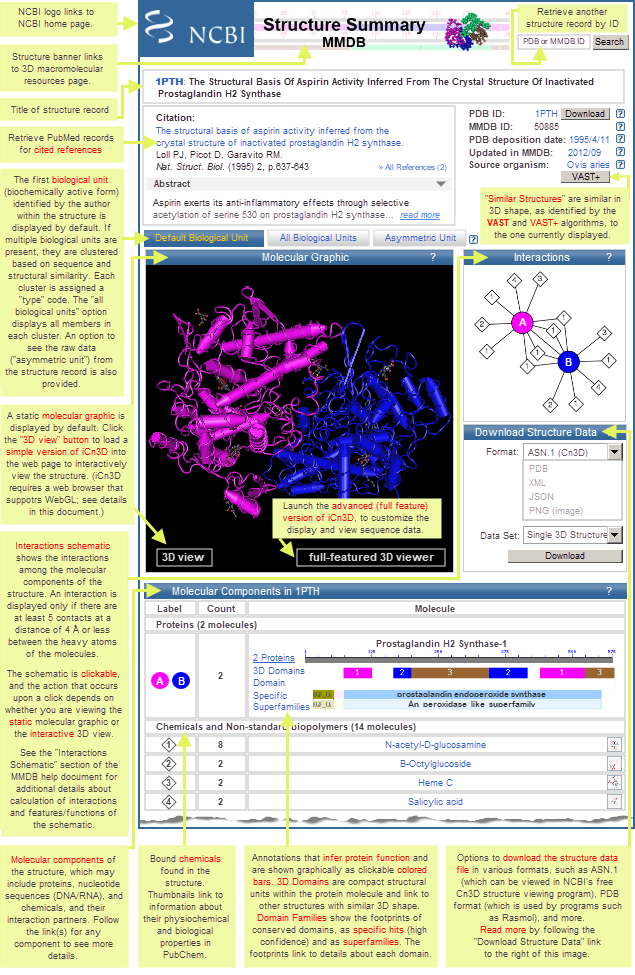
| allowable search terms | search methods | search fields | use of quotes | wild card * |
| basic search | search details | limits |
| advanced search | search builder | show index list | history | complex Boolean query | range query |
| link from other Entrez databases to 3D structures | links from protein sequence records to 3D structures |
 
This help document focuses on how to search for 3D macromolecular structures using the Entrez search system, which allows you to retrieve records that contain desired text terms. Additional search methods allow you to search the database with a query protein sequence or with the 3D coordinates for a newly resolved structure (using VAST tool); separate help documents exist for those search systems.
In the Entrez Structure search interface, you can retrieve structure records by searching for:
text terms (key words): A wide variety of text terms, such as names of proteins, bound chemicals, authors, and more can be used to search the Entrez Structure database. You can also search for other words that might be present in any of the other text containing search fields of a record.
Because terminology can vary across records, it can be helpful to include synonyms in your query, for example:
| |
suppressor OR inhibitor |
| |
NF1 OR neurofibromin OR neurofibromatosis |
| |
PTGS1 OR "prostaglandin endoperoxide synthase 1" (see note about use of quotes) |
It is also possible to search for a word stem by using an asterisk (*) as a wild card. For example, a search for inhibit* will retrieve records with terms such as inhibit, inhibited, inhibition, inhibitor, etc. The Entrez Help document provides additional information about truncating search terms in this way.
unique identifiers: Structure records can be retrieved by searching for their unique identifiers, in the form of an MMDB ID or PDB ID, or for the unique identifiers of their molecular components, such as protein sequence GI numbers or accession numbers, PubChem compound identifiers (CIDs) or substance identifiers (SIDs), or external registry names such as Enzyme Commission or chemical registry numbers (EC/RN numbers).
organism: To retrieve structure records for a specific organism or organism group, you can enter its common name (e.g., human) or scientific name (e.g., Homo sapiens), or other taxonomic node (e.g, Primates) in the Organism [orgn] search field. Note that some structure records contain protein or nucleotide sequences from more than one organism, and they will be retrieved if they contain one or more sequences from the organism or taxon specified in your query. If you specifically want to retrieve structure records that contain data from more than one source organism, simply enter the desired organism names with a Boolean AND (e.g., human[orgn] AND HIV1[orgn]).
database subset: It is possible to retrieve subsets of records that have certain attributes, such as structures generated by specific experimental methods or containing specific molecule types (protein, DNA, RNA) or bound chemicals.
Additionally, the Filter field allows you to limit a search to records that have links to another Entrez database of interest. For example, a search for structure_biosystems[filter] will retrieve structure records that have links to the NCBI BioSystems database; a search for structure_omim[filter] will retrieve structure records that have links to the Online Mendelian Inheritance in Man (OMIM) database; and a search for structure_biosystems[filter] AND structure_omim[filter] will retrieve the subset of records that have links to both of those databases.
and more... The Structure database can also be searched by terms that appear in any of the other search fields.
A variety of techniques can be used to search the database, offering varying degrees of control over your query. In some cases, they offer alternative ways of executing the same search (as is true for sample searches #4, #5, and #6 below), with each method offering different benefits. The search methods include:
| Method |
Description |
Example |
| Basic Search |
Just enter search terms without specifying search fields, other limits, or Boolean operators.
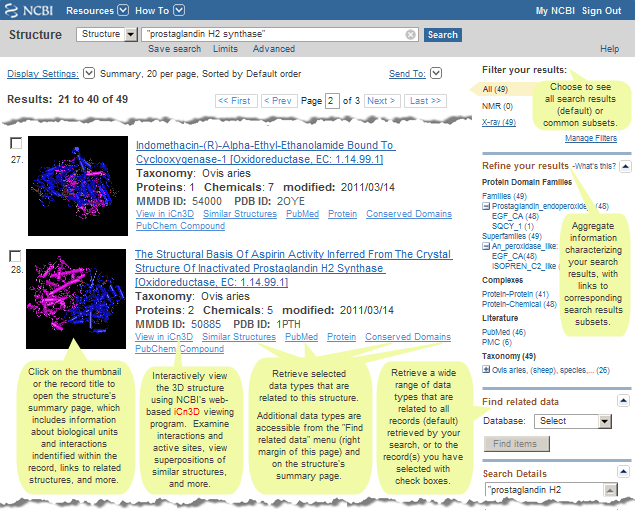
The "Search Details" box in the right margin of the search results page shows exactly how Entrez parsed and handled your query. If desired, you can edit the query in that box and press the "Search" button to run the modified query.
The "See more..." link a the bottom of the "Search Details" box opens a more detailed display:
- The Query Translation box shows the search strategy used to run the search
- To edit the search in the Query Translation box, add or delete terms and then click Search.
- Click URL to display the current search as a URL to bookmark for future use. Searches created using History numbers can not be saved using the URL feature.
- You may also save your search using My NCBI.
- The Result number link retrieves the documents found and displays them in a search results page.
- Translations details how each term was translated using Entrez's search rules and syntax for the database.
- User Query shows the search terms as you entered them in the search box and any syntax errors with the query.
|
Search #1:
human p53 tumor suppressor
will retrieve biosystems with those terms anywhere in the record.
Some of the structure records might not contain proteins or nucleotide sequences from human because we did not limit that search term to the Organism search field. In such cases, the term "human" might appear in a comment or some other field of the record.
Similarly, the term p53 tumor suppressor can appear anywhere in the record, and the words may or may not be adjacent to each other in a record, depending on how Entrez parsed the query (as shown in the Search Details for a given search). To force terms to be searched as a phrase, use quotes. To refine your search in other ways, use the Limits option or the Advanced Search methods described below.
|
Limits |
The Limits page allows you to restrict your search in various ways.
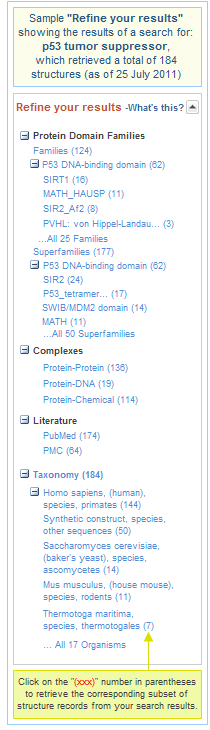
At a minimum, the Limits page displays the list of available search fields. You can do a separate search for each term or phrase in your query, as shown in sample Search #2 and #3 to the right, and select the desired search field for each one. (If desired, you can then combine the searches by using the Search Builder or History section of the Advanced Search page.)
For some databases, the Limits page also provides other commonly used options, as check boxes and/or pull-down menus, for restricting your search results to records with specific characteristics. These check boxes and pull-down menus generally represent a commonly used subset of the choices that are available from the Advanced Search page and are placed on the Limits page for easy access.
