regression in five instances) and others to simpler methods (in three, a chi-squared test was carried out instead of logistic regression, linear regression was used instead of a mixed model and Fisher’s exact test was used instead of Cox proportional hazards). These could be legitimate changes or selective reporting depending on the results, something we did not explore (examples are given in Box 7).
Examples of discrepancies between statistical test/model planned in the protocol/proposal and used in the monograph In three trials (ID131, ID132 and ID133) reported in one monograph, the authors stated in the protocol that they would analyse the primary (more...)
Question T4.12: significance level
All but six trials used the 5% significance level. Of the six discrepancies between the significance stated in the protocol/proposal and that used in the monograph, one led to an increase in the significance level used but this seems to be an error (trial ID42 stated in the protocol that ‘Differences will be judged significant at the 2.5% level to take account of two primary comparisons being drawn’; the monograph stated that 95% confidence intervals would be calculated but a 2.5% significance level was stated in the sample size calculation in the protocol.
Question T4.13: analysis population
Of those trials that stated the planned analysis population for the primary outcome analysis in the protocol/proposal, 90% (56/62) followed the plan. Most carried out what they described as an ‘intention-to-treat’ analysis. In two trials, the triallists stated in the protocol/proposal that they would carry out both an intention-to-treat and per-protocol analysis but reported only on the per-protocol analysis. Both of these were from trial ID109, where ‘The data were analysed per protocol. As planned, no intention-to-treat analyses were conducted, as < 10% of subjects would have been classified differently in such an analysis.’ Therefore, this change of analysis population was justified because the authors had specified in the protocol a rule which was used to decide which population to use.
Question T4.14: missing data
Of the 28 trials for which a method of handling missing data was specified in the protocol, the method used was different in 12 (42.9%).
Question T4.15: covariates adjusted for in the analysis
Sixty-eight of the 111 trials (61.3%) outlined their planned analysis of covariates and for 31 (27.9%) it was unclear (). Some trials did not specify which covariates they would adjust for in the protocol or, if they did, they failed to specify exactly which covariates would be adjusted for, for example ‘adjusting for baseline variables’ or ‘taking into account any statistically important imbalances’. This made it difficult to compare planned covariates with actual covariates adjusted for, in many trials.
Examples of discrepancies between covariates which trials planned to adjust for and those actually adjusted for as specified in the monograph
In summary, the analyses planned in the proposal/protocol for the primary outcome were carried out in 68 of the 82 trials (76%) and changed in 20 (24%) (considering statistical test/model only). The method of handling missing data specified in the protocol/proposal did not match what was carried out 43% of the time. The analysis population and significance level changed 10% of the time in trials. More detailed examination suggests that some of the changes were legitimate. Without knowing if a statistical analysis plan was drawn up before the analysis and subsequently followed, one cannot conclude departures from proper practice.
Questions T4.16–T4.18: how was the sample size estimated (power, confidence interval, etc.)?
We followed the methods and tables used by Chan et al.,88 expanded to incorporate the different types of sample size calculation observed in the HTA trials (e.g. width of confidence interval calculations, time-to-event data, standardised effect size, non-inferiority, equivalence).
Question T4.16: was sufficient information on the sample size calculation provided?
The results of classifying the trials by the five components suggested by Chan et al.88 are shown in . Of the 125 trials, 75 proposals/protocols (60%) and 66 monographs (52.8%) reported all the required sample size components. Individual components were reported in 60.7–100% of proposals/protocols and 49.6–100% of monographs. The required sample size was reported in the proposal/protocol in 93% of trials (116/125), in the monograph in 90% (112/125) and in both in 89%. The result from the sample size calculation was presented in the proposal/protocol in 57% of trials (111/125), in the monograph in 46% (58/125) and in both in 42% (e.g. the sample size calculation showed that the trial will have to recruit 326 participants. Taking account of the participant dropout rate, this will increase the number needed per arm to 350). Forty-two per cent of trials (52/125) reported all the required components of the sample size calculation in both the proposal/protocol and monograph.
Reporting of sample size calculation components in the proposal/protocol and monograph
Question T4.17: does the sample size calculation in the protocol match the sample size calculation shown in the monograph? What discrepancies were found?
Of the 117 trials reporting a sample size calculation in both the proposal/protocol and the monograph, we observed discrepancies between that planned and that reported in 45 trials (38.5%). A component of the sample size calculation was reported in the monograph but not reported in the protocol/proposal in 18 trials. In 39 trials, there was a discrepancy in at least one component reported in both the protocol/proposal and the monograph. These discrepancies were not acknowledged in the monograph. Where a discrepancy was observed between the number of patients, the trial planned to recruit and the number actually recruited, this was twice as likely to be because the number specified in the monograph was smaller than that in the protocol/proposal than vice versa (19 trials vs. 10 trials). Where a discrepancy existed in the minimum clinically important effect size, this was also almost twice as likely to be due to the effect size being reported as larger in the monograph than in the protocol (). These discrepancies could be due to reductions in the planned sample size after the study started which were not reported in the monograph, or attempts to justify the fewer patients actually recruited.
