Sample characteristics
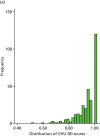
There were 643 observations across the five data collection time points from participants who were aged ≥ 5 years. These observations were randomised into groups A (n = 321) and B (n = 322). The longitudinal nature of the study meant that the number of missing data in the groups varied across the data collection points. After removing missing items, 279 observations with pairs of valid PedsQL and CHU-9D index scores in the first group formed the estimation sample, while the 284 observations in the second group formed the validation sample. The estimation and validation samples constitute the total mapping sample (n = 563). shows the distribution of the CHU-9D and PedsQL scores in the estimation and validation samples.
Distribution of CHU-9D and PedsQL scores in the estimation and validation samples. (a) Estimation sample, CHU-9D; (b) validation sample, CHU-9D; (c) estimation sample, PedsQL; and (d) validation sample, PedsQL.
reports the descriptive statistics for each sample at each time point. Overall, it seems that the randomisation ensured a balanced distribution of demographic characteristics between the estimation and the validation samples.
Demographic characteristics of estimation and validation sample by data collection time point
The mean CHU-9D utility score across all time points was 0.9374 (SD 0.0790) and 0.9409 (SD 0.0717) in the estimation and validation samples, respectively. The corresponding mean PedsQL score across all time points was 80.93 (SD 16.76) in the estimation sample and 80.31 (SD 17.79) in the validation sample. Within each sample, the mean PedsQL total score was lower than the mean CHU-9D utility score when both scores were standardised on a 100-point scale. Although both HRQoL measures were negatively skewed, the ceiling effect was more prominent with CHU-9D. Tables 23 and 24 in Appendix 3 summarise the CHU-9D responses for the estimation and validation samples across all data collection time points. Level 1 or ‘no problem’ always had the highest proportion of responses, hence the observed ceiling effect for the CHU-9D index score.
Performance and validation
Table 25 in Appendix 3 summarises the performance measures for all the model specifications, for both the estimation and the validation samples. Within the estimation sample, the models were able to reasonably predict the mean CHU-9D value (0.93742, SD 0.07898). Of the 18 models, 12 were able to predict the precise mean value by up to 1/10,000th of a QALY. The exceptions were the six tobit models. However, within the validation sample, the models were less able to predict the mean CHU-9D value (0.94094, SD 0.07174). The model GLM 2 had lowest mean predicted value (0.93409), whereas the model Tobit_3 had the highest mean predicted value (0.96575), giving a difference between the observed and predicted mean values of 0.0069 and 0.0245, respectively. These differences were below the threshold of 0.03, for which differences smaller than this level are considered to be a minimally important difference.70,71 A further observation was that some OLS models and all the tobit models had maximum predicted values beyond the upper limit of the CHU-9D utility scale (0.33–1.00). However, none of the models predicted a utility value below the lower limit of the CHU-9D utility scale.
Models were initially assessed in terms of their ability to predict the mean value in the estimation sample. All GLM and OLS models were consequently shortlisted for further comparison and progress to ‘step 2’. The two models (GLM 6 and OLS 3) that had the ‘best’ performance in terms of MAE, in both the estimation and validation samples, were selected for a final comparison: ‘step 3’. contains the model performance results for both of these models.
Model performance of the two best-fitting models
For the GLM, a logit transformation of the variable containing the CHU-9D utility scores was applied before the variable was used as the dependent in the prediction equation. As such, any predicted value from that equation will be a transformed value and, therefore, requires a back-transformation to estimate utility values. The information on the back-transformation step is as follows. Given that GLM 6 has a logit link, the CHU-9D utility values are calculated as shown below:
For the final models in step 3, in addition to assessing how accurately the models estimated the mean CHU-9D score in the validation sample, the distribution of the predicted score was also examined (see , Appendix 3). GLM 6 had a wide range of predicted CHU-9D scores compared with OLS 3.
Approximately 56% of the predicted values from GLM model 6 in the validation sample had absolute errors less than the minimally important difference value of 0.03; the corresponding values for the OLS model 3 was 53%. GLM model 6 remained the preferred model specification when the error threshold was extended to 0.05.
Although the prediction accuracy of the mean scores was similar in both models, the accuracy level was not uniform across the CHU-9D utility range, as shown in . The number of observations with utility score of < 0.7 was small; therefore, the comparison between the best two models was restricted to observations with higher utility values. GLM 6 was superior to OLS 3 in the estimation sample; however, in the validation sample there were diverging results. OLS 3 had a better prediction accuracy when utility values were > 0.8, but less than full health, while the GLM 6 was superior at predicting full health and utility values between 0.7 and 0.8. So, although OLS 3 had a better prediction accuracy in the validation sample overall, it was found to be only marginally better than GLM 6.
Distribution of errors by observed CHU-9D range
In summary, relative to GLM 6, OLS 3 lacked the ability to predict the wider range of CHU-9D values (0.7–1), and a higher proportion of its predicted values had absolute errors above the minimally important difference. Furthermore, it was less able to predict full health, which is particularly important for utility data that tend to have ceiling effects. Taking all these factors into account, the GLM 6 model was selected as the preferred model for mapping from PedsQL to CHU-9D. shows the coefficients for generating deterministic and probabilistic utility predictions using the GLM 6 model. Coefficients for OLS 3 have also been presented in situations in which this might be desired.
Coefficients for the two best-fitting models