IMPORTANT NOTE: Once you have used a particular Limit, warning sign will appear near the top of your search results page that indicates which Limit(s) are currently in effect, for example:

Note that the Limit will remain in effect for all subsequent searches in the current database unless you change or remove that limit. In the illustrated example above, any search you do will be limited to the Titles of records, until you remove the limit.
|
Search #2:
On the Entrez Structure search page, click on the Limits link, select the Organism search field, and enter the following query:
human
and press "GO". That will retrieve only structure records that contain at least one molecular component (e.g., protein, DNA, or RNA) from human.
Search #3:
Open the Limits page again and clear your previous search. Change the search field selection to Title, enter the following query:
p53 tumor suppressor
and press "GO". That will retrieve only records containing those terms in the title of a structure record.
If desired, you can then combine the searches on the Advanced Search page, either by using the Search Builder, as shown in sample Search #4, or by using the History section of that page, as shown in sample Search #5.
|
| Advanced Search |
The Advanced Search page allows you to exercise greater control over your search, for example, by enabling you to:
- Build a search one step at a time.
- Browse the index of any search field and add term(s) of interest from the index to the active query box at the top of the page.
- View your search History and combine or subtract searches from each other.
As you build a query, either by using the Search Builder's pull-down menus, or by using the "Add" links in the "History" portion of the page to combine previous searches, the grey text box at the top of the page will display your current query.
You can also manually edit the current query by clicking the "Edit" link beneath the grey text box. That will allow you to type terms/search numbers/etc. directly into the box, add parentheses for nesting if desired, change Boolean operators, etc.
In addition, the following types of advanced searches can be entered in the query box of any Entrez search page (i.e., in the query box of the database's Home page, Limits page, or Advanced Search page):
|
Search Builder |
The "Search Builder" section of the Advanced Search page allows you to build your query step by step, adding a new search term and selecting a new search field at each step. It also allows you to browse the index of any search field to view the available terms.
To build a query:
(1) Select the Search Field of interest using the pull-down menu.
(2) Type a term(s) in the text box beside the search field menu. Or, use the "Show index list" link to see the index of the search field and select the desired term from the index. (tips on using the "Show Index List")
(3) Select the Boolean operator (AND, NOT, OR) that should precede the term when it is added to the active query at the top of the page.
Continue the above steps, as desired, to add more term/search field combinations to your query.
As you use the Search Builder, the grey text box at the top of the page will show your current query.
You can manually edit the current query by clicking the "Edit" link beneath the grey text box. That will allow you to type terms/search numbers/etc. directly into the box, add parentheses for nesting if desired, change Boolean operators, etc.
Press the Search button to display the records retrieved by your search (i.e., it displays the search results page).
Click on the "Add to history" link if you prefer to simply add the query to your search history and remain on the Advanced Search page, where you can continue building your query.
Tips on using the "Show Index List" function on the Advanced Search page:
The "Show Index List" function allows you to browse the index of any Search Field. If you select a search field and press the "Show Index" link without entering a term in the box, you will be taken to the top of the index. If you enter a term first, you will be taken to the part of the index that contains your term (or the closest alphabetical location, if your term is not present in the index).
The number of records that contain the term will appear in parentheses. You can also browse the index to explore the variety of terms available (for example, select "All Fields", enter "Huntington", and click on the "Show Index" link to see additional spellings and/or related terms, such as Huntington disease, Huntington's, Huntington's disease).

To select a range of terms from the index, use the Shift key while selecting the first and last term. Then use the AND, OR, or NOT buttons to add that group of terms to the active query.
To select multiple terms that do not fall within a continuous range from the index, use the Control key while selecting the terms of interest. Then use the AND, OR, or NOT buttons to add that group of terms to the active query.
Note: When multiple terms are selected from the index window, they are OR'ed together within parentheses and then appended to your query with whatever Boolean operator you have selected.
|
Search #4:
On the Entrez Structure search page, click on Advanced Search and build your search one step at a time:
(a) Using the first pull-down menu in Search Builder, select the Organism search field and enter the following query:
human
and select "AND" as the Boolean operator. That term/search field selection will automatically be displayed in the grey text box at the top of the page, which shows your current query.
(b) Using the second pull-down menu in Search Builder, select the Title search field and enter the following query:
p53 tumor suppressor
and select "AND" as the Boolean operator. That newest term/search field selection will automatically be added to the grey text box at the top of the page.
(c) Your query will now appear as:
human[Organism] AND p53 tumor suppressor[Title]
Press the Search button if you want to display the records retrieved by your search (i.e., it displays the search results page).
Or, click on the "Add to history" link if you prefer to just add the query to your search history and remain on the Advanced Search page, where you can continue building your query.
Note that this search will produce the same results as sample searches #5 and #6. It is simply executed in a different way. That is, you remain on a single query page (Advanced search) and can browse the index of any search field as you build your query one step at a time.
|
History |
The "History" section of the Advanced Search page displays the searches you have done in the current database.
You can combine or subtract searches from each other by entering the search numbers and the AND, OR, or NOT Boolean operators in the query box, for example: #2 AND #3. If the query contains several search numbers and Boolean operators, the Boolean operators are processed from left to right unless parentheses are used for nesting. If parentheses are used, the portions of the query in parentheses will be processed first, then the remaining Boolean operators will be processed from left to right.
Additional details about Search History:
- The Search History will be lost after 8 hours of inactivity. (To save a search indefinitely, click on the search # and select "Save in My NCBI.)
- Click "Clear History" to delete all searches from History.
- Entrez will move a search statement number to the top of the History if a new search is the same as a previous search.
- History search numbers may not be continuous because some numbers are assigned to intermediate processes, such as displaying a citation in another format.
- The maximum number of searches held in History is 100. Once the maximum number is reached, PubMed will remove the oldest search from the History to add the most current search.
- A separate Search History will be kept for each database, although the search statement numbers will be assigned sequentially for all databases.
- PubMed uses cookies to keep a history of your searches. For you to use this feature, your Web browser must be set to accept cookies.
- Database records that you have copied to the Clipboard are represented by the search number #0, which may be used in Boolean search statements. For example, to limit the records you have collected in the Clipboard to those from human, use the following search: #0 AND human[organism]. This does not change or replace the Clipboard contents.
|
Search #5:
Use the search numbers shown in the "History section" of the advanced search page to combine previous searches (for example, searches #2 and #3 shown above).
To do that, you can either:
Click on the "Edit" link beneath the grey text box and type in a search statement such as:
#2 AND #3
Or, instead of typing the search statement, use the "Add" link beside any search number in the "History" section of the Advanced Search page to add that search number into the grey text box.
That will retrieve only records that contain human in the Organism field (i.e., records that contain at least one molecular component -- protein, DNA, or RNA -- from human) and p53 tumor suppressor in the Title field. Compare the retrieval from this search with that of the sample basic search above.
(Note that your search numbers might be different from those shown here, if you did earlier searches in the Entrez system before trying these examples.)
|
| Complex Boolean |
Whether you are on the Basic search page (i.e., the database's home page), the Limits page, or the Advanced search page, you can:
Enter a search in command language, specifying your exact combination of desired search terms, search fields, and Boolean operators, as shown in the examples to the right. The syntax is:
term[field] BOOLEAN term[field] BOOLEAN term[field] etc.
Search Field names must be placed in square brackets [], and can be written as either the full name, for example, [Database], or as the corresponding search field abbreviation, for example, [db] (additional examples).
Boolean operators (AND, OR, NOT) must be written in UPPER CASE.
Boolean operators are processed from left to right unless parentheses are used for nesting. If parentheses are used, the portions of the query in parentheses will be processed first, then the remaining Boolean operators will be processed from left to right.
Boolean operators can also be used to combine or subtract searches from each other (i.e., to find the union, difference, or intersection of the data sets retrieved by various searches). To do this, use the Search History section of the Advanced Search page and simply enter the search numbers and desired Boolean operators in the query box.
For example, to identify the records that were retrieved by Search #2 of your search history, and also by Search #3, you could enter the following query:
#2 AND #3
To identify the records that were retrieved by Search #2 but not by Search #3, you could enter the following query:
#2 NOT #3
|
Search #6:
Simply enter all search terms and search fields as a single statement into the query box:
human[Organism] AND p53 tumor suppressor[Title]
Note that this search will produce the same results as sample searches #4 and #5, but it takes only a single step when entered directly into the search box as a Boolean query.
Search #7:
(prostaglandin H2 synthase OR prostaglandin endoperoxide synthase) NOT (primates[Organism] OR rodents[Organism])
This search will retrieve structure records that contain the terms prostaglandin H2 synthase OR prostaglandin endoperoxide synthase in any field, but that will not contain molecular components (proteins, DNA, RNA) from organisms in the taxonomic orders Primata or Rodentia.
|
| Range Search |
Range queries are constructed by specifying a lower and upper numerical value separated by a colon (:) to specify the range, followed by a search field name or abbreviation in square brackets, as shown in the examples to the right. You can insert a space on each side of the colon but that is not necessary; the search will work either way.