Discrepancies in sample size calculation information reported in the proposal/protocol and monograph
Question T4.18: what values of alpha, power and dropout were used in the sample size calculation?
In the proposal/protocol, a 5% significance level was used in the sample size calculation 94.4% of the time (102/108). Eighty per cent power was specified in half of the protocols (52.2%, 59/113) and 90% power was specified in over one-third (37.1%, 42/113). The triallists inflated the sample size for participant loss to follow-up 61.5% of the time (72/122) in the protocol/proposal and 48.3% of the time (58/120) in the monograph ().
Sample size calculations reported in the protocol/proposal and monograph
Question T4.19: other information – what graphical presentation of data was reported in Health Technology Assessment trials?
We reviewed each HTA monograph and assessed whether it included a repeated measures plot, a Kaplan–Meier plot or a forest plot, as these were the top reported figures in Pocock et al.95 (accounting for 92% of figures published in the 77 RCT reports that they reviewed in five general medical journals). A repeated measures plot was presented in the HTA monograph for 38.4% of the trials (48/125), followed in frequency by a Kaplan–Meier plot (20%, 25/125) and a forest plot (16.8%, 21/125) (). A repeated measures plot was observed more frequently in the HTA monographs than in Pocock et al.’s95 sample, and a Kaplan–Meier plot less often. This could be due to differences in the types of trials reviewed, with HTA trials more likely to involve a longer follow-up at multiple time points and less likely to include survival outcomes.
Graphical presentation of data in HTA monographs compared with reports reviewed in the study by Pocock et al.
Analysis
The planned method of analysis for the primary outcome was not specified in the protocol/proposal in one-third of the 125 trials. Of those that specified a method of analysis, only two (1.8%) fully specified the method of analysis using the six core criteria. Twenty-seven per cent met three criteria (statistical test/model, significance level and analysis population). Improvements occurred over time from 22.7% before 1998 to 35.6% thereafter. There did not appear to be differences in the level of detail reported in the protocol compared with the proposal, but this could be due to small numbers or confounding (with the year the commissioning brief was advertised).
Out of the 125 trials reviewed, only 52 (41.6%) reported all the required components of the sample size calculation in both the proposal/protocol and monograph. Of these, the information in the proposal/protocol matched the information in the monograph in only 43 trials (34%) (see and ). Where discrepancies were observed, they were twice as likely to indicate a smaller sample size planned in the monograph than stated as planned in the protocol.
Discussion
We were able to extract data to answer a number of questions on the planned and actual method of statistical analysis and sample size calculation. The degree to which this study was successful varied by the three broad sets of questions:
Questions T4.1–T4.10: did the protocol specify the planned method of analysis for the primary outcome in sufficient detail? The study indicated that this set of questions could be answered and indicated some cause for concern as around one-third of trials provided insufficient detail, particularly on planned statistical analysis.
Questions T4.11–T4.15: was the analysis planned in the proposal/protocol for the primary outcome carried out? We showed that it was difficult to complete this set of questions owing to lack of data.
Questions T4.16 and T4.17: was sufficient information on the sample size calculation provided? And does the sample size calculation in the protocol match the sample size calculation shown in the monograph? What discrepancies were found? The study showed that it was difficult to complete this set of questions owing to lack of data.
One general finding from this study relates to the limitation of retrospective analysis. Standards changed over time. We were unable to discuss details with those responsible for the analyses in the trials. In particular, we had no way of knowing if statistical analysis plans had been drawn up separately from the protocol. We understand that such plans are common practice but often not until the trial is close to completion. The key issue is that such plans are specified in advance before the data are examined. We have no way of knowing if this happened.
This is the first study we are aware of that has reviewed whether or not the method of statistical analysis was recorded in sufficient detail in the protocol, as defined by a minimum set of criteria.
Sample size calculation is a vitally important aspect of any clinical trial to ensure that the number of patients included is large enough to answer the question reliably and as few patients as possible are exposed to a potentially inferior treatment. It is important that all parameters used in the sample size calculation(s) are clearly and accurately reported in both the grant proposal/protocol and final trial publication. The level of detail reported should enable another statistician to replicate the sample size calculation if necessary. The sample size calculation reported in the final trial protocol and final publication should match and any changes to the sample size that were made after the trial had started should be reported.
We found that sample size calculation information was not being recorded in sufficient detail in both the protocol and publication for RCTs. Where the information was recorded, the level of unexplained discrepancies was surprisingly high. Changes to the sample size calculation after a trial has started are allowed for much the same reasons as listed in relation to changes to the statistical analysis plan [e.g. advances in knowledge, change in trial design or better understanding of the trial data (SD or control group event rate)], but should be minimised as much as possible.