All dates and all 'counts' (such as residue counts, molecule counts, etc.) fields can be range queried. Apart from that, there are two additional fields that can be range queried: Resolution [RESO] in the Entrez Structure database, and MolWeight [MWT] in the Entrez Protein database (from which you can link to the Structure database).
Range queries on Resolutions [RESO] (in angstroms) must have the following format:
fromResolution : toResolution [RESO]
Range queries on MolecularWeights [MWT] (in daltons) must have the following format:
fromMolecularWeight : toMolecularWeight [MWT]
Note that searches by molecular weight are currently possible only in the Entrez Protein database. When you are searching that database, simply append "AND srcdb_pdb[prop]" to your query if you want to retrieve only the protein sequences that were derived from 3D structure records. For example:
_____:_____[molwt] AND srcdb_pdb[prop]
That will retrieve protein sequences that fall within the specified molecular weight range and that were derived from Protein Data Bank (PDB), the source database for 3D structure records. A specific example is provided in Search #10 to the right.
Range queries on Dates have a similar format:
FromDate : ToDate [fieldname]
Note: The FromDate and ToDate values can specify an exact date, a month, or a year, and are written in the format: YYYY/MM/DD, YYYY/MM, or YYYY. The search fields summary table includes the names and abbreviations for the various "date" fields.
Range queries on "counts" have the format:
FromCount : ToCount [fieldname]
Note: The FromCount and ToCount values are integers. The search fields summary table includes the names and abbreviations for the various "counts" fields.
|
Search #8:
001.50 : 001.75[Resolution]
This search of the Entrez Structure database will retrieve records that have a resolution between 1.50 to 1.75 Angstroms.
Search #9:
3 : 5[LigCount]
This search of the Entrez Structure database will retrieve structures that have three to five different types of ligands (bound chemicals) in their biological unit.
(A separate document describes how to find 3D protein structures bound to a specific chemical.)
Search #10:
Search the Entrez Protein database for:
4060 : 4075[Molwt] AND srcdb_pdb[prop]
That will retrieve protein sequences that have a molecular weight between 4060 and 4075 Daltons and that were derived from 3D structure records. Each protein sequence record will have a link to the corresonding structure record. Alternatively, you can select the "Find Related Data:Structure" option in the right margin of the search results page to retrieve the complete set of structure records that corresponds to the set of protein records you retrieved. (more details about protein → structure links...)
|
Additional details about search methods and options are provided in the: (1) PubMed help document (including information about temporarily saving records from your search results to the Clipboard); (2) My NCBI help document (including information about Saving search strategies and indefinitely saving records from your search results into your My NCBI Collections); and (3) general Entrez help document.
Search fields can be selected from pop-up menus on either the Limits or Advanced Search page, or can be typed directly in your query by surrounding field names with square brackets [], for example, [Organism] or [Orgn].* The Show index link on the Advanced Search page allows you to browse the index of each search field, where you can see the available terms, the number of records containing each term or phrase, as well as the syntax for entering values in search fields such as dates and EC/RN number.
The currently available fields include:
| Field name |
Abbreviation* |
Description |
Sample Search |
| All Fields |
[ALL] |
Searches the complete database record |
 "p53 tumor suppressor"[all]
"p53 tumor suppressor"[all]
will retrieve the structure records that contain the phrase "p53 tumor suppressor" in any field of the record.
(Compare these search results with those obtained by the sample Citation Abstract Field search, which will retrieve structure records containing that phrase in the abstract of an associated PubMed record, and with those obtained by the sample Title field search, which will retrieve records containing that phrase only in the title of an associated PubMed record.)
The quotes surrounding the search terms ensure they are searched as a phrase.** |
| Abstract |
[Abstract]
[ABS]
[ABST] |
The abstract (if available) of any PubMed reference linked to the structure. |
"p53 tumor suppressor"[abstract]
will retrieve the structure records that contain the phrase "p53 tumor suppressor" in the abstract of a PubMed reference associated with the structure.
(Compare these search results with those obtained by the sample All fields search, which will retrieve records containing that phrase in any field of the structure record, and with those obtained by the sample Title field search, which will retrieve records containing that phrase only in the structure title.)
The quotes surrounding the search terms ensure they are searched as a phrase.** |
| ASU Biopolymer Count |
[AsuBiopolymerCount]
[ABPC]
[ASUBPC] |
The total number of biopolymers (protein, DNA, and/or RNA molecules) in the raw data for the structure (i.e., in the "asymmetric unit," or "ASU").
(Compare with "BioUnit Biopolymer Count.")
This field can be queried for a single value or a range of values.
Note: Some structures may have a biopolymer count of zero, and can be retrieved by a search for:
0[AsuBiopolymerCount]
These can include structure records that contain only chemicals (such as peptide-like antiobiotics), peptide nucleic acids (PNAs), or protein or nucleotide sequences composed of ≥ 50% modified amino acids or nucleotides.
A separate file shows how to retrieve all available 3D structures for a specific type of molecule (protein, RNA, DNA, protein+chemical, etc.).
In addition, the "Retrieve 3D Structures that have..." blue buttons near the bottom of the 3D Macromolecular Structures resources page and Entrez Structure search page allow you to retrieve various molecule combinations (Protein+Chemical, RNA+Chemical, etc.) with a single click.
|
3 : 8 [ABPC] or
3[ABPC] : 8[ABPC] or
3 : 8[AsuBiopolymerCount]
etc.
will retrieve structure records that contain anywhere from three to eight biopolymers (protein, DNA, and/or RNA) in the raw data (asymmetric unit) for a structure.
As you can see by clicking on the Details folder tab after doing the search, each query above is translated to:
3[AsuBiopolymerCount] : 8[AsuBiopolymerCount]
(more about range searching...)
|
| ASU DNA Molecule Count |
[AsuDNAMoleculeCount]
[ADMC]
[ASUDMC] |
The number of DNA molecules in the raw data for the structure (i.e., in the "asymmetric unit," or "ASU").
(Compare with "BioUnit DNA Molecule Count.")
This field can be queried for a single value or a range of values.
A separate file shows how to retrieve all available 3D structures for a specific type of molecule (protein, RNA, DNA, protein+chemical, etc.).
In addition, the "Retrieve 3D Structures that have..." blue buttons near the bottom of the 3D Macromolecular Structures resources page and Entrez Structure search page allow you to retrieve various molecule combinations (Protein+Chemical, RNA+Chemical, etc.) with a single click. |
2 : 6 [ADMC] or
2[ADMC] : 6[ADMC] or
2 : 6[AsuDNAMoleculeCount]
etc.
will retrieve structure records that contain anywhere from two to six DNA molecules in the raw data (asymmetric unit) for a structure.
As you can see by clicking on the Details folder tab after doing the search, each query above is translated to:
2[AsuDNAMoleculeCount] : 6[AsuDNAMoleculeCount]
(more about range searching...)
|
| ASU Chemical Count |
[AsuLigCount]
[ALCT]
[ASULC] |
The number of different types of chemicals (not the total number of bound chemicals) in the raw data for the structure (i.e., in the "asymmetric unit," or "ASU"). The bound chemicals are sometimes referred to as "ligands," hence the abbreviation [AsuLigCount].
(Compare with "BioUnit Ligand Count.")
This field can be queried for a single value or a range of values.
A separate file shows how to find 3D structures bound to a specific chemical (e.g., aspirin).
In addition, the "Retrieve 3D Structures that have..." blue buttons near the bottom of the 3D Macromolecular Structures resources page and Entrez Structure search page allow you to retrieve various molecule combinations (Protein+Chemical, RNA+Chemical, etc.) with a single click. |
3 : 5 [ALCT] or
3[ALCT] : 5[ALCT] or
3 : 5[AsuLigCount]
will retrieve structures that have three to five different types of bound chemicals (ligands) in their "asymmetric unit" (ASU).
(A separate document describes how to find 3D protein structures bound to a specific chemical.)
|
| ASU Other Molecule Count |
[AsuOtherMoleculeCount]
[AOCT]
[ASUOMC] |
The number of molecules in the raw data for the structure (i.e., in the "asymmetric unit," or "ASU") that are not classified as a protein, DNA, RNA, or chemical, and therefore fall into the category of "other." (Compare ASU Other Molecule Count, described here, with "BioUnit Other Molecule Count.")
The "other" molecules are generally non-standard biopolymers. Examples include nucleotide or protein sequences that contain a large percentage of non-standard residues, long sugar chains (e.g., 1HPN), artificial constructs that contain a polypeptide backbone and nucleotide side chains (e.g., 1PUP), etc.
This field can be queried for a single value or a range of values.
Additional notes:
A separate file shows how to retrieve all available 3D structures for a specific type of molecule (protein, RNA, DNA, protein+chemical, etc.).
In addition, the "Retrieve 3D Structures that have..." blue buttons near the bottom of the 3D Macromolecular Structures resources page and Entrez Structure search page allow you to retrieve various molecule combinations (Protein+Chemical, RNA+Chemical, etc.) with a single click. |
4 : 6 [AOCT] or
4[AOCT] : 6[AOCT] or
4 : 6[AsuOtherMoleculeCount]
etc.
will retrieve structure records that contain anywhere from four to six protein molecules in the raw data (asymmetric unit) for a structure.
As you can see by clicking on the Details folder tab after doing the search, each query above is translated to:
4[AsuOtherMoleculeCount] : 6[AsuOtherMoleculeCount]
(more about range searching...)
|
| ASU Protein Molecule Count |
[AsuProteinMoleculeCount]
[APMC]
[ASUPMC] |
The number of protein molecules in the raw data for the structure (i.e., in the "asymmetric unit," or "ASU").
(Compare with "BioUnit Protein Molecule Count.")
This field can be queried for a single value or a range of values.
A separate file shows how to retrieve all available 3D structures for a specific type of molecule (protein, RNA, DNA, protein+chemical, etc.).
In addition, the "Retrieve 3D Structures that have..." blue buttons near the bottom of the 3D Macromolecular Structures resources page and Entrez Structure search page allow you to retrieve various molecule combinations (Protein+Chemical, RNA+Chemical, etc.) with a single click. |
4 : 6 [APMC] or
4[APMC] : 6[APMC] or
4 : 6[AsuProteinMoleculeCount]
etc.
will retrieve structure records that contain anywhere from four to six protein molecules in the raw data (asymmetric unit) for a structure.
As you can see by clicking on the Details folder tab after doing the search, each query above is translated to:
4[AsuProteinMoleculeCount] : 6[AsuProteinMoleculeCount]
(more about range searching...)
|
| ASU RNA Molecule Count |
[AsuRNAMoleculeCount]
[ARMC]
[ASURMC] |
The number of RNA molecules in the raw data for the structure (i.e., in the "asymmetric unit," or "ASU").
(Compare with "BioUnit RNA Molecule Count.")
This field can be queried for a single value or a range of values.
A separate file shows how to retrieve all available 3D structures for a specific type of molecule (protein, RNA, DNA, protein+chemical, etc.).
In addition, the "Retrieve 3D Structures that have..." blue buttons near the bottom of the 3D Macromolecular Structures resources page and Entrez Structure search page allow you to retrieve various molecule combinations (Protein+Chemical, RNA+Chemical, etc.) with a single click. |
6 : 10 [ARMC] or
6[ARMC] : 10[ARMC] or
6 : 10[AsuRNAMoleculeCount]
etc.
will retrieve structure records that contain anywhere from six to ten RNA molecules in the raw data (asymmetric unit) for a structure.
As you can see by clicking on the Details folder tab after doing the search, each query above is translated to:
6[AsuRNAMoleculeCount] : 10[AsuRNAMoleculeCount]
(more about range searching...)
|
| Author |
[AU]
[AUTH] |
The name of any author associated with any PubMed reference linked to the structure.
The format to search this field is: last name followed by a space and up to the first two initials followed by a space and a suffix abbreviation, if applicable, all without periods or a comma after the last name (e.g., o'neil kt[auth] OR o'connell jd 3r[auth]).
Entrez automatically truncates on an author's name to account for varying initials, e.g., o'neil k [au] will retrieve o'neil ka, o'neil kt, etc, in addition to o'neil k. To turn off this automatic truncation, enclose the author's name in double quotes, e.g., a search for "o'neil k"[auth] will retrieve just o'neil k.
Initials and suffixes may be omitted when searching, if desired. In that case, all authors with the specified last name will be retrieved, regardless of their initials.
|
pavletich np[au]
loll pj[auth]
will retrieve structure records by those authors |
| BioUnit Biopolymer Count |
[BiopolymerCount]
[BPC]
[BUBPC] |
The total number of biopolymers (protein, DNA, and/or RNA molecules) in the biological unit ("biounit") of the structure.
(Compare with "ASU Biopolymer Count.")
This field can be queried for a single value or a range of values.
Note: Some structures may have a biopolymer count of zero, and can be retrieved by a search for:
0[BiopolymerCount]
These can include structure records that contain only chemicals (such as peptide-like antiobiotics), peptide nucleic acids (PNAs), or protein or nucleotide sequences composed of ≥ 50% modified amino acids or nucleotides.
A separate file shows how to retrieve all available 3D structures for a specific type of molecule (protein, RNA, DNA, protein+chemical, etc.).
In addition, the "Retrieve 3D Structures that have..." blue buttons near the bottom of the 3D Macromolecular Structures resources page and Entrez Structure search page allow you to retrieve various molecule combinations (Protein+Chemical, RNA+Chemical, etc.) with a single click.
|
3 : 8 [BPC] or
3[BPC] : 8[BPC] or
3 : 8[BiopolymerCount]
etc.
will retrieve structure records that contain anywhere from three to eight biopolymers (protein, DNA, and/or RNA) in the biological unit ("biounit") of the structure.
As you can see by clicking on the Details folder tab after doing the search, each query above is translated to:
3[BiopolymerCount] : 8[BiopolymerCount]
(more about range searching...)
|
| BioUnit DNA Molecule Count |
[DNAMoleculeCount]
[DMC]
[BUDMC] |
The number of DNA molecules in the biological unit ("biounit") of the structure.
(Compare with "ASU DNA Molecule Count.")
This field can be queried for a single value or a range of values.
A separate file shows how to retrieve all available 3D structures for a specific type of molecule (protein, RNA, DNA, protein+chemical, etc.).
In addition, the "Retrieve 3D Structures that have..." blue buttons near the bottom of the 3D Macromolecular Structures resources page and Entrez Structure search page allow you to retrieve various molecule combinations (Protein+Chemical, RNA+Chemical, etc.) with a single click. |
2 : 6 [DMC] or
2[DMC] : 6[DMC] or
2 : 6[DNAMoleculeCount]
etc.
will retrieve structure records that contain anywhere from two to six DNA molecules in the biological unit ("biounit") of the structure.
As you can see by clicking on the Details folder tab after doing the search, each query above is translated to:
2[DNAMoleculeCount] : 6[DNAMoleculeCount]
(more about range searching...)
|
| BioUnit Chemical Count |
[LigCount]
[LCNT]
[BULC] |
The number of different types of bound chemicals (not the total number of bound chemicals) in the biological unit ("biounit") of the structure. The bound chemicals are sometimes referred to as "ligands," hence the abbreviation [LigCount].
(Compare with "ASU Chemical Count.")
This field can be queried for a single value or a range of values.
A separate file shows how to find 3D structures bound to a specific chemical (e.g., aspirin).
In addition, the "Retrieve 3D Structures that have..." blue buttons near the bottom of the 3D Macromolecular Structures resources page and Entrez Structure search page allow you to retrieve various molecule combinations (Protein+Chemical, RNA+Chemical, etc.) with a single click. |
3 : 5 [LCNT] or
3[LCNT] : 5[LCNT] or
3 : 5[LigCount]
will retrieve structures that have three to five different types of bound chemicals (ligands) in their biological unit.
(A separate document describes how to find 3D protein structures bound to a specific chemical.)
|
| BioUnit Molecular Weight |
[MolecularWeight]
[MW]
[MWT]
[MOLWT]
[MolWeight] |
The molecular weight of the structure's biological unit ("biounit") in KiloDaltons (kDa).
This field can be queried for a single value or a range of values.
|
|
| BioUnit Other Molecule Count |
[OtherMoleculeCount]
[OCNT]
[BUOMC] |
The number of molecules in the biological unit ("biounit") of the structure that are not classified as a protein, DNA, RNA, or chemical, and therefore fall into the category of "other." (Compare BioUnit Other Molecule Count, described here, with "ASU Other Molecule Count.")
The "other" molecules are generally non-standard biopolymers. Examples include nucleotide or protein sequences that contain a large percentage of non-standard residues, long sugar chains (e.g., 1HPN), artificial constructs that contain a polypeptide backbone and nucleotide side chains (e.g., 1PUP), etc.
This field can be queried for a single value or a range of values.
Additional notes:
A separate file shows how to retrieve all available 3D structures for a specific type of molecule (protein, RNA, DNA, protein+chemical, etc.).