We observed fewer discrepancies than other studies with regard to the method of statistical analyses and whether or not the authors followed the protocol or the sample size calculations. The discrepancies observed could be legitimate changes not reported in the monograph or could be hiding unacknowledged reductions in the sample size carried out after the trial started due to recruitment problems (reported in Chapter 6), or they could be evidence of selective reporting bias indicating the results to be more clinically meaningful than they were (e.g. by increasing clinically meaningful difference specified) or typographical mistakes. Of these, given the large number of trials which failed to recruit the original planned sample size as reported in Chapter 6, we think the most likely explanations are the first two listed above.
Questions T4.11–T4.15 explored potential selective reporting. We found that potential selective reporting bias in sample size calculation information and in methods of analysis exists. This is perhaps not so serious, as a previous review of a subset of the RCTs in this cohort found that only 24% of primary outcome results were statistically significant.5 If there was selective reporting bias we might expect this percentage to be higher.
Chan et al.88 found that the statistical test for primary outcome measures differed between the protocol and publication in 60% of trials; we found a smaller percentage in our cohort of 25%. This could be because we had access to the final version of the protocol whereas Chan et al.88 had access to the protocol submitted to an ethics committee. In addition, Chan et al.88 studied protocols from the 1994–5 period, before CONSORT had been developed (in 1996). Chan et al.88 observed that 32.6% of protocols described the planned method of handling missing data, higher than our finding of 25.2%.
Chan et al.88 found that 11 out of 62 trials (17.7%) fully and consistently reported all of the requisite components of the sample size calculation in both the protocol and publication. The corresponding figure in our sample was 34%; this is twice as large as in Chan et al.88 but is still much lower than expected.
We found a similar proportion of trials reporting all the required sample size calculation parameters as Charles et al..90 Charles found that 57% of 206 trials reported all the required sample size calculation parameters; we found that 56.4% of our trials did so.
The figures in the paper by Hahn et al.89 are similar to ours, although their studies were few and dated.
Strengths and weaknesses of the study
The biggest strength of this study was that we had access to a protocol/proposal for all the trials. This is the largest cohort study that we are aware of to have compared the method of analysis and sample size calculation planned in the protocol with that reported in a publication. This is also the first such study of UK-funded RCTs. Further, previous studies comparing protocols with publications may not reflect current practice because either the number of trials reviewed was small or the studies reviewed were relatively old (1994–5 for Chan et al.88 and similar for Hahn et al.89).
A limitation of our work was that we only analysed the first sample size calculation reported and compared that with the monograph.
We were surprised at the lack of detail in statistical analysis plans reported in the protocol/proposal and how few met our criteria. However, as statisticians often create statistical analysis plans separate from the protocol prior to final analysis, these may well provide more detail.
Key questions for the HTA programme concern whether or not it requires audit of planned analyses and, if so, how and at what level of detail. Our study shows the limits of retrospective audit based on the protocol/application form and the monograph. More generally, the HTA programme should consider requiring information to be recorded on the statistical test/model planned for use in the analysis, the significance level/confidence interval level to be used and the analysis population.
Recommendations for future work
Should the database be continued, we recommend that the questions on statistical analysis are reviewed alongside the SPIRIT checklist.94 Any further data extraction should include 13 questions: four should remain as they are (T4.1, T4.2, T4.18 and T4.19) and nine should be amended (T4.3, T4.4, T4.7, T4.10, T4.11, T4.12, T4.13, T4.16 and T4.17).
We observed that if trials funded by the HTA programme are to continue to qualify as one of the four cohorts of trials included in Djulbegovic et al.,96 then data will have to be extracted on the relevant fields.5 Dent and Raftery5 assessed treatment success and whether or not the results were compatible with equipoise using six categories: (1) statistically significant in favour of the new treatment; (2) statistically significant in favour of the control treatment; (3) true negative; (4) truly inconclusive; (5) inconclusive in favour of the new treatment; or (6) inconclusive in favour of the control treatment. Trials were classified by comparing the 95% confidence interval for the difference in primary outcome with the difference specified in the sample size calculation. The recent Cochrane Review used data extracted for this project and combined them with the only three other similar cohorts.96
Unanswered questions and future research
We analysed whether or not the planned analyses were carried out. We did not attempt to investigate whether or not the planned analyses were appropriate.
We compared individual components of the planned method of analysis with individual components reported in the monograph but did not calculate how often all of the components of the analysis plan matched those presented in the monograph. Again, this could be the subject of further work.
Small numbers constrained our analysis of trends in time. If the work continues, time trend analyses should be repeated and extended.
Further work could explore whether or not the amount of detail provided in the protocol on planned analyses is affected by the seniority of the statistician involved, including if he/she was a co-applicant.