In addition, the "Retrieve 3D Structures that have..." blue buttons near the bottom of the 3D Macromolecular Structures resources page and Entrez Structure search page allow you to retrieve various molecule combinations (Protein+Chemical, RNA+Chemical, etc.) with a single click. |
4 : 6 [OCNT] or
4[OCNT] : 6[OCNT] or
4 : 6[OtherMoleculeCount]
etc.
will retrieve structure records that contain anywhere from four to six protein molecules in the biological unit ("biounit") of the structure.
As you can see by clicking on the Details folder tab after doing the search, each query above is translated to:
4[OtherMoleculeCount] : 6[OtherMoleculeCount]
(more about range searching...)
|
| BioUnit Protein Molecule Count |
[ProteinMoleculeCount]
[PMC]
[BUPMC] |
The number of protein molecules in the biological unit ("biounit") of the structure.
(Compare with "ASU Protein Molecule Count.")
This field can be queried for a single value or a range of values.
A separate file shows how to retrieve all available 3D structures for a specific type of molecule (protein, RNA, DNA, protein+chemical, etc.).
In addition, the "Retrieve 3D Structures that have..." blue buttons near the bottom of the 3D Macromolecular Structures resources page and Entrez Structure search page allow you to retrieve various molecule combinations (Protein+Chemical, RNA+Chemical, etc.) with a single click. |
4 : 6 [PMC] or
4[PMC] : 6[PMC] or
4 : 6[ProteinMoleculeCount]
etc.
will retrieve structure records that contain anywhere from four to six protein molecules in the biological unit ("biounit") of the structure.
As you can see by clicking on the Details folder tab after doing the search, each query above is translated to:
4[ProteinMoleculeCount] : 6[ProteinMoleculeCount]
(more about range searching...)
|
| BioUnit RNA Molecule Count |
[RNAMoleculeCount]
[RMC]
[BURMC] |
The number of RNA molecules in the biological unit ("biounit") of the structure.
(Compare with "ASU RNA Molecule Count.")
This field can be queried for a single value or a range of values.
A separate file shows how to retrieve all available 3D structures for a specific type of molecule (protein, RNA, DNA, protein+chemical, etc.).
In addition, the "Retrieve 3D Structures that have..." blue buttons near the bottom of the 3D Macromolecular Structures resources page and Entrez Structure search page allow you to retrieve various molecule combinations (Protein+Chemical, RNA+Chemical, etc.) with a single click. |
6 : 10 [RMC] or
6[RMC] : 10[RMC] or
6 : 10[RNAMoleculeCount]
etc.
will retrieve structure records that contain anywhere from six to ten RNA molecules in the biological unit ("biounit") of the structure.
As you can see by clicking on the Details folder tab after doing the search, each query above is translated to:
6[RNAMoleculeCount] : 10[RNAMoleculeCount]
(more about range searching...)
|
| Chemical Name |
[LNAM]
[LIGN]
[LNAME] |
The name of a ligand (chemical) that is present in a 3D structure record. This was derived from the "HETNAM"* record of the PDB source file and represents the name that the author of the structure used for the chemical.
The same chemical might also be known by other names, which are indexed in the Chemical Synonyms search field. Use that field if you would like more comprehensive search results.
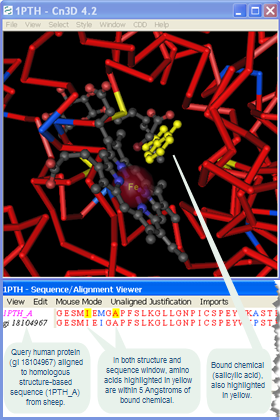
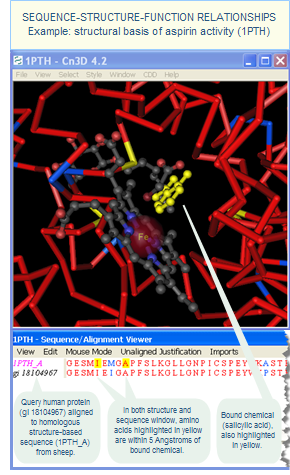
For example, the author of the 1PTH structure, used the term "2-HYDROXYBENZOIC ACID" as the chemical name for the aspirin molecule bound to Prostaglandin H2 Synthase. A search of the "Chemical Name" field for "2-Hydroxybenzoic Acid" will therefore retrieve 1PTH (along with other structures in which the authors used the same chemical name). However, if you search the "Chemical Name" field for a term other than the one the author used in the HETNAM record of their PDB source file, you will not retrieve those structures.
For broader search results, use the "Chemical Synonyms" field instead. That will allow you to enter any one of many names by which a chemical has been known. For example, you could search for either "2-Hydroxybenzoic Acid" or "salicylate" or "2-Carboxyphenol" (or another synonym) and you will retrieve all macromolecular structures that contain salicylic acid, regardless of the chemical name that the authors used for it.
A separate file provides additional tips on how to find 3D structures bound to a specific chemical (e.g., aspirin).
* Note: "HETNAM" is the PDB terminology for "heterogen name," which refers to any non-biopolymer that is present in a 3D structure record. The documentation about PDB file format provides more information about the various "records" (data fields), such as HETNAM, that are present in PDB source files.
|
2 hydroxybenzoic acid[LNAM]
will retrieve structure records in which the author used the term "2 hydroxybenzoic acid" as the name of the chemical present in the 3D structure.
Tip: To search for other names by which the chemical has been known, such as "salicylate" or "2-Carboxyphenol," use the Chemical Synonyms search field.
|
| Chemical Synonyms |
[ChemSyn]
[CSYN] |
The various names by which a given chemical structure has been known.
For example, the terms "salicylate," "2-Hydroxybenzoic acid," "o-hydroxybenzoic acid," "2-Carboxyphenol," "o-Carboxyphenol," "2-hydroxy(1-14c)benzoic acid," etc. have been used to refer to the chemical structure of salicylic acid. You can search the "Chemical Synonym" field for any of those terms in order to retrieve all of the 3D macromolecular structures that contain the chemical that is described in the corresponding PubChem Compound record (CID 338).
The chemical names in this search field represent the filtered synonyms from PubChem Compound records that correspond to the chemicals present in the 3D macromolecular structure records.
A separate file provides additional tips on how to find 3D structures bound to a specific chemical (e.g., aspirin).
|
salicylate[ChemSyn]
will retrieve 3D macromolecular structure records that contain the chemical shown in the PubChem Compound record for salicylic acid (CID 338), regardless of the chemical name that was used by the submitter of the 3D macromolecular structure.
This search, for example, will retrieve 1PTH structure (among others), even though the submitter of 1PTH used the term "2-Hydroxybenzoic Acid" instead of the term "salicylate" to refer to the chemical that is bound to Prostaglandin H2 Synthase.
|
| Conserved Domain Database Description |
See Conserved Domain Superfamily Description |
| Conserved Domain Description |
[CDDF]
[CDSUBDefline] |
Any term from the description of a conserved domain model.
Example: "sedolisin" is a term in the description of the NCBI-curated conserved domain model cd04056, which has the short name "Peptidases_S53," full title "Peptidase domain in the S53 family," and PSSMID 173788.
Note: A search of this field will retrieve 3D structures that contain at least one protein molecule annotated with a specific hit to a conserved domain model whose description includes your query term.
A separate help document provides additional information about conserved domains. |
sedolisin[CDDF]
will retrieve 3D structures that contain at least one protein molecule annotated with a specific hit to a conserved domain whose description includes the term "sedolisin."
(For example, it will retrieve 3D structures such as 1GT9: "Thermostable Serine-carboxyl Type Proteinase, Kumamolisin," which contains a protein molecule annotated with cd04056.)
|
| Conserved Domain PSSMID |
[CDID]
[CDSBID]
[CDSUBID] |
The position-specific scoring matrix (PSSM) identifier of a conserved domain that has been annotated as a specific hit on one or more protein molecules in a structure.
Example: "173788" is the PSSMID of the NCBI-curated conserved domain model cd04056, which has the short name "Peptidases_S53" and full title "Peptidase domain in the S53 family."
Note: A search of this field will retrieve 3D structures that contain at least one protein molecule annotated with a specific hit to aconserved domain model bearing the PSSMID of interest.
A separate help document provides additional information about conserved domains. |
173788[CDID]
will retrieve 3D structures that contain at least one protein molecule annotated with a specific hit to the conserved domain whose PSSMID is 173788.
|
| Conserved Domain Short Name |
[CDSN]
[CDSUBName] |
The short name of a conserved domain.
Example: "Peptidases_S53" is the short name of the NCBI-curated conserved domain model cd04056, which has the full title "Peptidase domain in the S53 family" and PSSMID 173788.
Note: A search of this field will retrieve 3D structures that contain at least one protein molecule annotated with a specific hit to a conserved domain model bearing the short name of interest.
For a more comprehensive search (for example, to retrieve structures annotated with any domain model that belongs to the Peptidases_S8_S53 Superfamily), please search the Conserved Domain Superfamily Title or Conserved Domain Superfamily Description field instead (using a term such as peptidase) for boader search results.
A separate help document provides additional information about conserved domains. |
Peptidases_S53[CDSN]
will retrieve 3D structures that contain at least one protein molecule annotated with a specific hit to a conserved domain model that the short name of "Peptidases_S53."
Note: Query term(s) are not case sensitive, so you can enter your search in upper case, lower case, or mixed case.
|
| Conserved Domain Title |
[CDDT]
[CDSUBTitle] |
The title of a conserved domain.
Example: "Peptidase domain in the S53 family" is the title of the NCBI-curated conserved domain model cd04056, which has the short name "Peptidases_S53"and PSSMID 173788.
Note: A search of this field will retrieve 3D structures that contain at least one protein that has been annotated with a specific hit to a conserved domain model bearing the title of interest.
A separate help document provides additional information about conserved domains. |
peptidase[CDDT]
will retrieve 3D structures that contain at least one protein molecule annotated with a specific hit to a conserved domain model that has the term "peptidase" in its title.
|
Conserved Domain Superfamily Description
[Note: this field currently appears as "Conserved Domain Database Description" in the search field menu of the Entrez Structure database] |
[SPDF]
[CDDSPDefline] |
Any term from the description of a conserved domain superfamily.
Example: "subtilisin" is a term in the description of the conserved domain superfamily cl10459, which has the short name "Peptidases_S8_S53 Superfamily," full title "Peptidase domain in the S8 and S53 families," and PSSMID 209143.
Note: A search of this field will retrieve 3D structures that contain at least one protein molecule annotated with a conserved domain superfamily whose description includes your query term.
A separate help document provides additional information about conserved domains. |
subtilisin[SPDF]
will retrieve 3D structures that contain at least one protein molecule annotated with a conserved domain superfamily whose description includes the term "subtilisin."
(For example, it will retrieve 3D structures such as 1GT9: "Thermostable Serine-carboxyl Type Proteinase, Kumamolisin," which contains a protein molecule annotated with cl10459.)
|
| Conserved Domain Superfamily PSSMID |
[SFID]
[CDSUPID] |
The position-specific scoring matrix (PSSM) identifier of a conserved domain superfamily that has been annotated on one or more protein molecules in a structure.
Example: "209143" is the PSSMID of the conserved domain superfamily cl10459, which has the short name "Peptidases_S8_S53 Superfamily" and full title "Peptidase domain in the S8 and S53 families."
Note: A search of this field will retrieve 3D structures that contain at least one protein molecule annotated with a conserved domain superfamily bearing the PSSMID of interest.
A separate help document provides additional information about conserved domains. |
209143[SFID]
will retrieve 3D structures that contain at least one protein molecule annotated with a conserved domain superfamily whose PSSMID is 209143.
|
| Conserved Domain Superfamily Short Name |
[SPFN]
[CDDSPName] |
The short name of a conserved domain superfamily.
Example: "Peptidases_S8_S53 Superfamily" is the short name of the conserved domain superfamily cl10459, which has the full title "Peptidase domain in the S8 and S53 families" and the PSSMID 209143."
Note: A search of this field will retrieve 3D structures that contain at least one protein molecule annotated with a conserved domain superfamily bearing the short name of interest.
A separate help document provides additional information about conserved domains. |
Peptidases_S8_S53[SPFN]
will retrieve 3D structures that contain at least one protein molecule annotated with a conserved domain superfamily that the short name of "Peptidases_S8_S53."
Note: Query term(s) are not case sensitive, so you can enter your search in upper case, lower case, or mixed case.
|
| Conserved Domain Superfamily Title |
[SPTL]
[CDDSUPT] |
The title of a conserved domain superfamily.
Example: "Peptidase domain in the S8 and S53 families" is the title of the conserved domain superfamily cl10459, which has the short name "Peptidases_S8_S53 Superfamily" and the PSSMID 209143."
Note: A search of this field will retrieve 3D structures that contain at least one protein molecule annotated with a conserved domain superfamily bearing the title of interest.
A separate help document provides additional information about conserved domains. |
peptidase[SPTL]
will retrieve 3D structures that contain at least one protein molecule annotated with a conserved domain superfamily that has the term "peptidase" in its title.
|
| DNA Name |
[DNAM]
[DNAME]
[DNAName] |
The name of an DNA molecule in a structure record. The names of nucleotide molecules, including DNA and RNA, are derived from the COMPND record of the PDB source file.
(The documentation about PDB file format provides more information about the various "records" (data fields) that are present in PDB source files.)
The DNA name often reflects the sequence of nucleotides in the molecule itself. |
|
| EC/RN Number |
[EC] |
The Enzyme Commission (EC) number of the PDB structure, representing the classification of an enzyme based on the chemical reactions it catalyzes. The EC number is extracted from the "COMPND" record (data field) of a PDB file.
This field can be queried with the wild-card (*) feature, for example:
3.2.1.114 [EC]
3.2.1.* [EC]
3.2.*.* [EC]
3.2.* [EC]
and so on. Note the queries 3.2.*.* [EC] and 3.2.* [EC] will return identical set of PDB structures, so the two queries are equivalent. |
3.2.1.114[EC]
will retrieve structures classified with that specific enzyme commission number.
3.2.1.*[EC]
3.2.*.*[EC]
3.2.*[EC]
use the wild card (*) to retrieve structure records that contain the digits specified, followed by any other digits.
You can click on the Details folder tab of a search results page to see exactly how a query was handled by the Entrez system.
|
| Experimental Method |
[EXP]
[EXPM] |
The experimental method used to characterize the protein structure. Most structures are resolved using X-ray crystallography or nuclear magnetic resonance (NMR) but additional methods also exist (e.g., electron microscopy).
To see the full list of experimental methods available, open the Advanced Search page, select the ExpMethod search field in the Search Builder section, and press the Show index link to browse the index of available terms.
|
x_ray[exp] or
"x ray"[exp]
will retrieve structures resolved by X-ray crystallography.
nmr[exp]
will retrieve structures resolved by nuclear magnetic resonance.
"electron microscopy"[exp]
will retrieve structures resolved by electron microscopy.
|
| Gene Description |
[GDSC]
[GeneDescription] |
The description of the gene that codes for a protein molecule present in the structure record.
(The gene description is the text that is present in the "summary" section of the corresponding Entrez Gene record.)
The association between the gene names and the protein molecules has been made using the method described under "Find related data."
|
"tumor suppressor"[GDSC]
will retrieve structure records that contain the protein product of any gene that contains the term "tumor suppressor" in the gene's description.
The quotes surrounding the search terms ensure they are searched as a phrase.**
|
| Gene Name |
[GN]
[GENE]
[GNAME]
[GeneName] |
The name of the gene that codes for a protein molecule present in the structure record.
Because a gene may be known by a variety of names, this search field includes the official symbol and the alternative ("also known as") gene symbols that are listed in the corresponding Entrez Gene record.
For example, the Entrez Gene record for the human tumor protein p53 is known by the following names:
Official Symbol: TP53
Also known as: P53; LFS1; TRP53
You can enter any of those terms in a search of the Gene Name field in order to retrieve structures that contain the protein product.
The association between the gene names and the protein molecules has been made using the method described under "Find related data."
|
TP53[GENE]
will retrieve structure records that contain the protein product of the TP53 (tumor protein p53) gene.
|
| Filter |
[FILT] |
The "Filter" search field allows you to narrow your retrieval to records that have certain attributes, such as record type (e.g., structures resolved using x-ray crystallography or NMR, which can also be retrieved via the ExpMethod field).
The "Filter" field also allows you to limit search results to structure records that have links to other Entrez databases of interest, as shown in the sample search to the right. A detailed explanation of each type of link is provided in the description of an Entrez search results page.
The Filter field can also be used to view current database statistics, by entering a search for All[Filt], as shown in the example in the next column.
|
nmr[filt]
will retrieve only that record type from the Structure database.
structure_pccompound[filt]
will retrieve the structure records that have associated data (i.e., bound chemicals) in the PubChem Compound database.
You can then open the "Display" menu near the top of the Structure search results page and select "Chemicals/PubChem Compound" to retrieve the PubChem records for bound chemicals that are present in the structures you have retrieved, or only for those whose checkboxes have been activated. (Conversely, it is possible to retrieve 3D structures that are bound to a specific chemical.)
all[filt]
will retrieve all of the structure database records, showing the total number retrieved. (Additional database statistics are available on the news page.)
|
| Journal |
[JOUR] |
The journal of the publication that reported the PDB structure findings. If more than one PubMed reference is associated with a structure record, the journal of each article has been indexed.
Journal names can be written as full names or abbreviations. To see the list of journals, open the Advanced Search page, select the "Journal" search field in the Search Builder section, and press the Show index link to browse the index of available terms.
|
Science[jour]
will retrieve structures published in the journal Science. |
| MMDB Entry Date |
[DDAT] |
The first date on which a particular MMDB ID appeared. This can represent the date on which a new Protein Data Bank structure record (i.e., a particular PDB accession) was first imported into MMDB, or the date on which a previously existing PDB record was significantly changed and therefore received a new MMDB ID.
The syntax for searching the field is YYYY/MM/DD, YYYY/MM, or YYYY. The colon (:) can be used to search for a range of dates, for example, YYYY/MM/DD:YYYY/MM/DD[MDAT].
Searches of this field will retrieve: (a) new structure records (PDB accessions) that were not previously in MMDB, and (b) PDB accessions that were previously in the database but that have changed in some significant way and have therefore received a new MMDB ID. For example, if the atoms in a previously available PDB data file were re-ordered during a PDB remediation the PDB accession will remain the same but it will receive a new MMDB ID and a new MMDBEntryDate.
|
2009[DDAT]
will retrieve structure records that were first imported into MMDB, or that have changed significantly, in the year 2009.
2009/01[DDAT]
will retrieve new structure records that were first imported into MMDB, or that have changed significantly, in the month of January 2009.
2009/01/10[DDAT] : 2009/01/25[DDAT]
will retrieve new structure records that were first imported into MMDB, or that have changed significantly, anytime between January 10, 2009 and January 25, 2009.
(more about range searching...) |
| MMDB ID |
[MMDBID]
[UID]
[ID] |
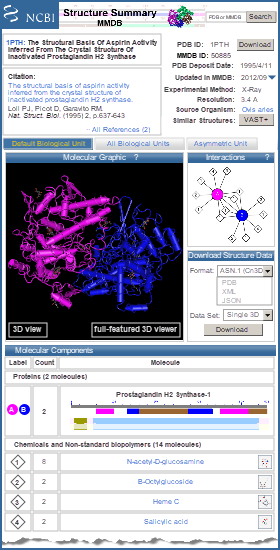
The unique identifier (MMDB ID) of the structure record in the Molecular Modeling Database (MMDB). It is an integer assigned consecutively to each structure record processed by NCBI. For example, 50885 is the MMDB ID for sheep prostaglandin H2 synthase. (The summary page for a structure record shows both of its identifiers: MMDB ID and corresponding PDB ID. The latter is searchable in the PDB Accession field.)
If you enter an integer as a query and do not specify a search field, the MMDB ID field will be searched by default.
Note: The MMDB ID assigned to a PDB accession can change if there have been significant changes to the data in a record. For example, if the atoms in a previously available PDB data file were re-ordered during a PDB remediation the PDB accession will remain the same but it will receive a new MMDB ID and a new MMDBEntryDate. Obsolete MMDB IDs (e.g., 6543) cannot be retrieved through the Entrez Structure search interface, even with direct searches of the UID field, because they are no longer indexed. However, those obsolete MMDB IDs can be retrieved from the archival copy of the database by using the "Direct Fetch via UID" option on the MMDB Search Methods page. |
50885[UID]
will retrieve the structure record whose unique identification number is 50885.
50885
will also retrieve that same structure record, because the MMDB ID field is searched by default for queries that are only a string of digits.
|
| MMDB Modify Date |
[MDAT] |
The date on which the structure record was last modified. If no modifications were made since the record was deposited into MMDB, then MMDBModifyDate will be the same as the MMDBEntryDate.
The syntax for searching the field is YYYY/MM/DD, YYYY/MM, or YYYY. The colon (:) can be used to search for a range of dates, for example, YYYY/MM/DD:YYYY/MM/DD[MDAT].
Note about this field: When PDB undergoes a database remediation, in which most or all PDB records are updated in some way, MMDB imports the complete set of updated records. This was the case when the PDB database underwent a September 2007 remediation. Because the complete revised PDB data set was loaded into MMDB at that time, the earliest available value in the MMDBModifyDate field is 2007. Similarly, the release of PDB Archive Version 3.15 in March 2009 resulted in changes to a large subset of records, which is reflected in an MMDB MDAT of 2009/07 for approximately 20,000 records. |
The following searches will retrieve updated structure records that were previously in MMDB but that have changed in some way, as well as new structure records that became available during the specified period of time:
2009[MDAT]
will retrieve the structure records that were updated and newly added to MMDB in the year 2009.
2009/01[MDAT]
will retrieve the structure records that were updated and newly added to MMDB in the month of January 2009.
2009/01/10[MDAT] : 2009/01/25[MDAT]
will retrieve structure records that were updated and newly added to MMDB from January 10, 2009 through January 25, 2009.
(more about range searching...)
|
| Number of PDB Records per Structure |
See PDB File Count |
| Oligomeric State |
[OL]
[OS]
[OLIG]
[OligomericState] |
A term representing the number of biopolymers (i.e., protein and nucleotide (RNA/DNA) molecule) in the structure's biological unit.
For example, this search field contains terms such as:
monomeric
dimeric
trimeric
tetrameric
pentameric
hexameric
octomeric
9-meric
10-meric
...
23-meric
...
60-meric
As noted in the section of this document that describes the procedures used to identify the biological unit, the oligomeric state is derived from the "REMARK 350" record of the PDB source file. (The documentation about PDB file format provides more information about the various "records" (data fields) that are present in PDB source files.)
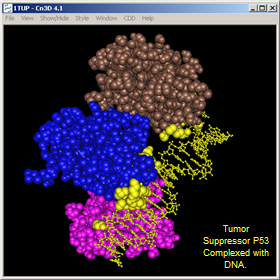
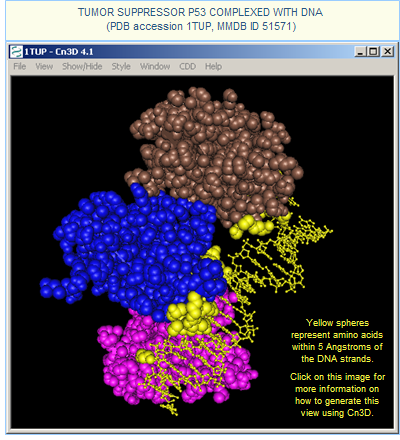
Also note that the oligomeric state of a structure might reflect its bound state. For example, the PDB source file for 1TUP: "Tumor Suppressor P53 Complexed With DNA" defines the oligomeric state as pentameric (a trimer protein complexed with a DNA double helix).
|
|
| Organism |
[ORGN] |
The source organism(s) of the protein and/or nucleotide molecules in the structure record. A common name (e.g., human), scientific name (e.g., Homo sapiens), or other taxonomic node (e.g, Primates or Primata) can be entered as a query.
If a structure record contains protein or nucleotide sequences from more than one organism (e.g., human AND HIV1), the record can be retrieved by searching for any one of the source organisms.
The summary page for an individual structure provides a list of the source organism(s). Each organism name links to the corresponding taxonomic information in the NCBI Taxonomy database, including the organism's Taxonomy ID (TaxID) and lineage. |
human[orgn]
will retrieve structures with at least one molecular component from human.
primates[orgn]
will retrieve structures with at least one molecular component from any species falling in the order Primata.
|
| Other Molecule Name |
[ONAM]
[ONAME]
[OtherMoleculeName] |
The name of a molecule -- other than a protein, DNA, RNA, or ligand -- that is present in a structure record. The name is derived from the COMPND record of the PDB source file and represents the term used by the author for the molecule.
(The documentation about PDB file format provides more information about the various "records" (data fields) that are present in PDB source files.) |
|
| PDB Accession |
[ACCN]
[PACC]
[PDBACC] |
The accession of number of the Protein Data Bank (PDB) record from which the MMDB record was derived, and is sometimes referred to as PDB ID. It is generally a four-character alphanumeric combination (e.g., 1PTH is the source record for MMDB ID 50885).
The PDB ID shown on an MMDB search results page opens the corresponding MMDB structure summary page.
The PDB ID on the structure summary page, in turn, links to the source record on the PDB web site.
The record identifiers section of a structure summary page also lists the corresponding MMDB ID, which is searchable in the UID field.
|
1PTH[pdbacc]
will retrieve the MMDB record for 1PTH, for sheep prostaglandin H2 synthase. |
| PDB Chemical Code |
[LigCode]
[LCOD]
[LIGC]
[LCODE] |
The 3-letter code of a ligand (bound chemical) in the PDB structure. For example, HEM is the ligand code for a heme group in a globin.
A separate file shows how to find 3D structures bound to a specific chemical (e.g., aspirin). |
|
| PDB Class |
[PCLA]
[PCLS] |
The classification of the PDB structure, as provided by the submitter in their data file.
|
|
| PDB Comment |
[PCOM]
[PCMT] |
The more detailed description of the PDB structure. This field contains text from the REMARK records in the PDB data file.
|
|
| PDB Deposit Date |
[PDDAT] |
The earliest date that Protein Data Bank associates with an accession, generally representing the date on which the record was submitted to the PDB.
The syntax for searching the field is YYYY/MM/DD, YYYY/MM, or YYYY. The colon (:) can be used to search for a range of dates, for example, YYYY/MM/DD:YYYY/MM/DD[MDAT].
(Note that the PDB Deposit Date is not necessarily the date on which the record became publicly available, and may be significantly different from the release date if submitters requested their data remain confidential until publication.) |
2009[PDDAT]
will retrieve the structure records that were submitted to PDB in the year 2009.
2009/01[PDDAT]
will retrieve the structure records that were submitted to PDB in January 2009.
2009/01/10[PDDAT] : 2009/01/25[PDDAT]
will retrieve structure records that were submitted to PDB anytime between January 10, 2009 and January 25, 2009.
(more about range searching...)
|
| PDB Description |
[PDSC]
[PDES] |
A brief description of the PDB structure.
|
|
PDB File Count
(Number of PDB records per structure) |
[PdbFileCount]
[FC]
[PDBCNT] |
The number of PDB records that have been combined to reconstitute the originally submitted structure.
Most structures occupy a single PDB record.
Very large structures have been split by PDB into multiple records, and the MMDB data processing procedures merge the PDB split files back into a single structure record.
|
2[FC] : 1000[FC]
will retrieve all structures that have a PDB file count of 2 or more (in this search example, the upper limit was arbitrarily set at 1000).
In other words, the search will retrieve all merged files from MMDB.
|
| PDB Source |
[PSRC]
[PSOU] |
The source organism of each protein and/or nucleotide molecule, as noted in the original PDB data file.
Note: During MMDB data processing, the source organism names in the PDB data file are compared against the organism names in the NCBI Taxonomy database. If there is a difference, the MMDB version of the data file will contain the organism name from the NCBI taxonomy database (based on the results of a BLAST search), and that name will be searchable in the Organism field. However, the source organism name noted in the original PDB file will still also be searchable via the PDBSource field.
|
|
| Protein Name |
[PNAM]
[PNAME]
[ProteinName] |
The name of a protein molecule in a structure record, derived from the COMPND record of the PDB source file. This represents the term used by the author for the protein.
(The documentation about PDB file format provides more information about the various "records" (data fields) that are present in PDB source files.) |
|
| Resolution |
[RES]
[RESL]
[RESO] |
The resolution (in Angstroms) of a protein structure resolved by diffraction or electron microscopy. This field can be queried for a single value or a range of values.
|
001.50 : 001.75[Resolution]
will retrieve records that have a resolution between 1.50 to 1.75 Angstroms.
As you can see by clicking on the Details folder tab after doing the search, each query above is translated to:
001.50[Resolution] : 001.75[Resolution]
(more about range searching...)
|
| RNA Name |
[RNAM]
[RNAME]
[RNAName] |
The name of an RNA molecule in a structure record. The names of nucleotide molecules, including DNA and RNA, are derived from the COMPND record of the PDB source file.
(The documentation about PDB file format provides more information about the various "records" (data fields) that are present in PDB source files.)
The RNA name often reflects the sequence of nucleotides in the molecule itself. |
|
| Title |
[Title]
[TITL] |
The title of the publication(s) that reported the PDB structure findings. If more than one PubMed reference is associated with a structure record, the title of each article has been indexed.
|
"p53 tumor suppressor"[TITL]
will retrieve structure records with that phrase in the title.
(Compare these search results with those obtained by the sample All Fields search, which will retrieve structure records containing that phrase anywhere in the record, and those obtained by the sample Citation Abstract Field search, which will retrieve structure records containing that phrase in the abstract of an associated PubMed record.)
The quotes surrounding the search terms ensure they are searched as a phrase.** |
* In a query, the field name may be typed as the full name or abbreviation, and may be in upper, lower, or mixed case. If more than one abbreviation is shown, any one of them can be used. The field name must be surrounded by square brackets []. A space between the search term and the field specifier is optional. If desired, surround a phrase with quotes to force an adjacency search. For example, the sample queries below will work equally:
"p53 tumor suppressor"[TI]
"p53 tumor suppressor"[TITL]
"p53 tumor suppressor" [TITL]
"p53 tumor suppressor" [titl]
"p53 tumor suppressor"[Title]
** The quotes surrounding the query terms in some of the sample searches force the terms to be searched as a phrase. If quotes are not used, the Entrez system may still recognize and handle the terms as a phrase, if they are present in a phrase dictionary used by the search engine. If the terms are not present in the phrase dictionary and are not surrounded by quotes, Entrez will insert a Boolean AND between the terms; in that case, they may or may not appear adjacent to each other in the retrieved records. The "Details" folder tab on a search results page will show you exactly how the Entrez system parsed your query. More search tips are provided in the PubMed help document and Entrez help document.
It is also possible to search for a word stem by using an asterisk (*) as a wild card; for example, inhibit* will retrieve records with terms such as inhibit, inhibited, inhibition, inhibitor, etc. The Entrez Help document provides additional information about truncating search terms in this way.
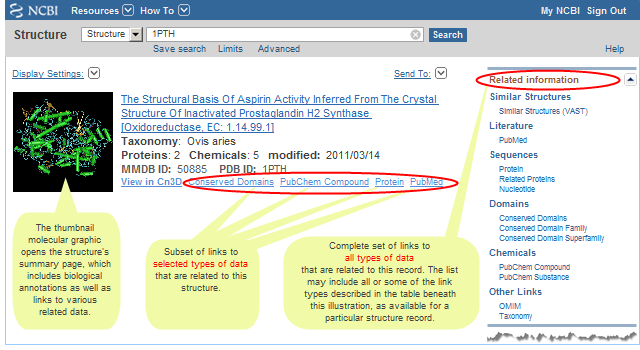
The Entrez databases to which structure records have been linked (via the data processing pipeline) generally have reciprocal links from their records back to the corresponding Structure database records.
Therefore, if you start your search in an Entrez database other than Structure, you can view the "Related Information" menu in the right hand margin of any record you have retrieved to see if it has links to associated information in the Structure database, as shown in the illustrated example below.
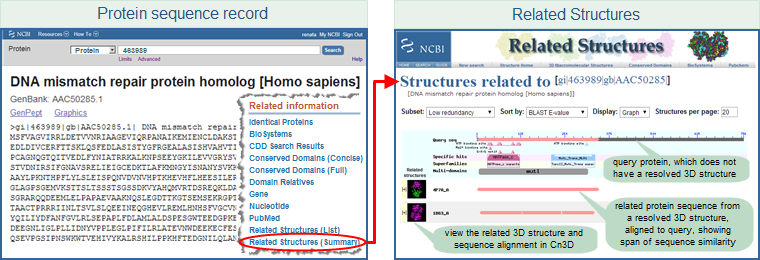
Additional, more detailed illustrated examples show how to link from a gene record or protein sequence to "related structures", and from a PubChem record to "protein structures" that are bound to the chemical of interest.
Alternatively, you can use the "Find Related Data" menu in the right hand margin of an Entrez search results page (in whatever database you have chosen to search) and select "Structure" to view the associated structure records for all items (default) displayed on the search results page or for those you have selected using their checkboxes.
| Additional note about links from Entrez Protein sequence records to structure records: |
Protein sequence records can have a link to 3D structure record depending upon the data available for a particular protein sequence:
- Structure - Protein sequence records that have a direct association with the structure record because at least one of the following is true: (a) the protein sequence record was derived directly from a 3D structure record (as described in MMDB data processing); (b) the accession number of the protein sequence record was listed in the DBREF record of the PDB source file; (c) the protein accession listed in the DBREF record of the PDB source file is also found in an Entrez Gene record, and that Gene record also has links to other protein accession(s); in such a case, all of the protein accessions in the Entrez Gene record will have "Structure" links (and will show a thumbnail image of a corresponding 3D structure in their protein sequence record display); or (d) the protein is identical in composition and sequence length to any of the proteins noted in (a), (b), or (c).
As of February 2020, approximately 0.6% of the 800+ million sequence records in Entrez Protein have a direct "Structure" link, because they were derived from 3D structure records or have another type of direct association with a 3D structure.
You can BLAST the protein sequence against the PDB (structure) database and adjust the algorithm parameters to decrease the stringency of the search, if desired.
|
|



 As noted in the page on
As noted in the page on